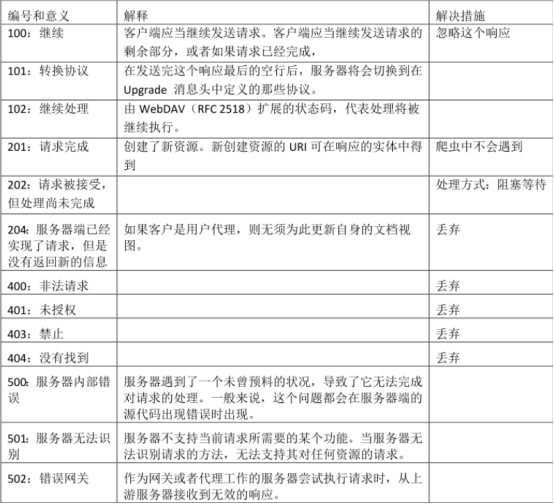
����Python�������ݲɼ�����
ժ Ҫ
���ż���������IJ��Ϸ�չ���µı�����Բ�����Python��Html�������е�ٮٮ�ߡ���Ƚ������ռ��ĸ�����(Java,C���ԣ��ȣ�Python���Ÿ���ʵ�õ�ģ��Ϳ⣬��Ȼ�����˵ײ��ԣ���ȴ���ӷ������ڿ���С����Ŀ�����⣬HtmlҲ�Ѿ����ձ�������վǰ�ˣ�������Ե����Խ��CSS�ḻ����ҳ���ݺ���ʽ��ij��������Ҳ�ٽ��˸������Ի��ĵ�������ϵͳ�ķ�չ�����ĵ�����������ʽ����Python���Ա�д��,ͨ����Htmlץȡ�ӹ������ݿ��ӻ�,�Լ��������ת�Ƶ����ϣ������ŵ�������չԽ�����ձ������ٵķǷ�Ұ������ó�ס�
�������ȶԼ��������Եķ�չ��������Python��Html�����ơ����������Լ����ܽ��н��ܡ�������ؽ��ܿ���ʵ�ּ�������ϷǷ�Ұ������ó���������ƺ�ʵ�֡�������Ҫ��������ģ��:URL������Htmlץȡ�����������Python�Ŀ����������߷ֱ���OS X��PyChram CE����Ҫ������Python�е�Urllib2��beautifulsoupģ�顣
���յij������ʵ�ֶ�ָ����վ��ָ���ؼ���ץȡָ�����ݣ��������ݵ����أ��Ա����ٺͼ�⡣
�عؼ��֣�Python��HTML�����棻�Ƿ�Ұ������ó��
Python-Based"IIlegalwildlifetrade"Spider
Electronics & Information Technology Program 11-1
Abstract
With the continuous development of computer technology, the new programming language after
another, Python, Html is the one of the best. Compared to the early popularity of high-level language (Java,C language),etc., Python has a more practical modules and libraries, although at the expense of the
underlying property, but it is more convenient for the development of small-scale projects. In addition,Html has also been widely used web front end, feature rich CSS markup language binding of web contentand form, in a sense also promotedthe development of a more user-friendly e-commerce system. Inthispaper, based on the official web crawler written in Python, Html crawling through the data visualizationprocess to monitor the gradual shift from offline to online, and with the development of electronic
commerce more simple universal untraceable illegal wildlife trade.
Firstly, the development of the calculator language, especially Python and Html advantages, basicconcepts and performance are introduced. The last focuses on the design and implementation can beachieved illegal wildlife trade on the reptile detection network. Program includes three modules: URL
parsing, Html capture, data visualization output. Python development environment and tools are OS X andPyChram CE, mainlycall in Python Urllib2, re and os module.
The final program can be specified site designated keyword to crawl the specified content, and outputin PC,inorder totrack and detect.
Key words: Python;Html;spider;llegal wildlife trade
Ŀ ¼
ժ Ҫ 1
Python-Based "I11ega1 wildlife trade�� Spider 2
һ �� �� 2
1.1 ��ҵ��Ʊ�����Ŀ�� 5
1.2 �������о�״�� 5
1.3 ���Ľṹ������ 5
�� ��ؼ������� 2
2.1 Python ���� 5
2.1.1 Python �����IJ����ͷ�չ��ʷ 6
2.1.2 Python ������ԭ�� 6
2.1.3 Python ��������ɫ 6
2.1.4 Python ������ȱ�� 6
2.2 URL 5
2.2.1 URL�Ķ��� 6
2.2.2 URL��URL�ĶԱȺ;��� 6
2.2.3 URL��� 6
2.3 Html 5
2.3.1 ���� 6
2.3.2 Html ԭ�� 6
