中文摘要
随着我国电力市场制度的逐步发展以及清洁能源的引入,机组组合问题又面临着新的挑战。使用传统方法进行机组组合求解,能够求得经济上的最优解,但是在求解时间上随着系统规模的增大而迅速增大,难以满足当前电力市场快速出清的要求。针对上述问题,本文提出了基于强化学习的机组组合求解方法,在保证电力系统安全约束的情况下实现机组组合问题的快速求解。
本文首先对机组组合问题进行混合整数线性规划模型与马尔可夫决策过程的建模。在机组组合的问题背景下,引入了保证电力系统安全约束的混合整数线性规划问题模型,使用该分析方法能够利用 Gurobi 求解器实现求解,给出机组组合问题的最优解。引入了强化学习中马尔可夫决策过程的概念,基于机组组合问题的特点给出状态空间、动作空间、转移概率以及奖励函数,为强化学习打下基础。
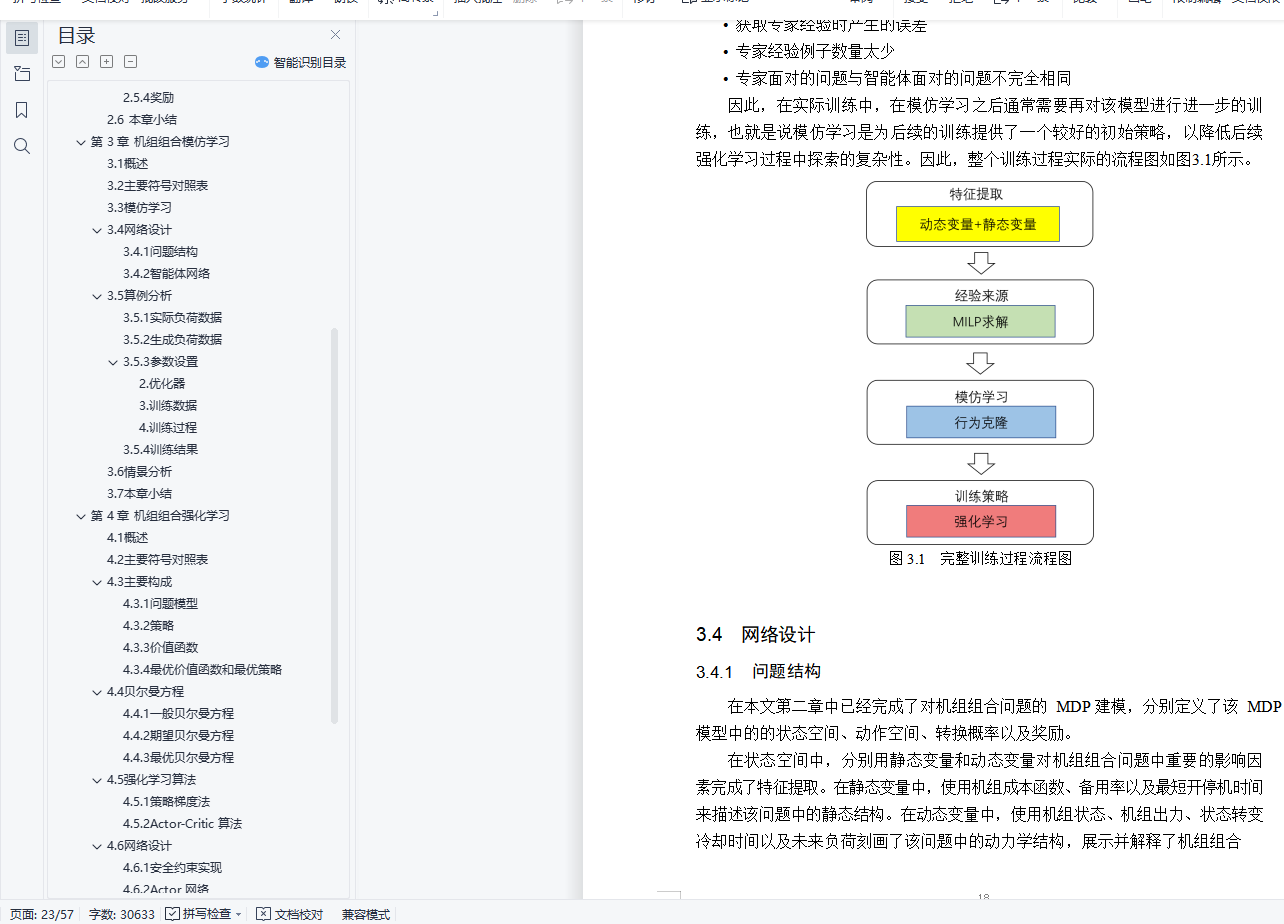
针对机组组合过程中每一个时段内的决策过程,引入了模仿学习的行为克隆方法。本文给出了一个基于ResNet 网络的智能体结构,并令其模仿混合整数线性规划问题方法给出的在某些场景下的状态决策对,使之能够求解在单时段内的机组组合问题。通过模仿学习,该智能体为强化学习提供了一个基础的策略网络,便于强化学习的求解。
最后,本文基于模仿学习给出的智能体作为基础的决策网络,引入了强化学习中的策略梯度算法,使用 ActorCritic 算法对该问题进行求解。提出了使用最优潮流优化限制、屏蔽函数与惩罚函数的三种方法实现了电力系统安全约束在各机组之间上与时序上的安全约束。使用强化学习方法给出的策略模型,能够以远小于优化方法的求解时间给出与优化方法相比成本差不多的解。
综上所述,本文的工作实现了对机组组合问题进行了优化问题及马尔可夫决策过程的建模,使用模仿学习得到一个求解单时段机组组合的模型,并使用强化学习使其能求解多时段的机组组合问题。本文引入数据驱动的方法扩展了电力系统优化调度的分析方法。
关键词:机组组合;MILP;MDP;模仿学习;强化学习
ABSTRACT
Using the traditional method for unit commitment solution, we can find the econom ically optimal solution, but the solution time increases rapidly with the increase of system size, which is difficult to meet the current requirements of rapid market clearing. To solve the above problems, this paper proposes a reinforcement learning based unit combination method to achieve fast solution of the unit commitment problem while ensuring the secu rity constraints of the power system.
In this paper, we first model the mixed integer linear programming model and Markov decision process for the unit commitment problem. In the context of the unit commitment problem, a MILP model is proposed to ensure the safety constraints of the power system. The concept of MDP in reinforcement learning is introduced.
The behavioral cloning method of imitation learning is introduced for the decision process within each time period of the unit commitment process. In this paper, an agent based on ResNet network is given and made to imitate the statedecision pairs given by the MILP method in certain scenarios to solve the unit commitment problem in a single time period.
Finally, this paper introduces the policy gradient algorithm in reinforcement learning based on the agent given by imitation learning as the underlying decision network, and solves the problem using the Actor Critic algorithm. Three methods using OPF optimiza tion restrictions, shielding functions and penalty functions are proposed to achieve the safety constraints of the power system in cross section and in time sequence.
In summary, this paper implements the modeling of the MDP for the unit commit ment problem, using imitation learning to obtain a model for solving the single time unit commitment, and using reinforcement learning to enable it to solve the multi time unit commitment problem. This paper introduces a data driven approach to extend the analyt ical approach to optimal scheduling of power systems.
