xt-align: justify; text-indent: 2em; margin-top: 0px; margin-bottom: 0px; -ms-text-justify: inter-ideograph;">[45]C.-L. Yang, H.-W. Tseng, C.-C. Ho, and J.-L. Wu. Software-Controlled Cache Architecture for Energy Efficiency. Transactions on Circuits and Systems for Video Technology, 15(5):634�C644, 2005., ժҪ
������������(BFS)�㷨������ͼ�δ���Ӧ�ó���ͷ����������صĻ�������Ȼͼ�δ�����Ԫ(GPU)�ṩ�˴����IJ����ԣ�������GPU��ʵ�ָ����ܵ�BFS�㷨������Ҫ��Ч���ȴ���GPU �̺߳���Ч����GPU�ڴ��νṹ���ڱ����У����������һ�ֻ���GPU��BFS�㷨����Enterprise������������ּ���������DZ�ڵ�����ƿ��:(1)ͨ������һ��û�в����߳����õı߽��������GPU�̵߳��ȣ�ͬʱ�������ظ��ı߽磬���Ҷ��Զ����º��Ե����ϵ�BFS���������Ż���(2) GPU�������ؾ��⣬���ݲ�ͬ�ij������Ա߽����з��࣬�Ӷ�����GPU�����д�С�IJ������ȣ�����������̼߳��IJ�����;(3)����GPU��BFS�����Ż������˹ؼ�����Է����л���Ӱ�죬�Ӷ�������GPU�����ڴ�����ѡ��ػ��������ؼ����㣬������˰����������ݷ��ʡ������Ѿ��ò�ͬ��GPU�豸�ø���ͼ�����ݶ�Enterprise������������2014��11�£�Enterprise��NVIDIA Kepler K40��ʵ����760����ÿ��Ĵ�Խ��(TEPS)����ͼ500��������45λ������GPU��ʵ����1220����ÿ�봩Խ�ߡ���GreenGraph 500(С���������)�У�Enterprise��4.46������Խ�ߣ�TEPS��/�ߵijɼ���Ϊ����ԴЧ����ߵ��㷨��
1. ����
������������(BFS)�㷨����������������صĹ����飬�絥Դ���·�����н�������[16,31,32,42]������������[37,40]��ֵ��ע����ǣ�ͼ500��ʹ������ͼ�ϵ�BFS�����������ܵı�����������������ܼ���Ӧ�ó����Ӳ���ܹ�������ϵͳ [1]����������У������ر����Ȥ���Ǽ��ٿ���������ҽѧϸ��[26]��WWW[9,25]���罻����[17,27]�ȹ㷺��Ӧ�����ҵ���������ͼ�ϵ�BFS������
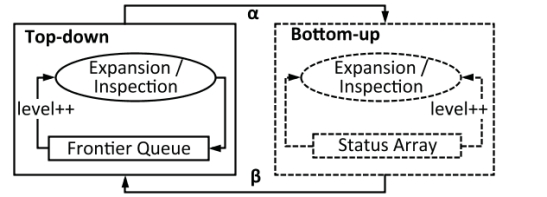
��ͳ��(�Զ�����)BFS�㷨��ͼ�εĸ���ʼ���������֮��������(������)�����״̬��������κ�δ�������������ڵ㣬�㷨�Ὣ��ʶ��Ϊһ���߽�㣬��������������ڱ����г�Ϊ�߽����еĶ����У�Ȼ������Ϊ�ѷ��ʵġ���鵱ǰ������εĽ���ǣ��߽����������иոշ��ʹ��Ķ�����ɣ���Щ���㽫������һ���������չ�����ɴˣ�BFS������ѡ��߽������е�ÿ�����㣬��������ڵĶ��㣬����Ǹշ��ʵ�������㡣չ���ͱ����Ĺ���һ��һ����ظ���ֱ��ͼ��û��δ���ʵĶ��㡣�������������Ե�����BFS�㷨[10]�������������ڽ���ͬ�Ķ����ʶΪ�߽�㡣��Ȼ���߽�������BFS�㷨�ĺ��ġ�����ÿһ�㣬BFS��ǰһ�������ı߽����п�ʼ����һ���µı߽���н������ö��н�������һ�����չ��
ͼ�δ�����Ԫ(GPU)�����ṩ�˴����IJ�����(��100k�߳���)�����ṩ�˿��ٵ�I/O(����100s GB/s���ڴ����)����ʹ������Ϊ����BFS�㷨������Ӳ��ƽ̨�����ҵ��ǣ���������ij���[21,33,36,24]ȡ���������Ľ�չ��������GPU��ȫ��������ʵ�ָ�����BFS��Ȼ���м������ս�ԡ��ڱ����У��������Ÿ����ܵ�BFSϵͳӦ��ͨ���Դ���GPU���������ĸ�Ч�����Ͷ��ص��ڴ��νṹ����ϸƥ��GPU��Ӳ�����ԡ�
���������һ�ֻ���GPU��BFSϵͳEnterprise(��ҵ����1976��Ϊ������ֽ���ĵ�һ�ܺ���ɻ������֡�)����ϵͳ���������GPU�ĸ��߳����ʹ��ڴ�������ƣ���BFS��ִ���������ݷ���ģʽ�����˶��ơ�Enterprise�ڵ���NVIDIA Kepler K40�Ͽ�ʵ��760��TEPS/�룬������GPU�Ͽ�ʵ��1220��TEPS/���4.46��TEPS /���أ���2014��11�£�����ɼ���ͼ500������45����GreenGraph 500С���������ŵ�1λ������ͨ�������¼��������ʵ�ֵ�:
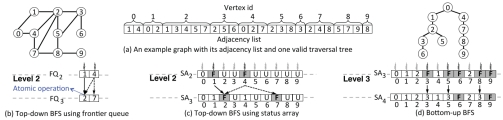
ͼ1:(a)һ��ʾ��ͼ�����ڽӱ���һ����Ч��BFS������(���ܴ��ڶ����Ч��BFS��)����������ƪ�����ж�ʹ����������ӡ��Զ�����BFSʹ��(b)�еı߽����л�(c)�е�״̬���飬��(d)�����Ե�����BFS���á�״̬�����е����ֱ�ʾ���ʶ���IJ�Ρ�F��U�ı�ǩ�ֱ��ʾ�߽綥���δ���ʶ��㡣��(c)��(d)�У�������DZ߽綥��Ļ�ɫ�߳̽������Ҳ����κι�����
���ȣ���GPU�̵߳�����ͨ��������ͬ�������ɵı߽�������ʵ�ֵ�:��ɨ�赱ǰ�����ͼ��״̬���飬Ȼ�����ǰ�����ɱ߽����С��ڽ��߽�����ʱ����Ҫԭ�Ӳ�����ȷ��������ÿ���߽綥���Ψһ�ԣ�Ȼ��������GPU��˵�����ֲ������ܻᵼ�´���GPU�̵߳Ŀ�����ͨ�����������ɷ�Ϊ�������裬Enterprise��������ͨ�����еظ��ºͷ���״̬�����������߳�ͬ������Ҫ�������ԴӶ�����ɾ���ظ��ı߽磬�Ӷ����⽫���������õĹ��������һ������ڴ��Ż��������Զ����º��Ե����ϵ�BFS����������,������������Ҫ����������ʱ�����ɶ��У������ǵ�GPU�̵߳��ȿ��Խ�����BFS����ʱ��ӿ�37.5����
��Σ�ͨ�����߽�������ƽ��GPU�Ĺ������ء�Ϊ�˼����̼߳乤�����صIJ�ƽ�⣬Enterprise�����ⲿ��(�����ڶ���ıߵ�����)���߽�����ŵ���������У���Ϊÿ�����з��䲻ͬ�������̡߳�������˵��Enterprise�������ĸ���ͬ�ı߽����У��ֱ��Ӧ��Thread��Warp��Cooperative Thread Array (CTA)��Grid[4]�����磬��ҵ����Ϊ�����С��32�ı߽����һ��Thread��Ϊ�����С��256�ı߽����һ��Warp����ҵ�������Խ�һ��block�ϵ������̷߳����һ���߽�㣬�Դ������˸ߵij�����(����10^6)����ǰ�Ĺ���ʹ�ù̶��������߳�(ͨ��Ϊ32��256)�����о�̬���䳣�������߳�֮��Ĺ���������б[21,33,23,29]���߽�����������һ��ƽ��,����Ϊ���������GPU�̵߳��ȼ����ṩ1.6-4.1���ļ��١�
��������Enterprise�п�������GPU��֪�ķ����Ż����Դ���GPU�ϸ�Ч�����Ե����ϵ�BFS�������˵�����������һ��ʹ�ñ߽������йؼ��ڵ�ı��ʶ�����²�����ͨ�����������ȷ����GPU�����϶��µ����µ��ϵ�һ�����л��Ŀ�������������ڲ�ͬ��ͼ�����ȶ��ģ�����Ҫ��ǰ���[10]�����������в�������������Ҫ���ǣ�Enterprise��ѡ��ػ���GPU�����ڴ��еĹؼ����㣬�Լ��ٰ�������ȫ���ڴ���ʡ���Ȥ���ǣ����ֻ��ڹ����ڴ�Ļ���Ĵ�С��С��ֻ��48kb�������漸ǧ���ؼ�����ʱ���������Ե�����BFS���ٸߴ�95%��ȫ���ڴ�����
������֪,Enterprise�ǵ�һ���������ø��ָ�����GPU�߳�����ƽ�ⲻ����Ĺ������أ�ͬʱʹ�ò�ͬ��GPU����������������ʵĻ���GPU��BFSϵͳ, ,�����㶼������ͼ�ڽ��б���ʱ�����е����ԣ��������ִ�GPU�϶�����Ż�ʮ�־�����ս�ԡ�Enterprise������֧�ֶ���ͼ���㷨���絥Դ���·����ֱ����⡢ǿ��ͨ�������н������Եȡ�
���ĵ����ಿ����֯����:��2�ڽ����˱�����ʹ�õ�GPU��BFS��ͼ�ı�������3�ڽ�������GPU������BFS�㷨����ս����4�����������ּ��������ŵ㡣�����ڵ�5����չʾ��Enterprise�����弨Ч����ԴЧ�ʡ���6����������ع�������7���ܽᡣ
2. ����
2.1�����������
��ͳ��(�Զ�����)BFS�㷨��ÿ������Ͻ�����չ�ͼ�飬����ÿ���߽�(������ʵ�)����v��ʼ��������ڵĶ���w�Ƿ��״η��ʡ�����ǣ���v��Ϊ����㣬wҲ�����뵽�߽������С�
�߽�����ͨ�����ַ�ʽ���ɡ���ͼ1(b)�ĵ�һ�ַ����У���Ϊ���ڱ߽������[30]��ԭ�Ӳ������ڵ�2�����������߳������FQ2�����ж���1��4���ڽӱ��������̶߳���Ѷ���2����FQ3������������£�ʹ��ԭ�Ӳ���(���磬CUDA[4]�е�atomicCAS)��ȷ��FQ3û���ظ��ı߽磬�������Ƚ������߳̽���Ϊ����2�ĸ��̡߳����û��ԭ�Ӳ���������2����������Σ����µ�3���Ĺ������ࡣ
ͼ2:���(�����Ż�)BFS��
�����̼߳�ͬ����GPU�ϴ��۸߰����ڶ��ַ���[24,36]ʹ����Ϊ״̬����(SA)�����ݽṹ������ͼ��ÿ�������״̬��״̬������������ɶ���ID�������ֽ����顣�����״̬������δ���ʵġ��߽�Ļ��ѷ��ʵ�(����BFS�����ʾ)����ÿһ�㣬ÿ�����㱻����һ���̣߳���ֻ����Щ�ڱ߽���Ϲ������̲߳Ż�ִ����չ�ͼ�顣��ˣ���ͼ1(c)��ʾ����Ȼ��2����ʹ��10���̣߳���ֻ���ڶ���1��4�ϵ�2���̻߳Ṥ�������ַ������ŵ��Dz�����Ҫԭ�Ӳ�����������1��4�������Ƕ���2�ĸ��ڵ㣬���ҿ���˳��ִ�ж���2״̬�ĸ��¡���������һ�ַ�����ͬ���ǽ������������Ǹ�����Ϊ����2�ĸ���㡣
ʹ���Զ����·�����ʼ�����BFS�������л������ﵽԤ������ֵʱ���Զ����º��Ե�����֮���л�����ͼ2չʾ�˻��(�����Ż�)BFS�Ĺ������̡��Զ����µ�BFSּ��ʶ�߽���δ���ʵĶ������������ıߣ����Ե����ϵ�Ŀ����ʶ��߽�㼰�����ӵ��ѷ��ʵĶ��㡣������ʽ���߽�㶨��Ϊ:
����(�߽��)��vΪͼg�Ķ��㡣�ڵ�i�㣬vΪ�߽磬�����
•���϶���BFS:v��i-1�㱻����;
•���¶���BFS: v��0 �C i-1����δ�����ʹ���
ʹ��ͼ1�е���ͬʾ�����ڵ�2�����Զ������㷨ѡ��{1,4}��Ϊ�߽硣��Եģ��Ե������㷨ʹ��δ���ʵĶ���{3��5��6��8��9}��Ϊ����3�ı߽硣���Ե����Ϸ��ֶ���{3,5}���ӵ����ʹ��Ķ���2ʱ�����DZ��������Ϊ��2��Ϊ���ڵ�Ķ��㡣���Ƶأ�����8���������Ϊ��7��Ϊ���ڵ㡣
�����л���Ŀ���Ǽ���DZ�ڵĴ�������Ҫ�ı�Ե��顣���BFS�ڴ˹����п��ܻ������л������������϶��µ��Ե����Ϻ��Ե����ϵ��Զ����£�ÿһ���л�����һ���������������ͼ2��,����ͨ��mu��mf�ı��ʼ������,����mu��ʾδ���ʵı���,mf��ʾ�����Զ������㷨���ʵı�;����ͨ��n��nf�ı����������,����n��ʾͼ�Ķ�������nf��ʾ�߽�����еĶ����������Ŀǰ��ֵ������ʽ��̽��ʽ��ȷ���ġ�
ͼ3:GPU�ܹ��ļ���ͼ��
��BFS�����Σ�Ϊ�˱���ͼ�еĶ�Enterprise��˵��û�б�ҪҲû�кô��ij�β�������Ǵ��Ե����ϵ��Զ����½������л������ڱ����У����ǽ�չʾ����һ����Ч�Ļ��BFSϵͳ��Ҫ������GPU��֪�Ż��������ȶ��ķ����л��������ؼ����㻺�桢������GPU�̵߳��Ⱥ�������ƽ�⡣
2.2ͨ�õ�GPU
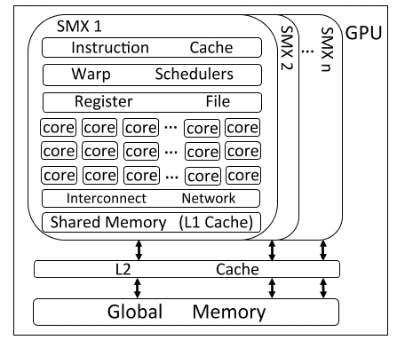
�ڱ����У����ǽ���Ҫ����GPUӲ������NVIDIA Kepler K40Ϊ��[8]��K40��15����ý�崦����(SMX)��ɣ�ÿ����������192��������CUDA�˺�64��˫���ȵ�Ԫ��ÿ��GPU�߳�������һ��CUDA�ں��ϣ�SMX��32���̰߳�����һ����(��ΪWarp)��ͼ3չʾ��GPU�ܹ��ĸ�����
һ��SMX������֧��64��warps��һ��warp�е������̶߳��Ե�ָ����̷߳�ʽִ�С����ǣ����һ��warp�е��߳��в�ͬ�Ŀ���·������ôwarp������ִ�����еķ�֧�������ò��ڸ�·���ϵ������̡߳��ⱻ��Ϊ��֧��ɢ���⣬������ڵĻ������Դ��SMX�������ʡ�
ÿ��SMX����4��warp���ȳ�����������ѡ��4��warp������������ִ�е�warp���ȳ����з���ָ��������ڳ��ӳٵ����ݷ��ʶ�û�����õ�warp��ͨ����ÿ��SMX�еij����̣߳����ݷ��ʿ���������ص���
Э���߳�����(CTA)���߳̿飬�ɶ��warps��ɣ�ͨ����1��64�����������������д������̡߳�GPU������CTA�ļ��ϳ�Ϊһ��Grid��CTA��������ÿ��CTA�е��߳����ǿ����õġ�CTA�е�ÿ���̶߳���һ��Ψһ���߳�ID��ÿ��CTA�����Լ���CTA ID��������Щ���ñ������Ϳ���ʶ��grid�е�ÿ���̣߳������Ȳ�ͬ���̴߳�����ͬ�����ݡ�
��1:ͼ��˵��
Kernel����Ϊ������GPU�ϵ��κκ�����ͨ����һ���ں˿���ʹ�����ȷ�������̵߳IJ�ͬ�IJ������ȡ�(�̡߳�warp��CTA��grid)��Kepler����Hyper-Q��֧�ֲ����ں�ִ�У����仰˵���������ں���ͬһ��GPU��ִ��ʱ��Hyper-Q�ܹ������ǰ����ڲ�ͬ��SMX�ϲ������У��Ӷ������������GPU��Դ��
GPU�ڴ��νṹ��ÿ��SMX���д����Ĵ��������磬ÿ��K40 SMX��65,536���Ĵ�����ÿ���߳�������ʹ��255���Ĵ�������Ϊÿ��ʱ������ִ��4���Ĵ������ʡ����⣬ÿ��SMX�ṩ���������õĹ����ڴ�(L1����)�������ڲ������CTA�ڲ�����ͨ�š�ÿ��K40 SMX��64 KB�Ĺ����ڴ档��CPU�ϵ�L1���治ͬ�������ڳ�������ʱ����16��32��48 KB�Ĺ����ڴ档һ�����أ������ڴ��е����ݶ�һ��CTA�е������̶߳��ǿɶ��Ϳ�д�ġ�
GPU����������SMX������L2�����ȫ���ڴ档K40��1.5 MB L2��12GB��ȫ���ڴ档ÿ��ȫ���ڴ���ʶ�����һ�����ݿ飬�����ݿ�������Ͱ���32��64��128���ֽڡ����һ���߳�ǡ�÷���ͬһ���е����ݣ���ִֻ��һ��Ӳ����������ͨ�����ַ�ʽ����ȫ���ڴ���ʺϲ�Ϊ���ٵĴ��������K40�ܹ�ʵ�ֽӽ�300GB/s��DRAM������
��2:CPU (Xeon E7-4860) vs. GPU (K40)�ڴ�:��С�ͷ����ӳ�(CPU��GPU����)[28,4]
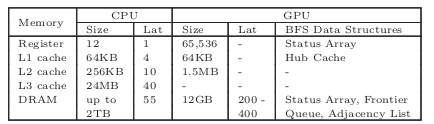
��2�ܽ���CPU��GPU�ڴ��νṹ��ע�⣬K40û��L3���档������Ϊ�Ĵ��������ڴ��ҵ���ʽ���ӳ������������ǵIJ��Ա������������ٱ�ȫ���ڴ��һ������������������У�����������GPU֧�ֵIJ����ں˺Ͳ�ͬ������������̬ƥ��BFS�������أ����Ը���BFS���ݽṹʹ���˲�ͬ��GPU�ڴ棬����Թؼ�����ʹ�ù����ڴ档
GPUӲ�����ܼ������������GPU����֧��100���Ӳ��ָ��[5]�����������,���ǵ�Ŀ���������ں�����,GPU I / O������������ϵͳ����ԴЧ��,������ͬ�ں˵�ʱ���,�����ڴ����/�洢���ܵ�Ԫ(ldst_fu_utilization),���������������ͣ���İٷֱ�(stall_data_request),ȫ���ڴ渺������(gld_transactions),IPC�����ܡ�����ʹ������NVIDIA���ߣ���nvprof��nvvp��
2.3ͼ�β��Ի�
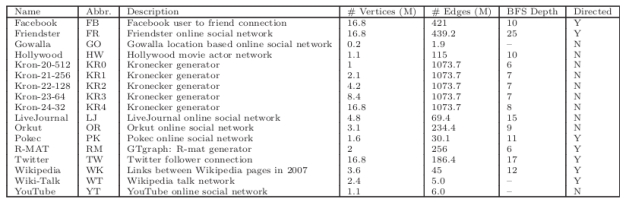
����һ��ʹ����17��ͼ�����1��ʾ��������Ϊ100�� - 1700����Ϊ3ǧ��- 10�ڡ���������ͼ�����ǽ�ÿ����������������ߡ�����Facebook[19]��Twitter[27]��Wikipedia[7]��11����ʵ�����ͼ���Լ�˹̹����ѧ�����������ݼ�[6]�е�LiveJournal��Orkut��Friendster��Pokec��YouTube��Wiki-Talk��Gowalla�罻����ͼ�����⣬����ʹ�������ֹ㷺ʹ�õ�ͼ��������Kronecker[1]�͵ݹ����(R-MAT)�㷨[13][3]�������������������ֿ�����A,B,C��D = 1.0−A−B−C��Kronecker������������Kron-Scale-EdgeFactorͼ��������2^scale�����㣬ÿ������ӵ��EdgeFactor��ƽ�����ij��ȡ���������У����Ƕ�Kroneckerʹ��(0.57,0.19,0.19)��(A, B, C)����R-MATͼʹ��(0.45,0.15,0.15)��ֵ��ָ�����ǣ���ʵͼ�ͺϳ�ͼ�����������������������ڴ��������ij�������С��ռ�ܱ����İٷֱȽ�С����˴��ڴ������н϶���ȵĶ��㡣
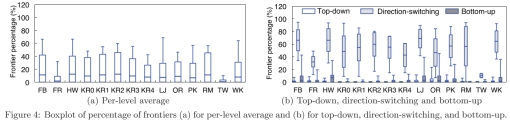
ͼ4.�߽����ռ�ٷֱȵĺ�ͼ
3.��Ƶ���ս
��ս1:�ú�����GPU�߳�
����GPU���ɱ߽������Ҫ��ԭ�Ӳ�����֮ǰ���ص㹤��(24,33,29,36,35,30]����ֻ�����һ������⡪������Ӧ�ý��ɱ߽�㣨��Ҫ̽������һ��Ķ��㣩���ɡ�ʹ��״̬���������һ����������ܱ�����ԭ�Ӳ��������ǻ�Ϊÿ���������һ��GPU�̣߳�������������Ƿ��DZ߽��[36,24]�����ֵ�Ч�ķ������������GPU�̣߳���Ϊ�ڴ������������ϣ���������㶼���DZ߽�㡣���ߣ���һ������[33]ͨ��warp����ʷ�����ɱ߽���У�����ͬ�������ַ���������ȫ�����Ť�����ظ����㱻������С�ͼ4(a)��ʾ�˲�ͬͼ��ÿһ��߽��ٷֱȵ�����ͼ��������ʾ��ƽ��ֵ�����ֵ�ٷֱ��Լ������ע�⣬��������ְ����Զ����º��Ե����Ϸ���ı߽�㡣�����ʾ��ͼ��ÿ��ƽ����9%�ı߽�㣬����Ϊ15%������R-MATͼ��ƽ���������Ϊ11%�����ֵΪ57%����Twitter��ƽ��������С��Ϊ1%�����ֵΪ10.2%�������ÿһ��Ϊÿ���������һ���̣߳�ƽ��������31%���̻߳���С���ˣ��ؼ�����һ��ֻ�����߽��Ķ��У������ǽ������GPU�߳��˷�����Щû�й���Ҫִ�еĶ��е��ϡ�
������Ҫ���Զ����º��Ե�����֮���л����Ӷ�ͨ����ע���鲻ͬ�Ķ���(�Զ����·���vs.�Ե����Ϸ���)�����ɱ߽磬���һ���Ӿ�����һ��ս��Ϊ��˵��������⣬������ͼ4(b)����BFS���������ʾ�߽�İٷֱȡ�һ����˵���Ե����ϵļ�����Զ����µļ�����и���ı߽�㣬��1.5%��0.4%���ر��ǣ����Զ������л����Ե�����ʱ��ͬһ������еı߽��ƽ�����Ϊ52%������������ϵ���ʹ��״̬������Ȼ�ǵ�Ч�ġ�ͨ�����Ϲ۲죬Enterorise�������µ�GPU�̵߳��ȣ���Ŀ������һ������GPU�ڴ��νṹ�������Ż��ı߽����С�
��ս2:��GPU�߳�֮��ƽ�������
��һ��սԴ�ڱ߽��ij����������ž�IJ�����ʵ�����һ���߽���и���ıߣ����������GPU�߳���Ȼ��Ҫ���и������չ�ͼ�顣Ϊ��˵�����ֲ�ƽ�⣬������ͼ5�л����������罻����ı�����CDF������Gowalla��Orkut��ƽ�����ȷֱ�Ϊ19��72����Gowalla�У�86.7%��99.5%�Ķ�����С��32��256���ߡ����֮�£�Orkut�й�����32�������µĶ�����ռ�ı�����С(37.5%)������32��256֮��Ķ�����ռ�����ϴ�(58.2%)�����⣬��Gowalla��Orkut�У���һС����(0.5%��4.2%)����ı߳���256������β���ϳ�����ԼΪ30K�ߡ�
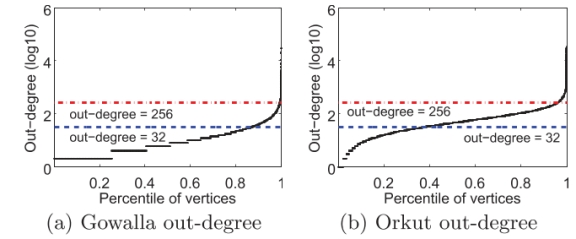
ͼ5:���㰴��������ij����ۻ��ֲ�����(CDF): (a) Gowalla (b) Orkut��
��̬�ط���̶��������߳�(���磬һ��warp��CTA)�ǵ�Ч�ģ���Ϊÿ����ε�����ʱ�佫�ɹ���������߳̿��ơ���һ��Ч�ʵ��µ�ԭ��������߳����������ز�ƥ�䡣���磬���һ��CTA��������������32�����ڶ���ı߽���Ϲ�������ô���CTA�е�200����߳̽�û�й���Ҫ��������һ����������£�һЩ���зdz�����ȵı߽�㽫��Ҫ���CTA�����磬���Ǽ���һЩͼ�Ķ��������106���ߡ�Ϊ�˽����һ��ս��Enterprise������һ���µķ��������ݳ������Ա߽����з��࣬��������ʱ�����ʵ���GPU�������ȡ�
��ս3:���Ե����ϵ�BFS��ӦGPU
��GPU��ʵ�ַ����Ż���BFS��������һ����ս�������Ż���BFS�������[10]�еĶ��CPU�������ʵ�ֵģ��������û�н�һ�����Ż��������ڿ���������ǧ���̵߳�GPU�ϸ�Ч�����У���ȫ�ֻ���Ĵ�С(����12GB)���ٶ�(����200-400������)��Խ�С��
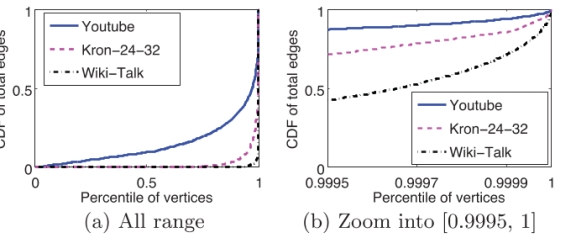
ͼ6:Youtube��wikitalk��Kron-24-32ͼ�����бߵ�CDF�����㰴��������:(a)Ϊ���з�Χ�ڵĶ���(b)���ŷ�Χ[0.9995,1]��
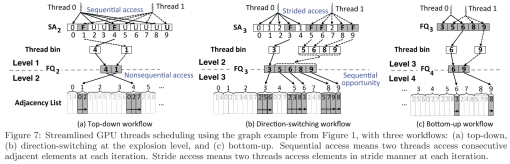
ͼ7 ʹ��ͼ1�е�ʾ�������м�GPU�̵߳��ȡ���a�����϶��£�b����ը��ķ���ת����c�����¶��ϡ�˳�������ζ�������߳���ÿ�ε����з�������������Ԫ�ء��粽������ָ�����߳���ÿ�ε������Կ粽��ʽ����Ԫ�ء�
����෴�����2��ʾ���ִ�CPU�м�ʮ��ӵ�о��нϴ��L3����ͽ϶̵ķ����ӳٵ�������ں˺��̡߳����˵��ǣ������ļĴ����Ϳ����������Ĺ����ڴ�(L1����)�����ֲ�GPU��ȫ���ڴ��ϵIJ��㣬���������������BFS�������ڴ��ܼ����㷨��
����CPU���Ե�����BFSʹ��״̬����֧��δ���ʵĶ���ļ�飬�Զ����º��Ե�����֮��ķ����л�ȡ����δ̽���ıߵ���������Enterprise�У�����GPU���Ե�����BFS����һС���Ϊ���Ķ���ĸ߶����ӵĶ��㡣��ʽ�ϣ����Ƕ���һ�����Ķ������¡�
����(���Ķ���):��v��ͼG��һ������ .���嶥��v��һ�����ģ�������ij��ȴ�����ֵ�ӡ�
������ͼ�����,����,��Twitte�У���Ϊ100 K s������ͼ���������Ķ�������������������Ǻܳ����ġ�ͼ6��ʾ�����бߵ�CDF�Ͷ��㷶Χ[99.95%��100%]�ķŴ���ͼ������YouTubeͼ�����Կ���330��hub����(���� 0.03%�Ķ���)ӵ�����бߵ�10%�����Ƶأ�Kron-24-32�е�770��hub����(0.005%)ӵ�����бߵ�10%��Wiki-Talk�е�96��hub����(0.004%)ӵ�����бߵ�20%��
���ǻ���gpu���Ե����ϵ�BFS����ص�����Ϊ:1)Enterprise�ڱ�����˵�ı�ը������һ����Ҫ���ʴ��������ĵ㣩���з����л�����������У����Ƿ��ֱ߽����������Ķ��������������Ϊ���õķ����л���ָʾ�����߿��Ժ�������GPU��ʵ�֡�����Ҫ���ǣ��������Ķ�����Ե����ϵ�BFS�dz����档
4. Enterprise:����GPU��BFS
4.1��GPU�̵߳���
���״̬����ͱ߽����е�ǿ���ܣ�Enterprise����ͨ��ɨ��״̬������ÿһ�����ɱ߽����У��Ӷ�ʵ�ֶ�GPU�̵߳������͵��ȡ���ÿ������ϣ�Enterprise����������[36,24]�ķ�ʽʶ��߽�㲢����״̬���顣��ɴ˲����Enterprise������GPU�߳�ɨ��״̬�����еĶ��㡣������һ���߽��ʱ�����߳̽����������洢�����Լ����߳̿��С������߳̿ⶼ�洢��ȫ���ڴ��С���������ʹ��ǰ�ͼ���ÿ�����ڱ߽������е�ƫ����[34,22]�����ÿ�����еı߽�㲢�и��Ƶ������С���֮�������߳�ͬ��(ʹ������)�ͼ�����һ��Ŀ����߳�(ʹ�ö���)�ĺô����Զ����ġ�Ȼ��������������չʾ�ģ�BFS�ķ���ᵼ����ÿ���ϱ߽�������ľ���졣
Ϊ�ˣ�Enterprise�ƻ�ʹ������GPU�߳������Զ����¡������л����Ե����ϵĶ������ɹ����������Ż���������µ��ڴ���ʡ�״̬���顢ǰ�ض��к��ڽӱ�פ����GPUȫ���ڴ��У��������ȫ���ڴ�ֻ��ʵ��3%��������ȡ������Ϊ������������ܣ��Ż�BFS��ͬ�εķ���ģʽ������Ҫ��
���϶��µĹ�����������������ϣ�Enterpriseʹ��GPU�߳��Խ����ķ�ʽɨ��״̬���顣����ͼ7(a)�е�ʾ�����ڵ�1�������������߳�:�߳�0���5������{0,2,4,6,8}��״̬�����߳�1��������Ķ���{1,3,5,7,9}���ⲿ�ֹ���ִ��˳������ڴ��е�״̬���顣��ǰ�����ʱ���߳�0��1�������ؽ������Լ����߳̿⸴�Ƶ�FQ2�С�����������£�FQ2����������ı߽�洢Ϊ{4,1}���⽫�ڵ�2�������˳���ڴ���ʣ���BFS�ڶ���1֮ǰ���ʶ���4���ڽӱ������˵��ǣ�״̬����˳����ʵĺô��������ڽӱ�������ʵ�DZ��ȱ�㡣�����Զ����£�״̬���������ڵĶ��㲻̫���ܳ�Ϊͬһ����ı߽磬��Ϊֻ������(ƽ��0.4%)�ı߽磬��ͼ4(b)��ʾ��


ͼ8:Facebook��ըʽ��չǰ���GPU�̵߳��Ⱥ�������ƽ���ִ��ʱ���ߡ�
�����л� (explosion-level)�����������������ͬ�������GPU�̱߳����䵽״̬������ض����ֽ���ɨ�衣ʹ����ͬ��ʾ�����ڵ�2�������ٴ�ʹ�������߳�:����߳�0���5������{0,1,2,3,4}��״̬�����߳�1���5������{5,6,7,8,9}��״̬�����Զ����µĹ�������ͬ�����ַ�����ɨ���ڼ�ᵼ�¿����ڴ���ʡ������������߳̿���ִ��ǰ�ͣ��ڱ����У�FQ3��{3,5,6,8,9}��ɡ���������������(�Ե�����)�߽���ܰ�˳������ڶ����У��Ӷ�������һ���˳���ڴ���ʡ��ڱ�ը�������ڵĶ���ܿ��ܶ���δ���ʵģ���Ϊ�����������ͼ4(b)��ʾ��������������������ʵ��������һ��ı��������磬�ڵ�4�㣬���ض���5��6���ڽ��б���˳����ڽ��ڴ���ʣ�����8��9Ҳ����ˡ�
�ڱ�ը�IJ�����, ��������϶��µĹ����������ַ���������ƽ��2.4����ʱ��ɨ��״̬���顣���磬�ں����룬ʹ���Զ����¹������ı�ը������Ҫ0.57 ms�����֮�£�ʹ�÷���ת�������������Ѹ�����ʱ��0.86 ms�������ַ�����ʹ��һ�����������ƽ�����37.6%�����磬�ڱ�ը����ļ����ϵ�Hollywood ����ʱ�佫��2.7 ms���ٵ�2 ms�����ں�һ��������Ҫ������wall clockʱ�䣬���������ͼ�У���������ƽ�������16%���ϣ�����Facebook�ĸĽ�������ﵽ33%��
�Ե����ϵĹ��������ؼ��ļ����ǣ������Ե����ϣ���ǰ��Ķ���ʼ����ǰһ�����е��Ӽ�����Ϊ�߽�ʼ����δ���ʵĶ��㡣����û�м���ʹ��״̬���飬����ֱ��ʹ��ǰһ��ı߽����������ɵ�ǰ��Ķ��У���ͼ7(c)��ʾ������ͨ��ɾ�����ڵ�ǰ����Ķ�������ɵġ����ַ���������ɨ������״̬�������Ҫ����ÿ����ֻ���һ��С��(����������)�Ӽ������磬�ڵ�3����FQ4��ͨ����FQ3��ɾ������{3,5,8}�������ġ����ǵIJ��Ա��������ַ����ڲ�ͬ��ͼ�����ṩ��3%�ĸĽ���
�ܶ���֮�����ּ��������˻�Ծ�ڱ߽��ϲ������ڴ����/�洢�����GPU�̵߳����������ǽ���ʵ���п����ڴ����/�洢������Ԫ��������������ߡ�ʹ��������,�����ڲ�ͬ��ͼ����Ȼ���ɵĺܿ죬��ʱ2.2ms��53.7ms,Լռ�����BFS������ʱ��11%,�ṩ��2����37.5���ļ��١�ͼ8��ʾ��Facebook��ըʽ����ʱBFS��ִ�й켣����Ȼ����������ǰ�ض�����Ҫ23.6 ms������������һ�����õĹ������У����̵߳��Ƚ���չ�ͼ�������ʱ���490 ms���ٵ�419 ms������ʡ46 ms��
4.2 GPU�������ؾ���
���ڣ�Enterprise���Կ����������õ�ǰ�ض��У�����������лᵼ�¹������ز�ƽ�⣬��ô���潫����С�ġ���������У�������Ϊ�ڴ�ǰ�ض��е��ȹ���ʱ��Ӧ������GPU�IJ������ȣ���ȷ���ϸߵ��̼߳������ԡ���������£�ÿ���̣߳������Ƿ��������warp��CTA�У���ÿһ�㶼Ӧ���е����Ĺ���(չ���ͼ��)��Ϊ��ʵ����һĿ�꣬Enterprise���ݱ߽��ij���(DZ�ڵĹ�������)�Ա߽����з��࣬������ƥ��IJ������ȡ�����ǰ�Ĺ�����ͬ��Enterprise��������warp��CTA��ʹ���߳�[23,33]��������ͼ�еĴ�������㶼����С�ij�����һ��ʵ����ɵġ������о���ͼ��˵��С��32���ߵĶ����ƽ���ٷֱ���68%����Twitter�Ͽ��ܸߴ�96%��
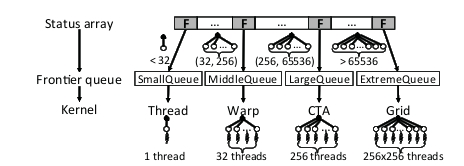
ͼ9:GPU��������ƽ�⡣
Enterprise����ÿ���߽�ij��ȣ���ǰ�漼�����ɵı߽绮��Ϊ�ĸ�����:SmallQueue��middle queue��LargeQueue��ExtremeQueue��������˵��С�����еı߽��С��32���ߣ�MiddleQueue��32��256����֮�䣬LargeQueue��256��65,536��֮�䣬Extreme-Queue��65,536�����ϡ��ڱ߽���������ڼ䣬ÿ���̸߳������ǵij��Ƚ����ֵı߽������ĸ��߳̿��е�һ��������һ���У�������4���߳�������ͬ���ں�(�̡߳�warp��CTA��grid)�ڲ�ͬ��ǰ�ض����Ϲ�������ƽ���߳�֮��Ĺ������أ���ͼ9��ʾ�������ں˶���ʹ��Hyper-Q֧�ֲ���ִ�еġ�
����ά��һ����ֵ�������������и߳��ȵĶ��㡣���磬KR2�е�һ�������г���250�����ߡ����ָ��һ��CTA�����������㣬������Ҫ10,000�����ϵĵ���������������ͼ5��ͼ6�п����ij�βһ�����������͵Ķ������������ͼ�С������Щ����չ������Ҫ�൱��������ʱ�䣬�������������������ܻ����ӳ�����ı���ʱ�䡣ʹ������grid���Դ��ӿ�ִ��,����,��KR0ʵ����1.6x���١�
��ͼ8(b)��(c)�У����Կ�����������ƽ��ǰ������ʱ�ı仯��ͬ�������������Ż���������5 ms�Ŀ������Ա߽���з��࣬���������ܹ����������������ʱ�䣬��419 ms���̵�76.5 ms���ر����߳��ں���Ҫ63.5 ms��Warp ��Ҫ17.8 ms��CTA�ں���Ҫ10.5 ms���������ں�֮��������Ե��ص��������֮������ǰ�ķ�����ȣ����ּ�����һ��������ÿ��CTA��warp�еĿ����̣߳����һ�ּ������ƣ��⽫����GPU�ڴ浥Ԫ�ĸ��������ʡ�
4.3����Hub������Ż�
�����л����������������,���Ƿ��ֵ��Ų�������������ʱ�����϶����л������¶����Ƿ����ġ��෴���������Ķ����ڱ�ը������ռ�ܴ���������ǽ���ʹ�ñ߽���������Ķ���ı�����Ϊ�����л���ָʾ�������Ƕ�������õ���ʽ����Ϊ:
��= Fh/Th��100% (1)
����Fh�DZ߽������hub���������(ÿ���ռ�)��Th��ʾhub������������������ڵ�һ��dz����ٵؼ��㡣���ǵ�ʵ�����,�����ȶ�������Ҫ�ֶ�������ͼ10��ʾ������ͼ�ڦá�(30��40)%ʱӦ�л�����,����ڦ���2��200֮�䲨������һ���dz�С�ķ�Χ�����������,�������÷����л�������Ϊ�ô���30��
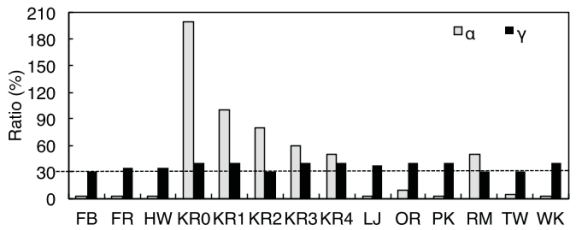
ͼ10:�����л������ıȽϡ�
Enterpriseƽ���ڲ�ͬ��ͼ���Զ����±���4�㣬�Ե����ϱ���8�㣬��֮ǰ�ķ���[10]���˴�Լ1�㡣��Kroneckerͼ��,ʹ�æ�����ֱ����Զ����º��Ե����ϵ�4%��17%�ı�,�����˷�������79%�ı�Ե��ʹ�û����������Ķ�������ý�����Զ����º��Ե����ϵ�1%��36%�ıߡ�էһ����Enterprise�������ı�Ե���Ӷ���Ч�ʡ����˵��ǣ�����������չʾ�ģ������л������������Ķ�����Ƶı�ը�㣬���Ե����ϱ������ص���ʶ�����ӱ߽絽������ʵ����Ķ���ıߡ���ˣ����Ķ�������û���dz��ʺ������ֳ�����
���Ķ��㻺�档��������У����ǽ����ڷ����л����Ե�����ʱ����hub���㻺�浽GPU�����ڴ��У�����Դ�����ȫ���ڴ���ʵĿ��������ֺô��ǿ�ʵ�ֵģ���Ϊ�Ե����ϵĴ����߽�ܿ������ӵ����Ķ��㡣Ȼ��,��ΪGPU�����ڴ��С(64 KB),������Ҫ��ϸƽ�����Ķ��㻺���������GPU��ռ���ʣ�����Ϊ������һ��SMX�ϵĻ�Ծ��warp��һ��SMX�����Ͽ���֧��warp���������(64��)�ı���)�����һ��grid����256��256���߳�,K40��ζ������8�� CTA�Ļ�ռ��һ������������,���ÿ��CTAֻ��6 KB�����ڴ������춥�㻺�棬�ɴ�Լ1000�����ġ�
Hub���㻺��(HC)������ʵ�֡����ȣ��ڱ߽���������ڼ䣬Enterprise������һ��ոշ��ʹ��Ķ����id����Щ����idҲ���нϸߵij��ȡ�����ʹ��һ����ϣ����������洢ÿ������ID����������HC[hash(ID)] = ID����Σ��ڱ߽�ʶ������У�Enterprise����ر߽����ڽӵ㣬������Ƿ����κ��ڽӵ�Ķ���ID���������������齫��ǰ��ֹ��������ڽӵ㽫����ʶΪ�ñ߽�ĸ��ڵ㡣����������£����潫������ʸ��ڽӵ���ȫ���ڴ��е�״̬��
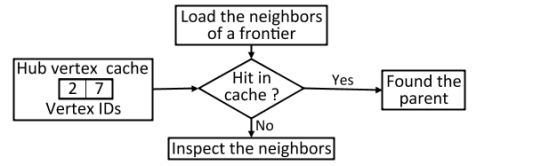
ͼ11:Hub���㻺����ƣ�ʹ��ͼ1ʾ��ͼ�еĵ�4��������
ͼ11չʾ��hub���㻺��Ĺ��������ڱ����У�Enterprise������id{2,7}����hub���㻺���У���Ϊ��������������ǰһ����ʵģ����Ҿ��нϸߵij��ȡ��ڵ�ǰ����Enterprise���ض���3���ڽӵ�{2,5,6}���м�顣������2������ʱ��Enterprise���Ѷ���2���Ϊ����3�ĸ��ڵ㣬����ֹ��顣��һ���棬�����6�����ı߽��û�л�����ڽӵ㣬Enterprise���������פ����ȫ���ڴ��е��ڽӵ��״̬����ͼ12��ʾ��hub���㻺���ڸ���ͼ�Ϸdz���Ч����ʡ��10%��95%��ȫ���ڴ���ʡ�ֵ��ָ�����ǣ��������Ķ�������Զ�����BFS�ĺô����ޣ���Ϊ���������������Ķ�����١�
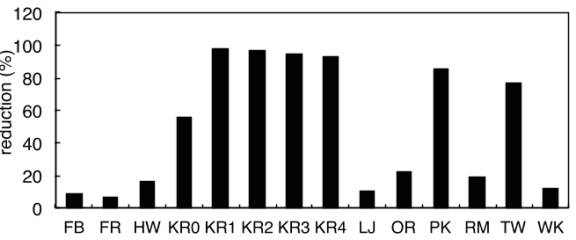
ͼ12:���ĵ㻺�滺�������ȫ���ڴ���ʡ�
4.4 ��GPU��Enterprise
Enterprise����һά���ַ���[11]��ͼ�ֲ��ڶ��GPU�ϡ������˵��ÿ��GPU����ͼ����ͬ�����Ķ��㣬���Ҳ�������������ıߡ����ǰѶ�ά���ֵ��о������Ժ��������ڱ��������У�Enterprise��Ϊ��������:(1)ÿ��GPUͨ����˽�еı߽�����չ������ʶ˽��״̬�����еĵ�ǰ���㡣(2)���е�GPUͨ�����ǵ�˽��״̬���飬�Ի��������ʶ����ȫ����ͼ������һ���У�ÿ��GPUʹ��һ��CUDAָ��__ballot()��˽��״̬����ѹ��Ϊһ��λ���飬����һ��λ����ָʾһ�������Ƿ����ˡ�����ѹ����ͨ�����ݵĴ�С������90%��(3)ÿ��GPUɨ����º��˽��״̬���飬�����Լ���˽��ǰ�ض��С�
5. ʵ��
�����Ѿ���C++��CUDA��3000�д�����ʵ����Enterprise��Դ����ʹ��NVIDIA nvcc 5.5��GCC 4.4.7���룬�Ż���־ΪO3����������У�����ʹ������GPU: NVIDIA Kepler K40, K20��Fermi C2070�����Ƕ����1��ʾ��ͼ�����˲��ԡ����е�ͼ����ѹ��ϡ����(CSR)��ʽ��ʾ���ṩ�ߵ�Ԫ������ݼ�ת��Ϊ��CSR��ʽ��������Ԫ������С��������ͼ����������ģ�����Twitter��Facebook�����Dz�ִ����ɾ���ظ��ı�Ե����ѭ����Ԥ�������������ݶ���uint64���ͱ�ʾ���������ص�GPU��ȫ���ڴ��С���ʱ��ʼ�������źű�����GPU�ں�ʱ����������ɲ�д��GPU�ڴ�ʱ����ʱ����������ÿ��ʵ�飬������α���ѡ��Ķ���������BFS 64�Σ���������ƽ��ֵ��ÿ������ı�(TEPS)��������:��mΪ�������������������������������ߺ���ѭ����tΪ����BFS���������ѵ�ʱ�䡣Ȼ����m/t����TEPS��
5.1Enterprise����
���ڻ���ԭ�Ӳ�����ǰ�ض��л����ö࣬�������ʹ��״̬���鷽����Ϊ����(BL)ʵ���˷����Ż�BFS�����������ʹ��CTA����״̬�����е�ÿ�����㣬��ȷ����̻߳�warpҪ��öࡣͼ13�����ÿ���Ż����������ܸĽ�������������GPU�̵߳���(TS)��GPU��������ƽ��(WB)�����Ķ��㻺��(HC)��
�����е�ͼ�ϣ������͵� GPU�̵߳����ǻ����ٶȵ�2x��37.5�����ر��ǣ�Twitter (TW)��������ļ��٣���0.4��TEPS���ӵ�15��TEPS��ԭ����Twitter�����߽�����ֻ��10.2%��ƽ��ÿ������ֻ��1%�ı߽�㡣Kron- 20 - 512 (KR0)����2������,�ﵽ340��TEPS��һ����˵�����ɱ߽�����ƽ������BFS����ʱ��11%��
GPU�Ĺ�������ƽ�⼼���ӿ�������ͼ�ı����ٶ�2������,�ڵ�һ��������ƽ��2.8��������,LiveJournal (LJ)�ﵽ4.1�����ĸĽ�,��9��TEPS��37��TEPS�������ͼ�У��ܹ��������Ǿ��ȷֲ��ģ����SmallQueue����78%�ı߽��(��22%�Ĺ�������)��MiddleQueue����21%�ı߽�(��58%�Ĺ�������)��LargeQueue����1%�ı߽�(20%�Ĺ�������)��
���Ķ��㻺�漼���ɰ������������55%��Facebook (FB)��Friendster (FR)����һ��С���ջ���Ϊ���Dz��������ȼ��ߵĶ��㣬����Facebook����������9170����������ͼ���Ľ����ȳ���10%������ӵ����ǧ�����㡢����105���ߵ�Kroneckerͼ���Ľ����ȸߴ�30%��50%�������������Щ���Ķ����Ƿdz�����ġ�
��֮,Enterprise�����BFS�㷨��TEPS 3.3����105.5������ߵ�TEPS��KR0�дﵽ������760��TEPS����С����FR�дﵽ��Ϊ31��TEPS��
�Ƚϡ�ͼ14�Ƚ���Enterprise�뼸�ֻ���GPU��BFSʵ�֣�����B40C[33]��Gunrock[44]��MapGraph[18]��GraphBIG[2]����������������ͼ����FB��TW��KR-21-128������200������㣬ƽ��ÿ������ij���Ϊ128���Լ���ֱ��ͼ����audikw1[7]��roadCA[6]��europe��osm [7]��
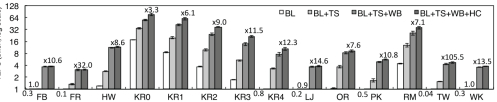
ͼ13:����ͼ�ϵ�Enterprise��Ч����GPU��ʹ��״̬���鷽����BFS���з����Ż���Ϊ����(BL)�����ּ����ֱ�Ϊ����������GPU�̵߳��ȵ�TS�����ڹ�������ƽ���WB���������Ķ��㻺���HC��
��������ͼ,Enterprise�ֱ��B40C ��Gunrock�� MapGraph��Graph-BIG��4����5����9����74x�����ڳ�ֱ��ͼ,Enterpriseƽ���ﵽ14.1��TEPS������Gun-rock (0.72) 1.95��������MapGraph (0.25) 5.56��������GraphBIG 42��(0.03)������Щͼ�У�Enterprise����������������B40C������europe.osm�ϵ������ٶ���������Ϊ���ͼ�ij��Ⱥ�С�����ij�����12��ƽ��ֵ��2.1��
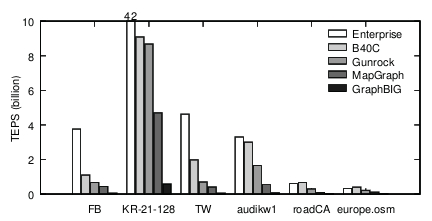
ͼ14:���ܱȽ�
5.2Enterprise�Ŀ���չ��
ͼ15��ʾ��Enterprise��ǿ����չ�Ժ�������չ�ԡ�����ʹ�ñ�1������ͼ����KR4������ǿ����չ�ԡ���2��4��8��gpu�ϣ�Enterprise�ֱ�ʵ����150��180��184��TEPS��������43%��71%��75%��
���������ַ���������������չ�ԣ��߳߶ȺͶ���߶ȡ���GPU������ʱ�����ǹ̶�������ͬʱ���ӱ����ӡ���ƽ�����ȣ�����ʹ�ù̶�ƽ��������ͬʱ���Ӷ������������ͼ15��ʾ,�����ڱ߳߶��ϻ�ø��õĿ���չ��,���ǻ�ó����Լ���,Ҳ����˵,9.1����960��TEPS�� 8 GPU�ϡ�������Ϊ��edgeFactor����ʱ��ͼ�����Ķ��������Ҳ�����ӣ����Ķ��㻺�潫���ٸ����ȫ���ڴ���ʡ���һ���棬�����л����Ա�������Ҫ�ı�Ե��顣
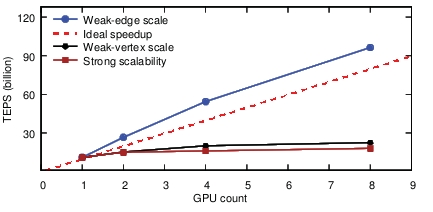
ͼ15:Enterprise��ǿ�������Ժ����������ԡ�
5.3 GPU����������
����BFS��һ��I/ o�ܼ����㷨�����GPU�߳��ܹ����ٷ�������������Ҫ����ͼ16(a)��ʾ�����ǵ�ǰ�ؼ���(TS��WB)���������GPU��ȡ/�洢���ܵ�Ԫ�������ʣ�ƽ���ֱ������8%��24%����߿ɴ�68%�����⣬���ǵ����Ķ��㻺��(HC)��ͼ16(b)��ʾ��������40%�����������ӳ٣������¼��ķ����ʴ�4.8%�½���2.9%����Ҳ������ͼ16(c)����GPU�Ϲ۲쵽��IPC��������
Ϊ�˱��ڱȽϣ����ǻ���Hollywood graph�϶�[33]�������������ڸ�ͼ����Ч��Ϊ27��TEPS������40�߹��ʣ�ʵ����40%�ĸ���/�洢��Ԫ�����ʺ�0.68 IPC����ͬһͼ�У�Enterpriseʵ����50%�ĸ���/�洢��Ԫ�����ʺ�1.32 IPC��ӵ��120��TEPS��Ч�ʺ�76�ߵĹ��ġ�
ͼ16(d)Ϊ��ͬ������Ӧ��GPU����ͼ����������ֻ����GPU�Ĺ������˽�ÿ�ּ����������������ǵ�GPU�̵߳����£�ƽ�����Ĵ�86���½���81�ߣ����Ľ�ʡ��Twitterͼ�ϣ���14.5�ߡ�����Ҫ����ϵͳ�и��õ�IO���ܺ��ٵĿ���GPU�̡߳��������ּ���(WB��HC)��һ�������ʽ��͵�78�ߡ�
6. ��ع���
���ǵ�ϵͳEnterprise��ͼ��������ƺ�ʵ�ַ��洦������ˮƽ����ǰ�Ĺ���Ҫôʹ��ǰ�ض���[30,33]��Ҫôʹ��״̬����[24]����ʹһ��ʹ�����������ݽṹʱ�����еĽ������Ҳ���ڲ�ͬ�ĵط�ʹ�����ǣ����磬[36,29]����չ��ʹ��״̬�������������ʹ��ǰ�ض��з�����[10]�Լ������϶��·�����ʹ��ǰ�ض��У����¶��Ϸ�����ʹ��״̬���顣Enterprise��ʼ���ն���ͬʱʹ�����������ݽṹ������GPU���ṩ��ǰ��δ�е����ܡ�
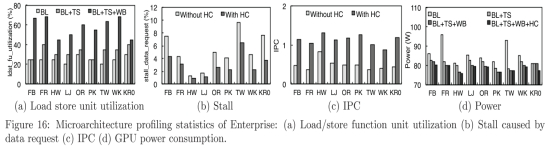
ͼ16.Enterprise���ṹ��ͳ�����ݣ�a������/�洢���ܵ�Ԫ�����ʣ�b�����������������ͣ�٣�c��IPC��d��GPU���ġ�
�������˼�������GPU�Ĺ�������ƽ�⼼������������ȡ[15,12]�������ؾ���[41,14]��Ȼ�����������͵ļ���ͨ��ֻ��һС�����߳���ʹ�ã������ǵĹ����У�����ǧ���߳�֮�����Э���Ǽ�����ս�Եġ��෴��Enterprise��BFS�������ز�ƽ��ĸ�Դ�����Բ�ͬ�ı߽�����з��࣬�Լ������⡣
��������Ŀ[39,20,38]�������Ķ���������ͨ�ſ������ر����ڷֲ�ʽBFS�С����磬[39]��ÿһ�㸴�����л����ϵ����Ķ����״̬��[20]��[38]�����Ķ��㻮��Ϊ������������Ի������ķ�ʽ����ͨ�š����֮�£���Χ�����Ķ���չ���ͼ��ʱ��Enterpriseֻ֧���Ե����Ͻε����Ķ��㻺�档���⣬����GPU�����ڴ������ģ�Enterprise��ÿһ�㶼ʹ������һ�����п��ܷ��ʵĶ�����»��档
����Ч��[45]����ϵͳ��Ʒdz���Ҫ����[43]��ǰ�ر�GPU���������Խ�ʡ���ʡ����ǵĹ�������������GPU ��ͼ�㷨���ṩ�����ܺ���Ч������о��DZ����
7. ����
��������У����ǿ�����һ���µĻ���GPU��BFSϵͳEnterprise����ϵͳ��һ��GPU�Ͽ��Բ�������700��TEPS��������GPU�Ͽ��Բ���1220��TEPS�����Դﵽ4.46��TEPS/�ߡ�����ͨ����Ч�����ڶ��GPU���������Ͷ��ص��ڴ�����ʵ�ֵġ���Ϊδ��������һ���֣����Ǽƻ���Enterprise����ٴ洢�������豸���ɣ����ڸ����ͼ�����С�
��л
���Ǹ�л��������˵����潨�顣����ҲҪ��лӢΰ���ѧ����������Ӳ�������������ϻ��ڲ����ɹ��ҿ�ѧ�����ְҵ��CNS-1350766�ͽ�����IOS-1124813֧�ֵ��о���
8. �����
[1]Graph500. http://www.graph500.org/.
