�ñʻ����ȱ任�����Ȼ�����е��ı�
ժҪ
���������һ���µ�ͼ�����ӣ���Ѱ��ÿ��ͼ�����صıʻ�����ֵ������ʾ������Ȼͼ���ı���������е�Ӧ�á����ǽ��������Ǿֲ��ĺ����������ݵģ���ʹ�����㹻���ٺͽ�׳������Ҫ��߶ȼ����ɨ�贰�ڡ��������Ա������÷����������������¹������㷨�����ļ���ʹ�㷨�ܹ�����������������е��ı���
1. ���
��ɨ���ӡ��ҳ�桢�������Ƭ��ȣ������Ȼͼ���е��ı������������Ӿ�Ӧ�õ���Ҫһ��������������������������ҵ�Զ���������ͳ��л����еĻ����˵����������ں�������м����ı�Ϊ�����Ӿ������ṩ�����������������⣬�о�������ͼ������㷨�����ܹؼ�ȡ�������ı����ģ������ܡ����磬������ķ���������ƣ������ֲ�ͬ����ʵ֤��������������ֽ��м��ͼ�¼��ʵ�����������ֵġ������һЩ�о�[1��2��3��4��5��6��7]�������ı�������⡣�ٰ������ξ���(ICDAR 2003[8]��ICDAR 2005[9]������λ�þ���)����������һ��������״�������Ķ��Խ�����������иĽ������(ICDAR 2005�ı���λ������ʤ���ߣ��ٻ���Ϊ67%����ȷ��Ϊ62%)�����������ǰ�Ĺ�����ͬ����������һ�����ʵ�ͼ�����������������ܹ����ٿɿ��ؼ���ı������ǽ����������Ϊ�ʻ����ȱ任(SWT)����Ϊ����ͼ�����ݴ�ÿ�����ذ�����ɫֵת��Ϊ��������ܵıʻ����ȡ��ɴ˲�����ϵͳ�ܹ�����ı��������������ģ��������������ԡ�
��Ӧ������Ȼ������ͼ��ʱ��OCR�ijɹ��ʼ����½�����ͼ11��ʾ��
���м���ԭ�����ȣ������OCR������Ϊɨ���ı�����Ƶģ������������ȷ�����ı��ͱ������صķָ��Ȼ�����ɨ���ı�ͨ���ܼ�������Ȼͼ����Ҫ���ѵöࡣ�ڶ�����Ȼͼ����ֳ��㷺�ij������������ɫ������ģ�����ڵ��ȡ������Ȼ��ͳ��OCRҳ�沼���Ǽͽṹ���ģ���������Ȼͼ������Ҫ���ѵö࣬��Ϊ�ı�Ҫ�ٵö࣬���Ҵ��ڽ��ٵ�����ṹ���ڼ��κ�����϶��кܸߵĿɱ��ԡ�

ͼ 1: SWT ��ͼ�� (a) �Ӱ����Ҷ�ֵת��Ϊ����ÿ������ (b) �Ŀ�����߿��ȵ����顣����Ϣ����ͨ������ÿ������еĿ��ȷ�������ȡ�ı�, �� (c) ��ʾ, ��Ϊ�ı������ڱ��̶ֹ���߿��ȡ��⽫������������Ҷһ����ͼ��Ԫ�طֿ��������ı���ʾ�� (d) �С�
�����ı��ͳ�������Ԫ�ص�һ���������������㶨�ıʻ����ȡ�������ڻָ����ܰ����ı���������������У�����������һ��ʵ�������������ϼ��������ľֲ�ͼ�������ܹ��ɿ��ػָ��ı��������������Ҫ˼��˵������μ���ÿ�����صıʻ����ȡ�ͼ1c��ʾ�˲�����������������ӳ�����������Ƶ�����з����ı���ʹ���������ļ����������������Ʊʻ����ȵ�λ�ÿ�����ϳɸ���Ŀ����ǵ��ʵ���������������������㷨�����ı��������ͼ����ͼ2��ʾ����ע�⣬���Dz���Ҫ��ʻ�������������ĸ���Ǻ㶨�ģ����������������н�仯��
���ィ��ķ�����ͬ����ǰ�ķ�������Ϊ������Ѱ��ÿ�����صķ����������罥�����ɫ�� �෴�������ռ��㹻����Ϣ��ʵ�����ص����ܷ��顣 �����ǵķ����У����ؽ���ֻ���ھ���aʱ������Ҫ����Ӧ�ķ����ݶȡ��⼸����֤�������˼������ص���������Ϊ�з���ʹ������ͬʱ������һ��С������ԡ� ��������ǰ���о���������һ�����Ų�֮ͬ������û�ж�߶Ƚ�������ɨ�贰�ڣ���Ҫ�������ַ����� �෴������ִ�����¶��ϵ�������Ϣ�������Ʊʻ����ȵ����غϲ�Ϊ���ӵ��������ʹ�����ܹ����ͬһͼ���и��ֳ߶ȵ���ĸ�� �������Dz�ʹ�ü�����ɢ������˲����飬����καʻ����Լ���˵��ı��ߣ�����
����, ���Dz�ʹ���κ��ض������Ե�ɸѡ����, �� OCR ɸѡ�� [3] �����ض���ĸ����صĺ�ѡ�����еĽ��䷽��ͳ�ơ���ʹ�����ܹ����һ�����������ֵ��ı�����㷨��

ͼ 2: ����Ȼͼ���м��ı�
������ÿ���ı�����Ӧ�ö���Ҫ��һ�����ַ�ʶ���衣����Ҫ�����IJ���ʱ, һ���ɹ����ı��ָ���ʶ�������кܴ��Ӱ�졣��ǰ��һЩ�ı�����㷨[3��18��19] ������ͼ������ķ���, ��˲��ṩ���� OCR ������ı��ָ����롣���ǵķ���Я���㹻����Ϣ���о�ȷ���ı��ָ��˺�����Ϊ�����ı��ṩһ���õ����롣
2. ������
��������Ʒֱ���漰����Ȼͼ�����Ƶ֡�м���ı��������������ع����о���������������ȡ��
�����ı���ⷽ�����ۺϵ���[1, 2]��һ����˵, ����ı��ķ������Դ��·�Ϊ����: ���������ķ����ͻ�������ķ��������������ķ���[3��4��18��19��22] �ڶ���߶���ɨ��ͼ��, ���������ı����Զ����������з���, ���Ե�ܶȸߡ��ı��Ϸ����·��ĵ��ݶȡ�ǿ�ȸ߷���ֲ�С���� DCT ϵ���ȡ�������ľ�������: ������Ҫ�������߶���ɨ��ͼ��, �ڲ�ͬ�߶��ϵ���Ϣ��������;��Ȳ���, ���ڹ��е���ʵ, ֻ��С(���㹻��С) �ı�չʾ�㷨��������ԡ�����, ��Щ�㷨ͨ�������㹻��б���ı���
��һ���ı�����㷨��������[5��6��23]������Щ������, ��ʾijЩ���� (����Ƴ�����ɫ) �����ؽ������һ��Ȼ��,�����ɵ�������� (CCs) ���������˲�, ��ʹ�����������ų���һ������ĸ��CCs�����ַ�������������, ��Ϊ���������κγ̶���ͬʱ����ı�, �Ҳ�������ˮƽ�ı������ǵķ���������һ��, ��������ʹ�õ���Ҫ������ͨ��ʹ�õ���ɫ����Ե��ǿ���������кܴ�ͬ�����Dz���ÿ�����ص���߿���, ��������������������Ƶ���߿��Ⱥϲ��� CCs ��, �Ӷ��γ���ĸ��ѡ��
ʹ�����Ƶķ���������ַ��ʻ��Ĺ�����[7]�������Ȼ��, �÷����뱾�����������㷨�к����Ե�������[7]��������㷨ˮƽɨ��ͼ��, Ѱ�Ҷ�ǿ�ȵ�ͻȻ�仯 (���谵�ı��������ı���)��Ȼ����ǿ�ȱ仯֮�������, ���˽���ɫ�ĺ㶨�Ⱥ���߿��� (�ٶ�Ϊ��֪�ıʻ����ȷ�Χ)�����������ڴ�СΪW�Ĵ�ֱ�����н��з���, ����ҵ��㹻������, �������ʻ�Ϊ���ڡ��˷��������ư���һЩ������Ҫ���ҵ��ı��Ŀ̶ȵIJ��� (�紹ֱ���ڴ�СW)�������ˮƽ����Լ����ıʻ�δ����Ϊ��ĸ��ѡ�����ʵ,���ʺ;��ӡ����, ���㷨ֻ�ܼ�����ˮƽ���ı�����������������ܽ����ʹ���� ICDAR ����ָ�겻ͬ�Ķ�������ɵġ�����ʵ���˴�[7] ��ָ��, ��֤�������ǵ��㷨����[7]��
��һ�ַ���[ 21 ]Ҳʹ�ñʻ����������Եĸ����������ˮƽɨ��������ˮƽɨ��������ⴹֱ�ʻ�����������Ѱ��С�ı���ˮƽ���ϣ�����ʹ����̬ѧ��չ����ѡ�������ӵ������������ṩ��ICDAR���ݿ����ܽ�����㷨�������ʻ����ⷽ�����ǵķ����Dz�����г̷���ͼ8, 10, 12����
���, ����[25]ʹ����߿���һ���Ե�˼���������Ƶ�����е��ı����ӡ��÷����ľ���������Ҫ���˲����ij߶Ⱥͷ�����м���, �ټ��϶�ˮƽ�ı��Ĺ���˥����
���Ƕ��з�Ķ�����ͨ���������������漰�����������й�: ң�� (��·�������ȡ) ��ҽѧ���� (Ѫ�ָܷ�)���ڵ�·̽����, ���л�������Ƭ�еĵ�·���ȷ�Χ����֪������, ������Ȼͼ���г��ֵ��ı���ἱ��仯������, ��·ͨ�������������Խṹ�Ե�����, ���ı���������ʵ�ġ��������·��⼼���������������г��ļ���, ��˲���ֱ�������ı���⡣���ڼ����ĵ���, �ο�[10]������Ĺ�����[11], ʹ����ʵ·��Ե�Ƿ�����Ϊ���ֵ�˵����·��������, Ȼ��С����Щ��ѡ�����ĵ�һ��û����ͼʹ�ú㶨�ĵ�·����, �Է�����顣���ǵķ����ڱʻ���ÿ��������ʹ���ܼ���ͶƱ, �Ӷ��ҳ����ȶ��ıʻ�ʶ��, ������Ҫ�����ĵ��ѡ�߽��и��Ӷ������ķ��顣��һ�ַ���[12]ʹ�ôӸ߷ֱ���ͼ������ȡ�ĵͷֱ���ͼ��ͱ߽��Ե��ȡ����, �Բ��ҵ�·��ѡ�ߡ����ı����������, ���ƵIJ�����Ҫһ�������߶ȵ�ͼ�������;����, ʹ�ô˷�������̫���ܼ�С���ı���
���ڶ�Ѫ�ָܷ�ĵ���, �ο�[13]��������Ĺ���ʹ��ģ����� (��, ������ƿ), ���� (������, ��ֵ����ϸ��, С��) �ȷ�����ʹ������������Ϊ���û�ָ�������ӿ�ʼ���ٴ�ֻ�ĸ��ӹ��ܵ��о�����[14��15]�����е���Ʒ��û��һ����ͼ�����¶��ϵķ�ʽֱ��̽��������
3. �ı�����㷨
�ڱ�����, �����������ı�����㷨���������ȶ���ʻ��ĸ���, Ȼ�����߿���ת��(3.1), �Լ���������ڽ����ط���Ϊ��ĸ��ѡ (3.2)�����, ���������˽���ĸ����Ϊ����ĵ��ʺ���������Ļ���, ʹ���ܹ���һ�����й��� (3.3)�����㷨������ͼ��ͼ5��
3.1. ��߿���ת��
��߿���ת��(��� SWT) ��һ��ͼ��ֲ�����, ������ÿ�������а������ص�����ܱʻ��Ŀ��ȡ�SWT ������Ǵ�С��������ͼ���С��ͼ��, ����ÿ��Ԫ�ض�����������ع�������ߵĿ��ȡ����ǽ��ʻ�����Ϊͼ�����������, ���γ�һ�������㶨���ȵIJ���, ��ͼ 3 (a) ��ʾ�����Dz�������֪���ʻ���ʵ�ʿ���, ����Ҫ�ָ�����
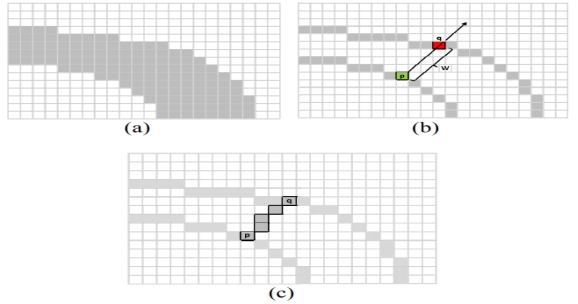
ͼ 3: SWT ��ʵ�֡�(a) �����з硣��ʾ���бʻ������رȱ������ذ���(b) p�DZʻ��߽��ϵ�һ�����ء��� p �Ľ��䷽��������,���²���q, ���ʻ���һ�����Ӧ���ء�(c) �����ߵ�ÿ���������䵱ǰ��ֵ����Сֵ�ͱʻ��ķ��ֿ��ȷ��䡣
SWT ��ÿ��Ԫ�صij�ʼֵ������Ϊ�ޡ�Ϊ�˻ָ��ʻ�, ����������Canny�ı�Ե�����[16]����ͼ���еı�Ե��֮��, ����ÿ����Ե���صĽ��䷽�� dp (ͼ 3b). ���λ�ڱʻ��߽���, �� dp ��������ߵķ�����´�ֱ��������ѭ������ r=p+n��dp, n> 0, ֱ���ҵ���һ����Ե���� q ��Ȼ��, ���ǿ��ǽ��䷽�� dq ������q ����� dq ������ dp (dq ����/6) ���, �� SWT ���ͼ���ÿ��Ԫ�ض�Ӧ�������ڶ���, ������Ϊ����, �������Ѿ����нϵ͵�ֵ (ͼ 4a)������, ����Ҳ���ƥ������� q , ���� dq ���� dp�Ķ���, ��ᶪ�������ߡ�ͼ3��ʾ�� SWT ����Ĺ��̡�
��ͼ4b ��ʾ, �����������ĵ�һ��ͨ����, �ڸ����ӵ���� (���) �е� SWT ֵ��������������߿��ȡ����, �����ٴδ���ÿһ���Ƕ���������, ������������ص��м� swt ֵ m , Ȼ�����ߵ�������������Ϊ m �ϵ� swt ֵ���� m .
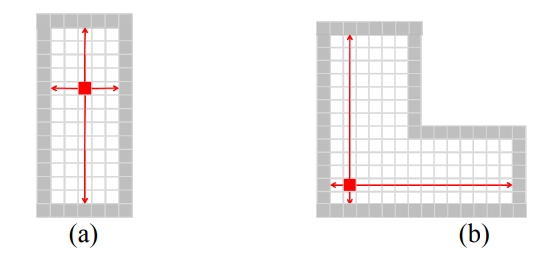
ͼ 4: �� SWT ֵ������ء�(a) �ڴ�ֱ��ˮƽ���ߴ������ij���֮��, ����С�ĺ�ɫ�������һ�����ӡ��洢�ʵ�����߿���ֵ��(b) ��ɫ���ص����Ӵ洢�������߳���֮�����Сֵ;�ⲻ����������߿���-����ʾ�˵ڶ������ݵı�Ҫ�� (��μ��ı�)��
�˴������� SWT ������ͼ��ı�Ե�������������Ե�, ������ѵ����ȷ���������߿����е����ԡ�
3.2. �����ź���ѡ��
SWT �������һ��ͼ��, ����ÿ�����ذ���������������ܱʻ��Ŀ��ȡ��㷨����һ���ǽ���Щ���ط���Ϊ��ĸ��ѡ���ڱ�����, ���ǽ�����Ϊʵ����һĿ�Ķ����õ�һ���൱�ձ�Ĺ���
��������������ص���߿�������, ����������һ��Ϊ��, �����ľ�����������㷨[17], �����ǽ���������Ӷ������������Ϊ�Ƚ����� SWT ֵ��ν�ʡ����Ƿ���һ���dz����صıȽ����㹻��, �����������ڵ�����, ������ǵ� SWT ���ʲ�����3.0�����ֲ�����֤��ƽ���仯���ȵıʻ�Ҳ�������һ��, �Ӷ����������µ��������Ť�� (ͼ 8)��Ϊ������ɫ������ͬʱ�����������ı�, ��֮��Ȼ, ����Ӧ�ø��㷨����, һ���� dp , һ����-dp.