2.3.3 Html �ص� 6
2.4�������� 5
2.4.1 Chrome 6
2.4.2 PycharmCE 6
2.4.3�ն� 6
�� ��Ŀ������� 2
3.1 ��������� 5
3.2 ��Ҫץȡ������ 5
3.3 ������� 5
�� ��Ŀ������ʵ�� 2
4.1����ģ�� 5
4.1.1 Ŀ����վ URL 6
4.1.2 Urillib2ģ�� 6
4.1.3 αװ 6
4.2ץȡģ�� 5
4.2.1 URL��Html 6
4.2.2 Beautiful Soup�� 6
4.2.3ץȡ���� 6
4.3���ģ�� 5
4.4������ 5
�� ��Ŀ���� 2
5.1 ץȡ���������� 5
5.2��ʾ���������� 5
5.3�������Ӳ��� 5
�� ���� 2
6.1�ջ���ɳ� 5
6.2������չ�� 5
��л 2
����� 2
һ �� ��
1.1��ҵ��Ʊ�����Ŀ��
��Щ�꣬�����ԡ��Ա���Ϊ�ĵ������������ٷ�չ��Խ��Խ������½������������ϣ����оͰ����Ƿ�Ұ��������Ʒó�ס������Ľ������ô����ķǷ�Ұ������ó�׳�Ϊ���ܣ�������չʾ��ʽ�ͱ�ݵĽ���ʽ��������������صĽ���Խ�����٣������Ϣ�ķ����븴��Ҳ�ý�ͨ�������鿴��ر��Խ�����ѡ�
��֮��Ӧ�����������漼���ķ�չ������google���ٶȡ���Ȼ�����е���ϢԽ��Խ�࣬Խ��Խ���ӣ���������ȴ�������ijһ���ؼ��ʶ�ȫ��������Ч���������������dz���ļ�����Ļһ�㶼�������������Ӵ����������������ʾ�Ľ����ȫ���������������Ž⣬������������Ч�����������վ��Թؼ��ʵ����������ң���������Ϊ�˽�Լ�����ٶȣ���ʹ�ñȽϵײ�ĸ����Ա�д���Ӵ��Ҹ��ӣ������ǺܺõIJο�����
һ������������Խ����Ⱶ�Ұ������ó�ף�Խ��Խ��Ľ���ʹ�úڻ����ر����д��- -ЩС����վ���γ��ȶ��Ĺ�Ӧ���ͽ���Ȧ����һ�� ���������漼����Ȼ��չѸ��ȴ��������Եļ�⣬���ϱ仯�ĺڻ�����վС���Եĸ��Ÿ�������ץȡ��Ϣ��������Խ�����ѡ�
��������������ʹ�������������������������صĽ�����һ���൱������ѡ��ͬ���������棬���������һ���Զ���ȡ��ҳ�ij����Զ�����Ե���ҳ�����е��ض����ݣ�������Ч��ץȡ����������Ʊ����ڱ��أ�����ʹ�á����ң������ڴ�ͳ����������棬��ѡ��ʹ��Python .����д���档��ͬ�ڴ�ͳ������(C��Java ��)��Python ��Լ��������С����Ŀ����ḻ��ģ������õļ�����Ҳ�������Ϊ��д������������ѡ��֮--��
1.2�������о�״��
����.�������ᵽ�ģ����������������бȽ��ձ顣Ŀǰ���ֱȽϳ��õ�����ʵ�ֲ���:������ȵ��������Repetitive �������������������������������������,���и��ݸ����۽��п���Webҳ����������,��������������Web��ģ�ij����������;����������ȡ�ҳ�浼�������������ȷ���,���ƴӳ������ز���ص�Webҳ��ѡ�������г���ȵȡ���ʵ��Google�IJ������������ǻ���Python�ģ�������Python���������ƣ���������Ϊһ-��ճ�ϼ�����������Ա�д���ں����С�
���⣬��������Ƿ�Ұ������ó�ļ�ز���������ҵ�����Լ����Ϊ���ӺͶ��ص�С������,������ص���ҵ������ع�������������WWF��֯�����ij�Ա��������ѧ��Ϊ������û����ص�רҵ��Ա������ؿ�����
1.3���Ľṹ������
ȫ�Ľ����˻���Python�����������ȷ���������ʵ��Ч���Ĺ��̣�������������:
(1)��һ��������Ҫ˵�����α�ҵ�����Ŀ�ı�����Ŀ�ģ������������о���״�Լ��������ĵĽṹ��
(2)�ڶ�����ؼ���������Ҫ˵�����α�ҵ�����Ŀ�漰����������ԺͶ�Ӧ�Ĺ��߰���PythonHtml��URL ��,�Լ���صĿ�������Chrome��PycharmCE��
(3)��������Ŀ�����������Ҫ˵�����α�ҵ�����Ŀ�뷨���͵Ĺ��̺ͽ�������˼·
(4)��������Ŀ������ʵ�֣���Ҫ�ǽ���������������ʵ�Ĺ��̣����ʵ��˵��������
(5)��������Ŀ������Ҫ˵������ʵ�ʱ�̹����в��Գ�����ʱ�Ľ��������
(6)�����·��ܽ�������Ŀ���ջ��벻�㡣
(7)����Ǹ�л�Ͳο����ϡ�
�� ��ؼ�������
2.1 Python����
2.1.1 Python���ԵIJ����ͷ�չ��ʷ
Python�Ĵ�ʼ��ΪGuido van Rossum��1989 ��ʥ�����ڼ䣬�ڰ�ķ˹�ص���Guido Ϊ�˴�ʥ���ڵ���Ȥ�����Ŀ���һ���µĽű����ͳ�����ΪABC���Ե�һ�ּ̳С�֮����ѡ��Python (����Ӣ���㲥��˾�Ľ�Ŀ�����߷�����Ϸ��)��Ϊ��������֡�
ABC����Guido�μ���Ƶ�һ�ֽ�ѧ���ԡ���Guido���˿�����ABC�������Էdz�������ǿ����ר��Ϊ��רҵ����Ա��Ƶġ�����ABC���Բ�û�гɹ�������ԭ��Guido��Ϊ�Ƿǿ�������ɵġ�Guido������Python�б�����һ-����ͬʱ��������ʵ����ABC�����ֹ���δ��ʵ�ֵĶ�������������Python ��Guido���е����ˡ�����˵Python �Ǵ�ABC��չ��������Ҫ�ܵ���Modula-3(��һ���൱������ǿ�������,ΪС����������Ƶ�)��Ӱ�졣���ҽ����Unix shell��C��ϰ�ߡ�Python���ԵĴ�����Guido van Rossum�Ǹ���Ӣ���㲥��˾�Ľ�Ŀ�����߷�����Ϸ������������ԵIJ����������ر�ϲ���߲������ǵij���������������ʳ��
Python�Ѿ���Ϊ���ܻ�ӭ�ij����������֮һһ��2011 ��1�£�����TIOBE����������а���Ϊ
2010������ԡ��Դ�2004���Ժ�python ��ʹ�����dz�����������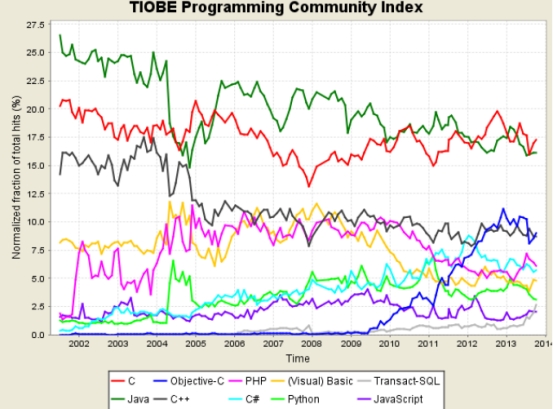
ͼ2.1�����������[ ]�̶�����2011
Fig.2.1 Hot Computer Language in 2011
����Python���Եļ�ࡢ���Լ�����չ�ԣ��ڹ�����Python����ѧ������о������������࣬- -Щ֪����ѧ�Ѿ�����Python���ڳ�����ƿγ̡����翨�ͻ�÷¡��ѧ�ı�̻�������ʡ��IѧԺ�ļ������ѧ����̵��۾�ʹ��Python���Խ��ڡ����⣬Python���Լ����ڶ����չ�������ɵĿ�������ʮ���ʺϹ��̼�����������Ա����ʵ�����ݡ�����ͼ��������������ѧ����Ӧ�ó���
2.1.2 Python���Ե�ԭ��
Python���ԵĻ���ԭ�����Ը���ΪPython�ȰѴ���(.py �ļ�)������ֽ��룬�����ֽ����������Ȼ�������- -��- -��ִ���ֽ���ָ��Ӷ���ɳ����ִ�С���ϸ��������:
(1)�ֽ�����Python̓����������Ӧ����PyCodeObject����.pyc �ļ����ֽ����ڴ����ϵı�����ʽ��
(2 )pyc�ļ�PyCodeObject����Ĵ���ʱ����ģ����ص�ʱ��import Python test.py ���test.py���б�����ֽ��벢����ִ�У����Dz�������test.pyc.���test.py����������ģ����import util,Python���utilpy���б�����ֽ��룬����util.pyc,Ȼ����ֽ������ִ�С����������test.pyc,���ǿ���ʹ��Python����ģ��py_ compile�����롣����ģ��ʱ�����ͬʱ����.��y��.pyc��Python�᳢��ʹ��.pyc�����.pyc�ı���ʱ������.py����ʱ�䣬�����±���.py������.pyc��
(3) PyCodeObject�� Python ����ı���������PyCodeObject ����
(4) pyc�ļ���ʽ������ģ��ʱ��ģ���Ӧ��PyCodeObject����д��.pyc�ļ�
(5)�����ֽ��룬Python�ṩ�����ú���compile���Ա���Python����Ͳ鿴
(7)����ָ������
(8)ִ���ֽ���
2.1.3 Python���Ե���ɫ
����: Python ��һ-�ִ���������˼������ԣ������Ŷ����ơ����õ��Ķ����ò�����Ϸ��PythonΪα���롣��ʹ���ܹ�רע�ڽ�����������ȥ���������Ա�����
��ѧ��:����ͬ�㼴��������һ����Python �����������֡�-�� ��ǰ���Ѿ��ᵽ�ˣ�Python�м���������-���棬Python ��ȻҲ���ϸ�ĸ�ʽҪ����Ƚ����������Լ������Ժ��Բ��ơ�
��Դ��: Python ��FLOSS (����/����Դ������)֮һ����˵����������ɵط�����������Ŀ������Ķ�����Դ���롢�������Ķ���������һ- ���������µ����������С�FLOSS �ǻ���һ���������֪ʶ�ĸ������ΪʲôPython��������ԭ��֮һ-- �� ����- -Ⱥϣ������һ�����������Python���˴��첢�����Ľ��ŵġ�
�߲�����:������Python���Ա�д�����ʱ�������迼��������ι�����ij���ʹ�õ��ڴ�һ��ĵײ�ϸ�ڡ�
����ֲ��:�������Ŀ�Դ���ʣ�Python �Ѿ�����ֲ������ƽ̨��( �����Ķ�ʹ���ܹ������ڲ�ͬƽ̨.��)�������С�ĵر���ʹ��������ϵͳ�����ԣ���ô�������Python���������ľͿ����������κ�ƽ̨.�������С���Щƽ̨����Linux. Windows. FreeBSD�� Macintosh, Solaris. 0S/2��Amiga .�ȵȡ�
������:һ���ñ��������Ա���C��C++д�ij�����Դ�Դ�ļ�(��C��C++����)ת����һ����ļ����ʹ�õ�����(�����ƴ��룬��0��1)���������ͨ���������Ͳ�ͬ�ı�ǡ�ѡ����ɡ�����������ij����ʱ������/ת ������������ij����Ӳ�̸��Ƶ��ڴ��в������С���Python����д�ij�����Ҫ����ɶ����ƴ��롣�����ֱ�Ӵ�Դ�������г����ڼ�����ڲ���Python��������Դ����ת���ɳ�Ϊ�ֽ�����м���ʽ��Ȼ���ٰ�������ɼ����ʹ�õĻ������Բ����С���ʵ�ϣ������㲻����Ҫ������α���������ȷ������ת����ȷ�Ŀ�ȵȣ�������--��ʹ��ʹ��Python���Ӽ�������ֻ��Ҫ�����Python ����������- -̨�������,���Ϳ��Թ����ˣ���Ҳʹ�����Python�������������ֲ��
���������:Python��֧��������̵ı��Ҳ֧���������ı�̡���������̵������У��������ɹ��̻�����ǿ����ô���ĺ������������ġ����������������У������������ݺ�����϶��ɵĶ��������ġ���������Ҫ��������C++��Java��ȣ�Python ��һ�ַdz�ǿ���ּķ�ʽʵ����������̡�
����չ��:�������Ҫ���һ-�ιؼ��������еø������ϣ��ijЩ�㷨���������������IJ��ֳ�����C��C++��д��Ȼ�������Python ������ʹ�����ǡ�
��Ƕ����:�����PythonǶ�����C/C++���Ӷ�����ij����û��ṩ�ű����ܡ�
�ḻ�Ŀ�: Python ����ȷʵ���Ӵ����������㴦�����ֹ����������������ʽ���ĵ����ɡ���Ԫ���ԡ��̡߳����ݿ⡢��ҳ�������CGI�� FTP�������ʼ���XML��XML-RPC��HTML��WAV�ļ�������ϵͳ��GUI (ͼ���û�����)��Tk��������ϵͳ�йصIJ�������ס��ֻҪ��װ��Python,������Щ���ܶ��ǿ��õġ��ⱻ����Python�ġ�������ȫ�����
2.1.4 python ���Ե�ȱ��
�ٶ���:��C������ȷdz�������ΪPython�ǽ��������ԣ���Ĵ�����ִ��ʱ��һ��һ �еط��룬��CPU������Ļ����룬���������̷dz���ʱ�����Ժ�������C����������ǰֱ�ӱ����CPU��ִ�еĻ����룬���Էdz��졣
������:���Ҫ�������Python����ʵ���Ͼ��Ƿ���Դ���룬��һ-���C���Բ�ͬ��C���Բ��÷���Դ���룬ֻ��Ҫ�ѱ����Ļ�����(Ҳ��������Windows.�ϳ�����xx.exe�ļ�)������ȥ��Ҫ�ӻ����뷴�Ƴ�C�����Dz����ܵģ����ԣ����DZ����͵����ԣ���û��������⣬�������͵����ԣ�������Դ�뷢����ȥ��
2.2 URL
2.2.1 URL�Ķ���
ͳһ��Դ��λ���ǶԿ��Դӻ������ϵõ�����Դ��λ�úͷ��ʷ�����һ.�ּ��ı�ʾ���ǻ������ϱ���Դ�ĵ�ַ���������ϵ�ÿ���ļ�����-һ��Ψһ-��URL������������Ϣָ���ļ���λ���Լ������Ӧ����ô��������
2.2.2 URI��URL�ĶԱȺ;���
��������URL ������������������http://www.baidu.com����ַ�����
������URL֮ǰ������Ҫ����URI�ĸ���URIָ����Web.��ÿ�ֿ��õ���Դ����HTML�ĵ���ͼ����ƵƬ�Ρ�����ȶ���һ��ͨ����Դ��־��(Universal Resource Identifier��URI)�� �ж�λ��
URIͨ�������������: (1) ������Դ����������; (2) �����Դ��������: (3) ��Դ���������ƣ���·����ʾ��
�������URI: http://www.why.com.cn/myhtml/html1223/
���ǿ�������������: .
(1)����һ������ͨ��HTTPЭ����ʵ���Դ��
(2)λ������www.webmonkey.com.cn�ϣ�
(3)ͨ��·����/html/html40�����ʡ�
2.2.3 URL���
URL�ĸ�ʽ�����������:
(1)��һ������Э��(���Ϊ����ʽ)��
(2)�ڶ������Ǵ��и���Դ������IP��ַ(��ʱҲ�����˿ں�)��
(3)����������������Դ�ľ����ַ����Ŀ¼���ļ����ȡ�
��һ���ֺ͵ڶ������á���//�����Ÿ�����
�ڶ����ֺ͵��������á������Ÿ�����
��һ���ֺ͵ڶ������Dz���ȱ�ٵģ�����������ʱ����ʡ�ԡ�
2.3 Html
2.3.1����
�����ı���������DZ�ͨ�ñ�������µ�һ��Ӧ�ã�Ҳ��һ-�ֹ淶��- -�ֱ�����ͨ����Ƿ��������Ҫ��ʾ����ҳ�еĸ������֡���ҳ�ļ�������һ-���ı��ļ���ͨ�����ı��ļ������ӱ�Ƿ������Ը�������������ʾ���е�����(��:������δ�����������ΰ���,ͼƬ�����ʾ��)���������˳���Ķ���ҳ�ļ���Ȼ����ݱ�Ƿ����ͺ���ʾ���ǵ����ݣ�����д�����ı�ǽ���ָ��������Ҳ�ֹͣ�����ִ�й��̣�������ֻ��ͨ����ʾЧ������������ԭ��ͳ�����λ������Ҫע����ǣ����ڲ�ͬ�����������ͬһ��Ƿ����ܻ��в���ȫ��ͬ�Ľ��ͣ�������ܻ��в�ͬ����ʾЧ��
2.3.2 Htmlԭ��
(1)�û�������ַ(�����Ǹ�htmlҳ�棬�����ǵ�һ�η���) ������������������������������html�ļ�;
(2)�������ʼ����html���룬����<head>��ǩ����һ��<link>��ǩ�����ⲿCSs�ļ�; .