[2]GraphBIG. https://github.com/graphbig.
[3]GTgraph: A suite of synthetic random graph generators. http://www.cse.psu.edu/~madduri/software/GTgraph/.
[4]NVIDIA Corporation: CUDA C Programming Guide.
[5]NVIDIA Profiler Tools. http://docs.nvidia.com/cuda/profiler-users-guide/.
[6]SNAP: Stanford Large Network Dataset Collection. http://snap.stanford.edu/data/.
[7]The University of Florida: Sparse Matrix Collection. http://www.cise.ufl.edu/research/sparse/matrices/.
[8]NVIDIA Corporation: Kepler GK110 Architecture Whitepaper. 2013.
[9]R. Albert, H. Jeong, and A.-L. Barab´asi. Internet: Diameter of the World-Wide Web. Nature, 401(6749):130�C131, 1999.
[10]S. Beamer, K. Asanovi´c, and D. Patterson. Direction-Optimizing Freadth-First Search. In Proceedings of the Conference on High Performance Computing, Networking, Storage and Analysis (SC), 2012.
[11]E. G. Boman, K. D. Devine, and S. Rajamanickam. Scalable Matrix Computations on Large Scale-Free Graphs Using 2D Graph Partitioning. In Proceedings of the Conference on High Performance Computing, Networking, Storage and Analysis (SC), 2013.
[12]D. Cederman and P. Tsigas. On Dynamic Load Balancing on Graphics Processors. In Proceedings of the SIGGRAPH/EUROGRAPHICS Symposium on Graphics Hardware, pages 57�C64. Eurographics Association, 2008.
[13]D. Chakrabarti, Y. Zhan, and C. Faloutsos. R-MAT: A Recursive Model for Graph Mining. In SDM, volume 4, pages 442�C446. SIAM, 2004.
[14]A. Cohen, T. Grosser, P. H. Kelly, J. Ramanujam, P. Sadayappan, and S. Verdoolaege. Split Tiling for GPUs: Automatic Parallelization Using Trapezoidal Tiles to Reconcile Parallelism and Locality, avoiding Divergence and Load Imbalance. In Proceedings of Workshop on General Purpose Processing Using GPUs (GPGPU), 2013.
[15]J. Dinan, D. B. Larkins, P. Sadayappan, S. Krishnamoorthy, and J. Nieplocha. Scalable Work Stealing. In Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis (SC), 2009.
[16]S. Dolev, Y. Elovici, and R. Puzis. Routing Betweenness Centrality. Journal of the ACM (JACM), 57(4):25, 2010.
[17]D. Easley and J. Kleinberg. Networks, Crowds, and Markets: Reasoning About A Highly Connected World. Cambridge University Press, 2010.
[18]Z. Fu, M. Personick, and B. Thompson. MapGraph: A High Level API for Fast Development of High Performance Graph Analytics on GPUs. In Proceedings of Workshop on GRAph Data management Experiences and Systems (GRADES), 2014.
[19]M. Gjoka, M. Kurant, C. T. Butts, and A. Markopoulou. Practical Recommendations on Crawling Online Social Networks. Journal on Selected Areas in Communications, 29(9):1872�C1892, 2011.
[20]J. E. Gonzalez, Y. Low, H. Gu, D. Bickson, and C. Guestrin. PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs. In Proceedings of USENIX conference on Operating Systems Design and Implementation (OSDI), 2012.
[21]P. Harish and P. Narayanan. Accelerating Large Graph Algorithms on the GPU using CUDA. In High Performance Computing (HiPC). Springer, 2007.
[22]M. Harris, S. Sengupta, and J. D. Owens. Parallel Prefix Sum (Scan) with CUDA. GPU gems, 2007.
[23]S. Hong, S. K. Kim, T. Oguntebi, and K. Olukotun. Accelerating CUDA Graph Algorithms at Maximum Warp. In Proceedings of SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2011.
[24]S. Hong, T. Oguntebi, and K. Olukotun. Efficient Parallel Graph Exploration on Multi-Core CPU and GPU. In Proceeding of the Conference on Parallel Architectures and Compilation Techniques (PACT), 2011.
[25]B. A. Huberman and L. A. Adamic. Internet: Growth Dynamics of the World-Wide Web. Nature, 401(6749):131�C131, 1999.
[26]H. Jeong, B. Tombor, R. Albert, Z. N. Oltvai, and A.-L. Barab´asi. The Large-scale Organization of Metabolic Networks. Nature, 407(6804):651�C654, 2000.
[27]H. Kwak, C. Lee, H. Park, and S. Moon. What is Twitter, A Social Network or A News Media? In Proceedings of International Conference on World Wide Web (WWW), 2010.
[28]D. Levinthal. Performance Analysis Guide for Intel Core i7 Processor and Intel Xeon 5500 Processors. Intel Performance Analysis Guide, 2009.
[29]D. Li and M. Becchi. Deploying Graph Algorithms on GPUs: An Adaptive Solution. In International Symposium on Parallel & Distributed Processing (IPDPS), 2013.
[30]L. Luo, M. Wong, and W.-m. Hwu. An Effective GPU Implementation of Breadth-First Search. In Proceedings of Design Automation Conference (DAC), 2010.
[31]K. Madduri, D. Ediger, K. Jiang, D. A. Bader, and D. Chavarria-Miranda. A Faster Parallel Algorithm and Efficient Multithreaded Implementations for Evaluating Betweenness Centrality on Massive Datasets. In International Symposium on Parallel & Distributed Processing (IPDPS), 2009.
[32]A. McLaughlin and D. A. Bader. Scalable and High Performance Betweenness Centrality on the GPU. In Proceedings of the Conference on High Performance Computing, Networking, Storage and Analysis (SC), 2014.
[33]D. Merrill, M. Garland, and A. Grimshaw. Scalable GPU Graph Traversal. In Proceedings of SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2012.
[34]D. Merrill and A. Grimshaw. Parallel Scan for Stream Architectures. Technical report, University of Virginia, 2009.
[35]R. Nasre, M. Burtscher, and K. Pingali. Atomic-Free Irregular Computations on GPUs. In Proceedings of Workshop on General Purpose Processor Using GPUs (GPGPU), 2013.
[36]R. Nasre, M. Burtscher, and K. Pingali. Data-Driven Versus Topology-Driven Irregular Computations on GPUs. In International Symposium on Parallel & Distributed Processing (IPDPS), 2013.
[37]P. W. Olsen, A. G. Labouseur, and J.-H. Hwang. Efficient Top-k Closeness Centrality Search. In International Conference on Data Engineering (ICDE), 2014.
[38]R. Pearce, M. Gokhale, and N. M. Amato. Scaling Techniques for Massive Scale-Free Graphs in Distributed (External) Memory. In International Symposium on Parallel & Distributed Processing (IPDPS), 2013.
[39]Z. Qi, Y. Xiao, B. Shao, and H. Wang. Toward a Distance Oracle for Billion-Node Graphs. Proceedings of the VLDB Endowment, 7(1):61�C72, 2013.
[40]A. E. Sarıy��uce, E. Saule, K. Kaya, and ��U. V. Cataly��urek. Regularizing Graph Centrality Computations. Journal of Parallel and Distributed Computing, 2014.
[41]S. Tzeng, A. Patney, and J. D. Owens. Task Management for Irregular-Parallel Workloads on the GPU. In Proceedings of the Conference on High Performance Graphics, 2010.
[42]V. Ufimtsev and S. Bhowmick. Application of Group Testing in Identifying High Betweenness Centrality Vertices in Complex Networks. In Workshop on Machine Learning with Graphs, KDD, 2013.
[43]P.-H. Wang, Y.-M. Chen, C.-L. Yang, and Y.-J. Cheng. A Predictive Shutdown Technique for GPU Shader Processors. Computer Architecture Letters, 2009.
[44]Y. Wang, A. Davidson, Y. Pan, Y. Wu, A. Riffel, and J. D. Owens. Gunrock: A High-Performance Graph Processing Library on the GPU. In Proceedings of SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2015.
ȫ�ױ�ҵ��������ֳɳ�Ʒ��������ѯ