Keywords: unit commitment; MILP; MDP; imitate learning; reinforcement learning
目 录
第 1 章 引言 1
1.1研究背景 1
1.2研究现状 1
1.3研究意义 2
1.4研究目标与主要工作 3
1.4.1研究目标 3
1.4.2主要工作 3
第 2 章 机组组合的马尔可夫决策过程建模 5
2.1概述 5
2.2主要符号对照表 5
2.3直流潮流模型 6
2.4考虑安全约束的电力系统机组组合优化模型 7
2.4.1决策变量 7
2.4.2目标函数 8
2.4.3约束条件 8
2.5考虑安全约束的电力系统 MDP 建模 9
2.5.1状态空间 10
2.5.2动作空间 12
2.5.3转换概率 12
2.5.4 奖励 13
2.6本章小结 13
第 3 章 机组组合模仿学习 14
3.1 概述 14
3.2主要符号对照表 14
3.3模仿学习 14
3.4网络设计 16
3.4.1问题结构 16
3.4.2智能体网络 17
3.5算例分析 19
3.5.1实际负荷数据 19
3.5.2生成负荷数据 20
3.5.3参数设置 20
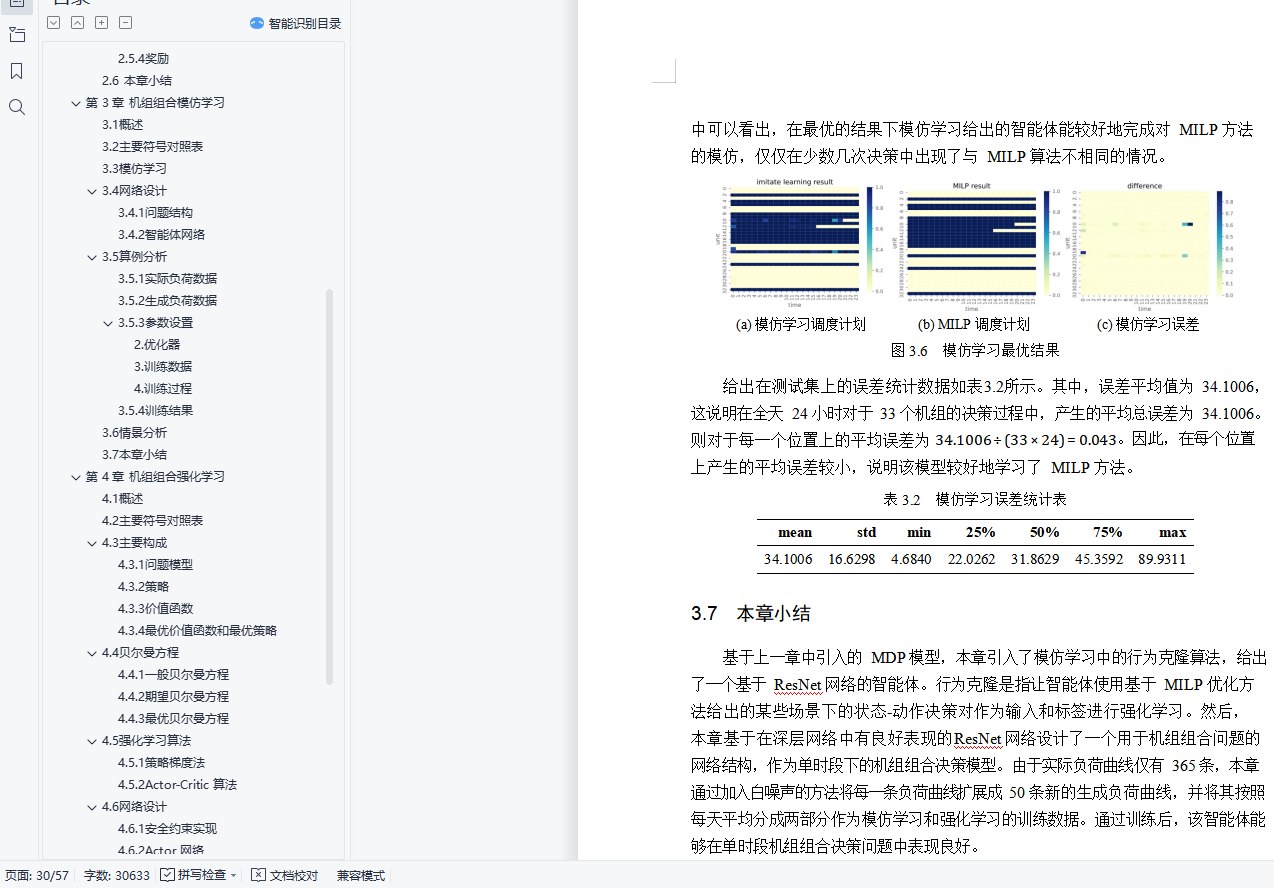
3.5.4训练结果 21
3.6情景分析 22
3.7本章小结 23
第 4 章 机组组合强化学习 24
4.1 概述 24
4.2主要符号对照表 24
4.3主要构成 25
4.3.1 问题模型 25
4.3.2 策略 26
4.3.3价值函数 26
4.3.4最优价值函数和最优策略 27
4.4贝尔曼方程 27
4.4.1一般贝尔曼方程 27
4.4.2期望贝尔曼方程 28
4.4.3最优贝尔曼方程 28
4.5强化学习算法 28
4.5.1策略梯度法 29
4.5.2ActorCritic 算法 29
4.6网络设计 31
4.6.1安全约束实现 31
4.6.2Actor 网络 33
4.6.3Critic 网络 34
4.6.4训练过程 35
4.7算例分析 35
4.7.1 数据 35
4.7.2参数设置 36
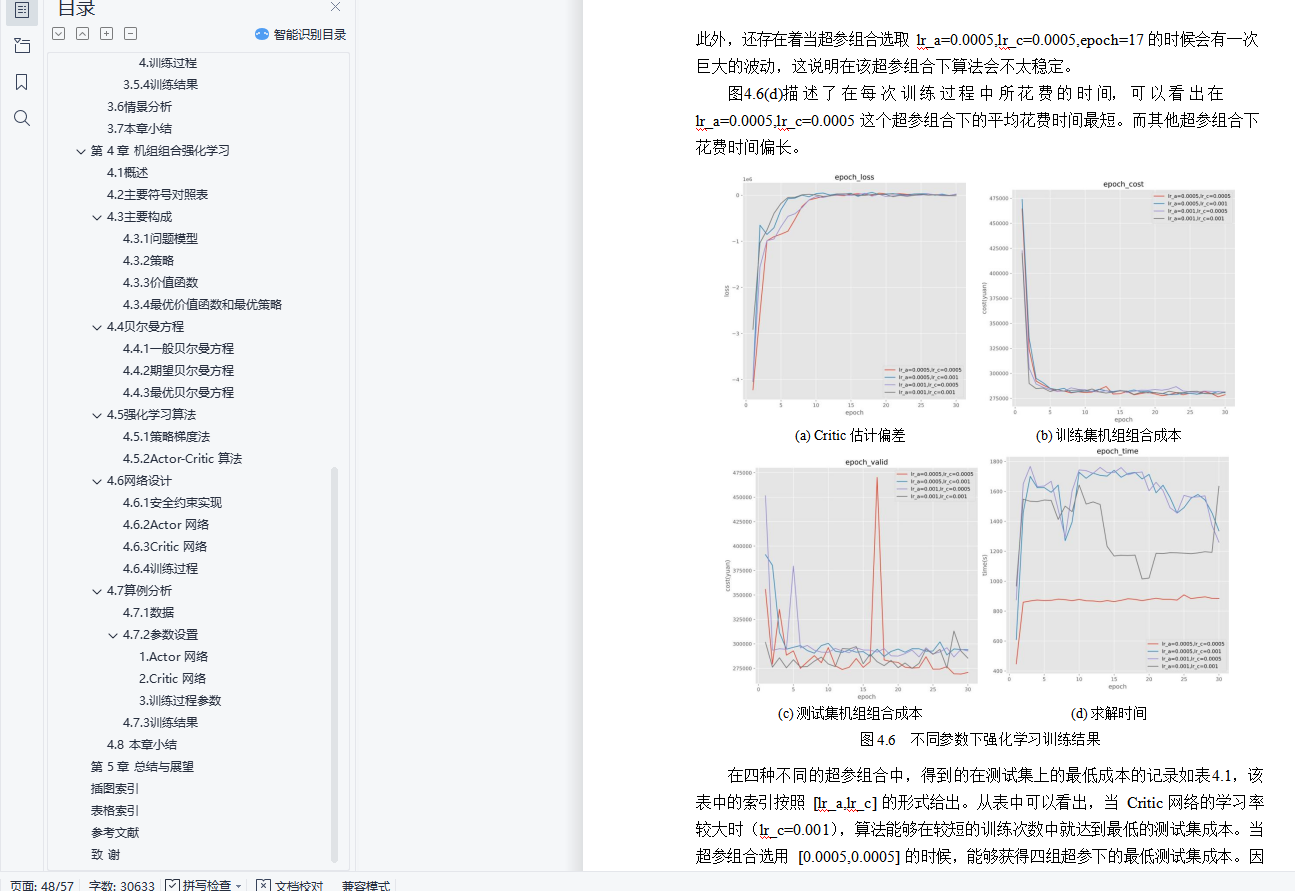
4.7.3训练结果 37
4.8本章小结 39
第 5 章 总结与展望 40
插图索引 42
表格索引 43
参考文献 44
致 谢 47