����������Ҫʶ����ܰ����ı��������Ϊ��, ���Dz�����һ���൱���Ĺ���ÿ������IJ�����[8]��ѵ����ѧϰ������ִ�еĵ�һ�������Ǽ���ÿ�����ӵ��������߿��ȵķ���, ���ܾ��䷽������ֵ������ų�������Ҷ�����ĵ���, ��������Ȼ������, �������к���峡���ж���ʢ��, ���ұ���Ϊ�������֡���ͼ 1 (c) ��ʾ, �˲����������ֱ�Ҷ�Ӹ�һ�µ��ı�����ѧϰ����ֵ���ض����������ƽ����߿��ȵ�һ�롣
������Ȼ�����п��ܲ�������խ�ijɷ�, ���ܻᱻ����Ϊ��ij����ĸ�����ӹ���ͨ�������ǵ��ݺ������Ϊ����0.1 ��10֮���ֵ, �Ӷ�������Щ�������ۡ�ͬ��, �����������ӵķ�����ֱ����������ֵ�ʻ����ȵı�ֵС��10��
��һ���������������ӵ�������ܻ����ı�, �����֡������ͨ��ȷ������ı߽���������������������� (��ͨ��������б���ı���) ��������Щ���⡣
���, ��С̫С��̫���������ܻᱻ���ԡ������ǵ�ѵ����ѧϰ, ���ǽ��ɽ��ܵ�����߶�������10��300����֮�䡣ʹ�ø߶Ȳ�������ʹ�����ܹ������ӵĽű�, ����д��Ͱ���������, �Լ����ڱ�Ե���εĻ����Ͳ����ƶ�ʹ�����е�Сд��ĸ������ӵ�����
������������Ϊ����ĸ��ѡ��, ����һ�������ǽ�������Щ������������۳����ֺ��ı��еġ�
ͨ���Ż�����, ����ȫ��ע��ѵ����[8]��ѧϰ�˼��β��Ե�������ֵ��������˵, ��ѵ������, ���Ǽ�������ÿ���߽�� (��ע���ṩ) �б�ʾ��ĸ���������, ������ʹ�� "���" �㷨[20]��������Ӧ��ֵ��, Ȼ����ȡ���ӵ���������ǵ�����ÿ�����˹���IJ���, �Ա��99% �����������
3.3. ����ĸ���鵽�ı���
Ϊ�˽�һ������㷨�Ŀɿ���, ���Ǽ�����ǰ����һ����������ĸ�顣
������Щ����һ����Ҫ�Ĺ��˻���, ��Ϊ����ĸͨ�����������ͼ����, ��������ʹ�����ܹ�ȥ�����ɢ����������
�ı���һ����Ҫ��ʾ������������ʽ���֡����е��ı�Ӧ����������, �������Ƶ���߿��ȡ���ĸ���ȡ��߶Ⱥ���ĸ�͵���֮��Ŀո�����������֤���Ǽ��м�ֵ�ġ�����, ���������Աߵĵ������ᱻ����Ϊ����ĸ "O" �� "I" �����, ��Ϊ���ӱ����Ӹߵöࡣ������Ϊÿ����ĸ��ѡ���п�������ͬһ�ı��С�������ĸ�Ŀ���Ӧ�������Ƶıʻ����� (����֮��ıʻ����ȱ���С�� 2.0)����ĸ�ĸ߶ȱȲ��ó��� 2.0 (���ڴ�д��Сд��ĸ֮��IJ���)����ĸ֮��ľ��벻�ó������ȵ�������
����, ����Ե�ƽ����ɫ���бȽ�, ��Ϊͬһ�����е���ĸͨ��������ͬ����ɫ��д�����в�������ͨ���Ż���ѵ�����������˽��, ���3.2 ��������
���㷨����һ��������, ��ȷ���ĺ�ѡ�Ա��ۼ���һ����������, ÿ������һ����ĸ��ѡ����ɡ����������Ժϲ���һ��, ������ǹ���һ�˺������Ƶķ������ϲ��κ���ʱ, �ý��̽�����ÿ�����ɵ����㹻�� (����3����ĸ�����ǵ�ʵ����) ����Ϊ��һ���ı��С�
���, �ı��б��ֳɲ�ͬ�ĵ���, ʹ��һ������ʽ��������������ĸ֮���ˮƽ����ֱ��ͼ, �����ƽ������ڵ���ĸ�����뵥�ʼ���ĸ�����ľ�����ֵ������.��Ȼ����һ�㲻��Ҫ��һ��, ������������Ϊ�˱Ƚ����ǵĽ������Щ�� ICDAR 2003 ���ݿ�[8]�������ǵ����ݿ���ʾ�Ľ��[26]���Dz�ʹ���������, ��Ϊ�����Ѿ�����������ı��С�
4. ʵ��
Ϊ���ṩ���߱Ƚ�, ������[24]�еĹ����������ݼ������������ǵ��㷨�����ڶ��������ı�������ʹ����: ICDAR 2003[8]�� ICDAR 2005[9]����Ȼ�ڱ������Ѿ������˼�ƪ���ּ����Ʒ, ��û����������������ݿ���ȡ�ø��õijɼ�;����, ICDAR ���ݼ���Ȼ����Ȼ��������㷺ʹ�õ��ı�������
�����������Զ������ݼ�, ��������������Ȼ�����бȽϡ�ICDAR ���ݼ���ѵ�����Ͳ��Լ��е�251��ͼ���а���258��ͼ��ͼ����ȫ��ɫ��, ��С��307��93��1280��960���ز��ȡ����㷨��-f�������бȽ�, �Ȿ��������������ֵ�����:���ʺͲ�ȫ�ʡ�������ѭ[8]����������Щ������Ϊ������Ե�ʡ�

ͼ 6: ICDAR ���Լ��Ķ��ͼ���ϵ��ı����������ע��, ���������١�
ÿ���㷨�������һ�����, ����ָ�����ĵ��ʵı߽�˼���Ϊ������ֵ��(�μ�ͼ 6)�������ݼ����ṩ��һ���Ϊ��Ŀ�ꡱ�ĵ����������������֮���ƥ��mp ����Ϊ�ཻ����������������ε���С�߽����������ֶ���û�н����ľ���, ��ֵΪͬһ�����κ��㡣����ÿ�����ƾ���, ��Ŀ�꼯�����ҵ���ӽ���ƥ����, ��֮��Ȼ�����, ���ƥ�� ;���� ������һ��������ɶ���
m(r;R)=max{mp(r;r0)|r0��R}
(1)
Ȼ��, ȷ�ʺ��ٻ��ʵĶ���Ϊ 
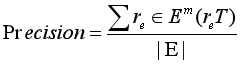 (2)
(2)
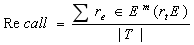 (3)
(3)
����T��E�ֱ��ǵ�����ֵ���ƾ��εļ��ϡ�
����f����ֵ���ڽ����Ⱥ��ٻ��������Ϊ������������ֵ����Щֵ�����Ȩ����һ����������, ���ǽ�������Ϊ 0.5, ��ʹ��ȷ�ʺ��ٻ��ʵ�Ȩ�����:
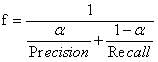 (4)
(4)
��1��ʾ���� ICDAR ���ݿ��ϲ��ԵIJ�ͬ�㷨�ľ��ȡ��ص���f֮��ıȽϡ�
Ϊ��ȷ����߿�����Ϣ (3.1 ��) �ͼ����˲� (3.2 ��) ����Ҫ��, ���ǻ��ڲ��Լ����������������������е��㷨: ���� #1 ��������߿���ֵС�ڡ�����Ϊ 5 (���Ĵ˳�����������Ӱ����)������ #2 �ѹرռ���ɸѡ���������������, ���Ⱥͻص��½� (������ #1��p = 0.66, r = 0.55 , ������ #2��p = 0.65, r = 0.5 )������ʾ�� SWT �ṩ����Ϣ����Ҫ�ԡ�
��ͼ7��, ������ʾ��δ���ı��ĵ����������������ǿ�ҵ�ͻ����ʾ���ı������ȡ��������Ĵ�С������ģ���������ߡ�
|
Algorithm
|
Precisi on
|
Recall
|
f
|
Time
(sec.)
