分布式异构数据库的同步机制研究
摘要 对于不同的物理位置分布的异构数据库,它是如何保证异构数据库的用户数据同步是一个非常关键的问题。本文为分布式异构数据库和提取模块,数据集成模块,数据更新模块分析数据同步系统,并且提出了解决方案的具体实现。
关键字 数据同步机制;最小变化集;最小更新集
一、前言
分布式异构数据库系统的研究是综合了不同类型的数据库系统的应用研究,研究的主要方向之一是分布式异构数据库系统之间的数据同步。设计数据同步的目的是为了使异构数据库的系统表数据与每一个站点数据对应同步。它可根据用户的要求,维持数据的一致性。这种同步没有改变原始异构数据库系统,因此让许多节点自治以实现数据库之间的数据共享是可以实现的。
二、分布式异构数据库同步机制的理论分析
异构数据库的数据同步的根本目的是在不同类型的数据库的不同节点上,保持相同的表数据相同。由于异构数据库系统的自主性,系统使得各个异构数据库中的数据只能由第三方系统维持同步数据传输的一致性。
异构数据库数据同步的实质是,当用户数据在节点数据库上发生变化时,同一时间其他异构数据库也做同样的变化。
同步数据的收集是异构数据库同步机制的基础。它在用户的需求下对于每个需要同步的数据表建立了三个触发器包括INSERT,UPDATE和DELETE触发器。每次当一个用户操作带有触发器的数据表时,触发器将被触发。因此数据库中的这些数据变化可以被发现,通过一个被称为数据库改变集的数据库。
异构数据库同步机制的关键是管理同步数据。目的是根据同步组,当触发器取得同步数据,并根据该同步组以获得变化最小集。再以每个节点的数据库完成不同的操作,这样就获得了各种异构数据库的最小更新集。
异构数据库同步机制里边的得到的更新用的数据,是每一个异构数据库的最小更新集,被用来更新各种异构数据库对应的数据表。
三、用于异构数据库的同步机制的设计
3.1设计数据提取模块
在此以测试表的SQL Server数据库为例,使用触发器来跟踪和提取测试表中的变化集。
如果测试表是遵照数据同步表,来创建test_info_insert数据表和test_info_delete表,但它有一个额外的列,这一列记录与测试表中的系统的当前时间。如果在“触发的内部”写入SQL语句来定义触发器,它就可以将数据集写到test_info_insert数据表和test_info_delete表。
将记录写入test_info_insert数据表的SQL语句如下所示:
1. 提取插入的数据记录:
//创建一个叫做test_insert的触发器
CREATE test_insert TRIGGER ON test
//入触发器的类型为添加触发
FOR INSERT AS
//在test_insert触发器中已经包含了读取从已插入的数据表中读取数据并且把它放入到test_info_insert中
INSERT INTO test_info_insert SELECT * FROM INSERTED
2.提取删除的数据记录
//创建一个叫做test_delete的触发器
CREATE test_insert TRIGGER ON test
//入触发器的类型为删除触发
FOR DELETE AS
//在test_delete触发器中已经包含了读取从已删除的数据表中读取数据并且把它放入到test_info_delete中
INSERT INTO test_info_delete SELECT * FROM DELETED
3.提取更新的数据记录
//创建一个叫做test_ update的触发器
CREATE test_ update TRIGGER ON test
//入触发器的类型为更新触发
FOR DELETE AS