������ַ���CSS�ļ������������������CSS�ļ�;
(3)�������������html��<body>���ֵĴ��룬����CSS�ļ��Ѿ��õ����ˣ����Կ�ʼ��Ⱦҳ����
(4)������ڴ����з���-һ��<img>��ǩ������- -��ͼƬ�����������������ʱ���������ȵ�ͼƬ�����꣬���Ǽ�����Ⱦ����Ĵ���;
(5)����������ͼƬ�ļ�������ͼƬռ����һ-�������Ӱ���˺��������Ų�������������Ҫ�ع�ͷ��������Ⱦ�ⲿ�ִ���;
(6)�����������һ������һ��Javascript�����<script>��ǩ���Ͽ�������;
Javascript�ű�ִ����������䣬��������������ص������е�ij��<div> ( style.display="none")�����߰���ͻȻ��������ôһһ��Ԫ�أ���������ò�������Ⱦ�ⲿ�ִ���;
(7 )Javascript�����������һ�� <link>��ǩ��CSS·��;������ټ��������ĸ�λ<div><span><ul><li>�ǣ���������������µ�CSS�ļ���������Ⱦҳ�档
2.3.3 Html�ص�
�����ı���������ĵ��������Ǻܸ��ӣ�������ǿ��֧�ֲ�ͬ���ݸ�ʽ���ļ����룬��Ҳ����ά��(WWW)ʢ�е�ԭ��֮һ������Ҫ�ص�����:
������:�����ı�������汾�������ó�����ʽ���Ӷ��������㡣
����չ��:�����ı�������ԵĹ㷺Ӧ�ô����˼�ǿ���ܣ����ӱ�ʶ����Ҫ�����ı�������Բ�ȡ����Ԫ�صķ�ʽ��Ϊϵͳ��չ������֤��
ƽ̨����:��Ȼ���˼���������������ʹ��MAC�����������Ĵ������ڣ������ı�������Կ���ʹ���ڹ㷺��ƽ̨�ϣ���Ҳ����ά��(WWW)ʢ�е���-һ��ԭ��
ͨ����:���⣬HTML �������ͨ������,һ�ּ�ͨ�õ�ȫ�ñ�����ԡ���������ҳ�����˽����ı���ͼƬ���ϵĸ���ҳ�棬��Щҳ����Ա������κ������������������ʹ�õ���ʲô���͵ĵ��Ի��������
2.4��������
2.4.1 Chrome
Google Chrome���ֳ�Google ���������һ�� ��Google ( �ȸ�)��˾��������ҳ���������������ǻ���������Դ������д������WebKit��Ŀ���������ȶ��ԡ��ٶȺͰ�ȫ�ԣ��������������Ч�ʵ�ʹ���߽��档�����������������ڳ���Chrome�����������ͼ��ʹ���߽���(GUI) ��������beta���汾��2008��9��2�շ������ṩ50�����汾,��Windows��Mac OS X��Linux��Android���Լ�ioS�汾�ṩ���ء�2013 ��9�£�Chrome �Ѵ�ȫ��ݶ��43%����Ϊȫ��ʹ��������������ڱ��α�ҵ�����Ŀ��,Chrome�����Dz�����ҳ�Ĺ��ߣ�Ҳ������HtmlѰ�ҹؼ�<tag>����Ҫ���ߡ�
2.4.2 PycharmCE
PyCharm��һ��PythonIDE����һ���������û���ʹ��Python���Կ���ʱ�����Ч�ʵĹ��ߣ�������ԡ��������Project ������������ת��������ʾ���Զ���ɡ���Ԫ���ԡ��汾���ơ����⣬��IDE�ṩ��һЩ�����ܣ�������֧��Django����µ�רҵWeb������
���α�ҵ�����Ŀ�У�Pychram CE�е���ȫ����Python������������������Զ������ͼ���ؼ��ʹ��ܣ��ܺõ������Ч�ʣ����ٲ���Ҫ�Ĵ���
2.4.3�ն�.