//在test_insert触发器中已经包含了读取从已插入的数据表中读取数据并且把它放入到test_info_insert中
//在test_delete触发器中已经包含了读取从已删除的数据表中读取数据并且把它放入到test_info_delete中
INSERT INTO test_info_insert SELECT * FROM INSERTED;
INSERT INTO test_info _delete SELECT * FROM DELETED
3.2数据集成模块的设计
数据集成的目的是得到所有的异构数据库的最小更新集。因此,它必须首先将所有单个数据库变更集放到系统数据库。然后根据删除同步组中相同记录集,所以它得到总变化最小集,并有不同异构数据库的最小更新集。
在此模块中,它具有四个子模块,它是同步表管理,同步集集中,生成最小变化集,生成最小更新集。同步表管理的主要功能是在系统数据库中建立了同步数据表对应的的表结构,它被用于存储由数据采集模块得到的变化集。同步集集中的主要功能是根据同步组复制各种异构数据库中的数据到系统的数据库中。生成最小变化集的主要功能是处理的修改集的同步组,并删除冗余。生成最小更新集的主要功能是使用所产生的最小变化集区分不同的异构数据库更新集。插入最小变化集的过程如图1所示。插入最小的更新集的过程如图2所示。
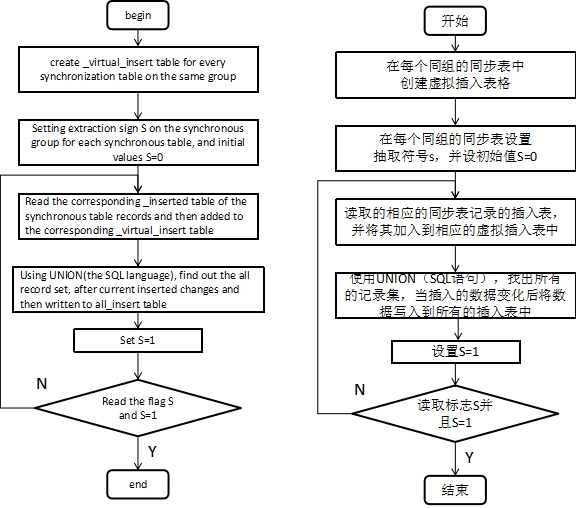
图一 插入最小变化集
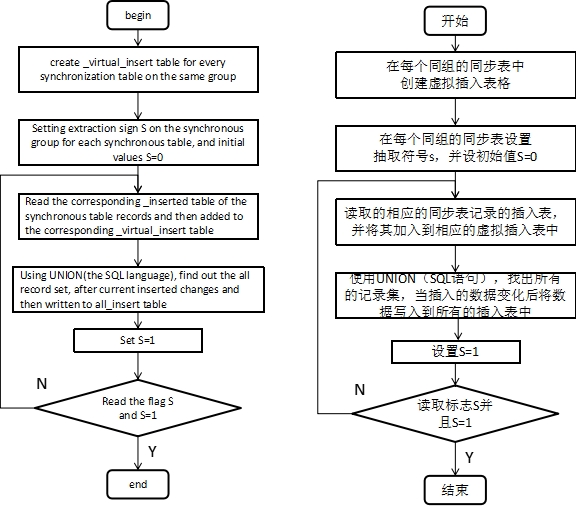
图二 插入最小的更新集
四、总结
数据同步的问题是目前信息管理的一个重要问题,传统的数据库复制技术有许多缺点。本文所提出的同步机制解决了数据的提取和数据更新和最小变化集可以通过减少同步数据来提高系统的效率。因此,我们希望在异构数据库数据同步研究方面提出更多的想法。
参考资料:
[1] WangYiHe etc. Distributed database systems [M].beijing: publishing house of electronics industry, 2008,6.
[2] YanHao distributed database data synchronization technique [J].jnaval engineering university journal, 2007,6 (3) : 11-15.
[3] DingBaoKang. Distributed database system realization technology[M]. Beijing: science press, 2006,8.
[4] huashan etc. SQL Server data replication [M].beijing: higher education press, 2006.
[5] P.S Bernstein. Hipman D and Rothnie j.carol carroll oncurrency. In a Distributed Control System for Database (SDD - 1) [J].j ACM Database System, Trans on 2007,4.
[6] Ceri, s.d. istributed bear - flying and System [J].j McGraw Hill,2006,8. -
[7] Traiger I.L.T ransactions and Consistency in Distributed bear [J].jIEEE Transactions on Software Engineering, 2006,6.