�ն���OSX�в���ϵͳָ���Ӧ�ã��ڱ�����Ŀ���ն������յ�.py�ļ�ִ���а�����Ҫ�Ľ�ɫ��
�� ��Ŀ�������
3.1���������
3. 1����������̳
Table.1 Common Trade Website

3.1��������ó�����ּ�����
Table.2 Common Keywords In Trade On The Internet
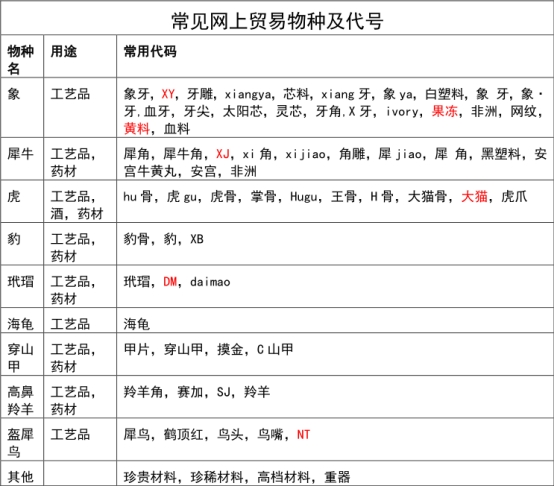
3.2��Ҫץȡ������
ȷ������Ҫ������վ�ؼ���֮����--��������URL��Ӧ����ҳ���ݽ���ץȡ��������Ҫ����������ҳ��Html���룬���������м�ֵ����Ϣ����������Ʒ���ƣ�����Ʒ���ӣ�������Ϣ������Ʒ��Ƭ��Ϣ�Լ�������ʱ�䡣�ر��ǽ���Ʒ�����Ӻ���Ƭ,���ڷǷ�Ұ������ó��Ʒ������ֵ�߰�,.��پͳ����ձ��������յ��ж�����Ҫ�����۽��м��𣬵�Ȼ���Ǻ��ˣ������ڱ��α�ҵ�����Ŀ֮�С�
3.3�������
�����ץȡ֮����Ҫ��ץȡ��������Ч���Ű��Ķ�������Ҫ���ǿ��Ա��浽���أ�����鿴�ͷ�����WWF��һ���ٺͲ鴦����õ��ǿ���һ-���ؼ���һ-�����ӵ��������������������ظ���ҵ��
�� ��Ŀ������ʵ��
4.1����ģ��
����ģ����Ҫ�����ض���URL�Լ��ؼ������ݣ���Python�����У�����ʹ��urlib2���Python����ģ����ʶ���ȡ��ص�URL��
4.1.1Ŀ����վURL
Ϊ�˸�����Ч���ҵ��ؼ��ֶ�Ӧ����Ϣ������Ŀ�����е�URL��������Ŀ����վ��URL�����ڱ���������վ��Ҫ���ĸ������Դ��Ҳ�����ܺܺõ�����Python�����ƣ����������˿������Ѷȣ���ѡ��ʹ��Ŀ����վ��̳��������������URL��Ϊ�����ȡ�����ݡ������ȿ��Խ���������Ҳ���Ը��ӷ����ץȡ��ص���Ϣ��
4.1.2 Urillib2ģ��
Urlib2ģ��������Ĺ������ÿͻ������������ͨ��request��response����ͨ���ͻ����������˷���request��Ȼ����շ���˷��ص�response��urllib2 �ṩ��request���࣬�������û��ڷ�������ǰ�ȹ���-һ��request�Ķ���Ȼ��ͨ��urllib2.urlopen��������������
����֮��Urllib2 �����������Proxy ������Timeout ������HTTP Request�м����ض���Header,Redirect������Cookie,ʹ��HTTP ��PUT ��DELETE �������õ�HTTP �ķ����룬Debug Log����
4.1.3αװ
��ʵ��ʹ���У����ڲ�����վ���Լ����еķ�����Ĺ��ܣ�Ϊ���ܹ�����ʶ��������Ҫ��ÿ�η���αװ����������в�����������ʱ�����Ʒ�ֹ���б�Ϊ����ץȡ������IP��
4.2ץȡģ��
ץȡģ��ʽ������Ŀ�ĺ��ģ����ȷ��ץȡ��Ҫ�����ݣ��������������ݸ����Ǹ�ģ����Ҫ���Dz������Ż��ĵط���
4.2.1 URL��html
ȷ��URL���ܹ��ɹ�ͨ��������ʸõ�ַ����Html����ʱ���Ϳ��Կ���ץȡ���е���Ч��Ϣ�ˣ��ڱ���Ŀ�У�����ʹ��Python ��Դ����������Beautiful Soupģ����Ϊץȡ�ĺ��ġ�
4.2.2 Beautiful Soup��
Beautiful Soup�ṩ- - Щ�ġ�python ʽ�ĺ������������������������ķ������ȹ��ܡ�����һ�������䣬ͨ�������ĵ�Ϊ�û��ṩ��Ҫץȡ�����ݣ���Ϊ�����Բ���Ҫ���ٴ���Ϳ���д��һ��������Ӧ�ó���
Beautiful Soup�Զ��������ĵ�ת��ΪUnicode���룬����ĵ�ת��Ϊutf-8���롣�㲻��Ҫ���DZ��뷽ʽ�������ĵ�û��ָ��һ�����뷽ʽ�� ��ʱ��Beautiful Soup �Ͳ����Զ�ʶ����뷽ʽ�ˡ�Ȼ���������Ҫ˵��һ��ԭʼ���뷽ʽ�Ϳ����ˡ�
Beautiful Soup�ѳ�Ϊ��1xml��html6libһ����ɫ��python��������Ϊ�û������ṩ��ͬ�Ľ������Ի�ǿ�����ٶȡ�
4.2.3ץȡ����
��ʵ�ʵ���ҳΪ�������ǻ����ղ���(cang.com) �������ؼ����������ʾ�Ľ��档���ǿ��Կ���ÿһ��������Ϣ��Html�ж�����װһ-���̶��ı�ǩ�С�������������Ϣģ���ֱ���װ��һһ����Ϊ<div class_ =*listview J-srp-content>�ı�ǩ�С�
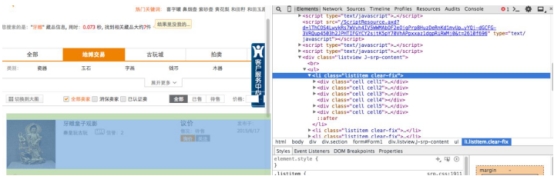
ͼ4.2��ҳHtml��ʾ��ͼ
Fig.4.2 Web Html screenshot
ʹ��BeatifulSoup ���Բ��ɸѡ��ǩ��ֱ������ץȡ����Ҫ����Ϣ��������Ϊ���ĵĴ�������:#href_ list[i].get('href),image_ list[i].get('data-original),title_ list[i].get_ text(),eller_ list[i].get_ text(),time_ list[i].get_ _text()
�öδ������5���������ֱ��Ӧ����Ʒ���ƣ�����Ʒ���ӣ�������Ϣ������Ʒ��Ƭ��Ϣ�Լ�������ʱ�䡣����Html�����У������ÿ--����Ϣ�����ڱȽ����ε�λ�ã�BeautifulSoup���Ա���������ָ����<tag>��ͨ�����а����IJ�ͬ�������<tag>���������ݻ���<tag></tag>֮�������������ݡ�
4.3���ģ��
�ܹ���Ч��ץȡhtml���������֮��,�����ص����ݲ����ػ�������Ҫ����Python�а�����open�������乹��Ϊopen(filename,���ʷ�ʽ[r,w,a,b])������r:������; w:д����; a:���Ӳ���; b:�����ƴ�ȡ���������ȱʡ����r��Python���ļ���������ͨ��open����,���ȷ����C�����е�fopen��.ͨ��open������ȡ- - ��file object,Ȼ�����read()��write()�� �������ļ����ж�д������
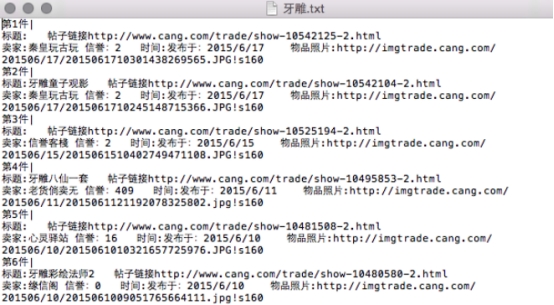
ͼ4.3ץȡ������ʾЧ��
4.5������
���ն˵���ӦĿ¼���ҵ�.py�ļ���ʹ��python .py �ļ�����ִ�У���������ͼƬ��ʾ��ҳ�棬����ؼ��ʺͶ�Ӧ��URL֮���������ɹ�������Ӧ����ʾ��
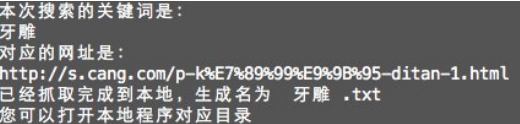
ͼ4.5.1�������н���
Fig.4.5.1 Table of Running Program
��.py�ļ������ļ��м��ɼ����ɵ�.txt�ļ�����������ؼ���֮�������µ�Ч��: .
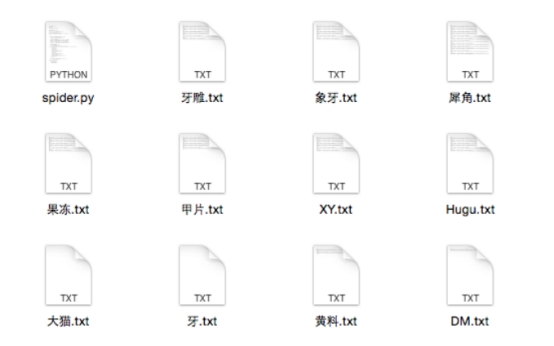
ͼ4.5.2ץȡ����ʾ���
Fig.4.5.2 The result of program
�� ��Ŀ����
5.1ץȡ����������
ץȡ������������ָ����Ҫץȡ�Ķ��Ԫ�أ�һһ����ȥ�������ȷ��ÿ--��������Ԫ�ض����������ȶ�ץȡ���ٵ�������֤�Ƚ����ʵ���ʾ״̬���ɡ�
��ʵ�ʹ����л�������ACSII����������ʾ�����������������������ڶ�Ӧ�ı�����������decode (UTF-8) �������
5.2��ʾ����������
��ʾ������������Ҫ�Ƕ��Ѿ����浽���ص��ļ������Լ����ݵIJ��ԣ�����ͨ�������ĶԱȺ�ƥ��鿴�Ƿ���ִ������������ʾ������������Ҫ������Դ������������ԭ����ץȡ����������������£�����������URL��ȷ����վ�����ȶ���ɵġ�
5.3�������Ӳ���
���������ֶ�Ӧ�ľ�������ʹ�����������:
Table.3 Network Test
�� �� ��
6.1�ջ���ɳ�
�������ȫ�ֹ�ץȡ�Ƿ�Ұ������ó����Ϣ�����α�������ճɹ�����һ���̶��Ͻ�ʡ������Դ��Ҳ���ӷ����ٺʹ�����ص���Ϣ��
ͨ����α�ҵ��ƣ���������ᵽ�����������������죬Ҳ�ڸ��ܸ��ּ����ij��ֺͲ��Ϸ�չ�ٽ��˸��и�ҵ�ķ�չ����ȻҲ������- -Щ�������ǻ����Ķ������������˳��������Կ�����Ҳһ-����ֵ�����۵Ļ��⡣��������ı�д�Ϳ����Ի�Խ��Խ�ã�Ҳ�ܹ��������ܵĿ�չ��
��α�����Ŀ���������Ҹ��ܵ��˱�����ԣ�������Python��������Ҳͨ�����ʵ������ķ�ʽ���˽�����ǰ���������ϲ���ѧ��Ķ�����Python�����ţ�����ʵ���Լ��ḻ�Ŀⶼ������������̵�ӡ�������ǿ�Դ�����Ϳ�Դ�ĵ��ij��ߣ���������������δ���ij���չ��Խ��Խ��ij�Ϊƽ���˶���ֻ�dz���Ա����Ҫ�߱�����Ȩ�����⣬��Ϊʵ����Ŀ��Ҫ���Ӵ���������Ϥ����HtmlΪ��������ҳǰ�����ԵĶ���ͷ�չ��Ҳ������һ�ȴ�����
6.2������չ��
��Ȼ���α�ҵ��Ƶ����ճɹ���������������������-��ʼ��������Ȼ�в��ٵľ��롣��Ҫ���ź��Լ�ϣ�������Ľ��ĵط���:
(1)URL�ж�Ӧ����������仯�����⡣���ڶ�����վ��ʹ���Լ��ļ��ܷ�ʽ�������������
Ӧת�����������Ӣ�ķ��Ŵ��룬�������ץȡ�����˾���鷳��
BeautifulSoupҳ��ץȡ��ʽ�����Ե����⡣����BeautifulSoup��ץȡָ������ʱ��������Html�е�<tag>��Ϣ,����ÿһ����վ��Ҫ���������ݽ���һ��ƥ��,��������������վ��
(2)���������ķ�ʽռ����̫���ʱ�䡣��ʵ�ʿ����У��һ�������ʹ�ñ���ץȡ���Scrapy�Լ��������ʽƥ�䷽ʽ���ץȡ��Ŀ�ģ�����ʧ���ˣ�Ҳ���������ʵ��������������Ž��ֵ��Ͷ��ʱ�䡣
���α�ҵ��Ʊ�д�����������Զ���ά���ԱȽϵ�--,֧�ֵĸ�ʽ����վҲ���ޣ�ϣ���ں������Ż��п��Ը��õĴ������������
�� л
��ѧ����ҴҶ�������Ȼ�����ź�����ҵ���Ҳ�����⣬����Ȼ�dz���л��λ��ᡣ������������ֻ��ʱ������ţ�Ҳ����������������ǰ�ص���Ѷ�뼼����Ϊδ��������������õĻ�����
��������ְҵ��ѧ��Ϊ�ҵ�ĸУ��������������ϢѧԺ�������ų�ֵ��ʳ��ѧϰ��Դ���Լ����Ը�λ.�쵼����ʦ��ͬѧ�ǵ����İ������������Թ�ΰ��ʦ��ָ�����±�ϼ��ʦ�����գ��Լ�����ͬ�꼶�������١����������������������
�����Ҫ��лWWF�����֧�֣������ṩ��Ҫ����վ��������Ϣ�����ݣ��Լ�����־Ը���Ŷӳ�Ա�Ĺ�����
��dz���лһֱ����ĬĬ֧�ֵļ��ˣ������Ǹ�ĸ�����������㹻�Ŀռ��֧�֡�
�����
[1] Swaroop. C.H A Byte of Python [DB/OL] 2003-2005
htp://sebug.net/paper/python/index.html
[2]BeautifulSoup4.2.0documentation[DB/OL] http://www .crummy .com/software/BeautifulSoup/bs4/doc/index.zh.html
[3] Z.Shaw LearnPythonTheHardWay[DB/OL] 2011
htp://sebug.net/paper/books/LearnPythonTheHardWay/ex 1.html
[4] HTML Tï/È ï f[DB/OL]
http:/baike.baidu.com/link?url=HAZwB-g0FySmtGN7zQ7bXV1 1-0_ d18WmFnPQZnqqplX_ _ntlc. _qVP3JzYkRNB1TsX
[5] Python Wikipaedia[DB/OL] www .wikipedia.com/python
[6] Wesley J. Chun. Core Python Programming[M].lL ïï: �� Edlß ltiÀt ,2008-06:8-10.
[7] �����εȣ��������������������������������[N]�� ����ʦ��ѧԺѧ��(��Ȼ��ѧ��), 2006(09): P60~63.8] �ٴ���ȣ��������������ݻ�ȡ�������ʵ��[)]����:С���ͼ����ϵͳ��1999.
[9]Ҷ������.�ֲ�ʽWeb Crawler���о�:�ṹ���㷨�Ͳ���[].����ѧ��, 2002, 30 (12A).
[10] Michelangelo Diligenti, Frans Coetzee, Steve Lawrence, etal. Focused Craw ling using Context Graph s[J ], Intemat ionalConference on Very Large Databases. 2002, (26):�� 527~534.
[11]�߿����ȣ�֧��Web��Ϣ����ĸ�����֩�����[]��С���ͼ����ϵͳ��2006 (07) : P1309~1312.[12] ��ѧ�µȣ�����֩���������ԱȽ��о�[A]�� �����������Ӧ�ã�2004(04): P131.
[13] Andrei Z. Broder, Marc Najork, and Janet L. Wiene Efficient URL Caching for World Wide Web Crawling[DB/OL]htp://esearch.microsoft.com/apps/pubs/default.aspx?id=65157
[14] R.Freemen HeadFirst Html&CSS[Z] HFLJJ/itt 2009
[15]raffic�йطǷ�Ұ������ó�������վ��ؼ���[DB/0L]2014.7