|
|
Our system
|
0.73
|
0.60
|
0.66
|
0.94
|
|
Hinnerk Becker*
|
0.62
|
0.67
|
0.62
|
14.4
|
|
Alex Chen
|
0.60
|
0.60
|
0.58
|
0.35
|
|
Qiang Zhu
|
0.33
|
0.40
|
0.33
|
1.6
|
|
Jisoo Kim
|
0.22
|
0.28
|
0.22
|
2.2
|
|
Nobuo Ezaki
|
0.18
|
0.36
|
0.22
|
2.8
|
|
Ashida
|
0.55
|
0.46
|
0.50
|
8.7
|
|
HWDavid
|
0.44
|
0.46
|
0.45
|
0.3
|
|
Wolf
|
0.30
|
0.44
|
0.35
|
17.0
|
|
Todoran
|
0.19
|
0.18
|
0.18
|
0.3
|
|
Full
|
0.1
|
0.06
|
0.08
|
0.2
|
�� 1: �ı�����㷨�����ܱȽϡ��й� ICDAR 2003 �� ICDAR 2005 �ı���⾺������ϸ��Ϣ, �Լ������㷨, ��μ�[9]��[10]��
* δ�������㷨��
Ϊ�˱Ƚ����ǵĽ��[7], ����ʵʩ������������ıȽϴ�ʩ�����ǵ��㷨��������: �����ٻ���Ϊ 79.04%, �ʻ�����Ϊ 79.59% (��Ϊ���ǶԱʻ��Ķ���[7]��ͬ, ���Ǽ����˵�����ֵ�����������ͨ����������, ���Ǽ������ؾ���, ������������ڵ����������Լ����������������������90.39%��������[7]����ʾ�Ľ��
�����ṩ ICDAR ���ݿ�Ľ����, ���ǻ�Ϊ��Ȼͼ���е��ı���������һ���µĻ����ݿ�[26]�������ݿ�, ����Ѵ����ǵ���վ����, ����307��ɫͼ���С����, ��1024x1360 ��1024x768�����ڴ���ֲ�����ظ�ģʽ (�� windows)�������������ı�û��OCR , ���ݿ�� ICDAR ���ѵöࡣ���ǵ��㷨�����ݿ��ϵ���������: ����: 0.54, �ٻ�: 0.42, f-����ֵ: 0.47��ͬ��, �ڲ�����Щֵʱ, ������ѭ��[8] �������ķ�����
�������ǵ��㷨�ĸ���Ʒ֮һ����ĸ����, ��������������ı��ָ����롣Ϊ�������㷨���������ı��ָ�Ŀ�����, ���������һ���ֳɵ� OCR ��, ���а����ı�, ������б�ʾ�ı������Ķ�ֵ��ͼ�ָ�.�������������, OCR �Ľ����ͼ11��ʾ��
5. ������
���������, ����չʾ��������ûָ��ıʴ����ȵ��뷨, �ı���⡣���Ƕ����˱ʻ��ĸ���, ��������һ����Ч���㷨��������, ����һ���µ�ͼ��������һ���ָ�, ���ṩ��һ������, ��֤���ǿɿ��������ı���⡣���������ı������ǰ���ص㣬�������ܶȹ��ƣ�SWT�ļ�����ÿһ�����أ���Ǿֲ���Χ���ʻ�����ȡ��������������Ϣ����ʱ�ں�Զ�����أ���������Ŀ��ò������, ���ǵ��㷨�ﵽ�˵�һλ, �ٶȴ�Լ������15�����ù��ܾ�������, ��������ʹ��, ����Ҫʵ���ַ�ʶ����, ��һЩ��ǰ����Ʒʹ��[3]����ʹ���ǿ��Խ��÷���Ӧ�����������Ժ����塣
������м��ֿ��ܵ���չ��ͨ�����ǻָ��ʻ��ķ���, ���������ĸ���顣��Ҳ����������������ı��С����Ǵ�����δ��̽����Щ����
�����
[1] J. Liang, D. Doermann, H. Li, "Camera-based analysis of text and documents: a survey", International Journal on Document Analysis and Recognition", 2005, vol. 7, no 2-3, pp. 83-200
[2] K. Jung, K. Kim, A. K. Jain, ��Text information extraction in images and video: a survey��, Pattern Recognition, p. 977 �C 997, Vol 5. 2004.
[3] X. Chen, A. Yuille, "Detecting and Reading Text in Natural Scenes", Computer Vision and Pattern Recognition (CVPR), pp. 366-373, 2004
[4] R. Lienhart, A. Wernicke, ��Localizing and Segmenting Text in Images and Videos�� IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 12, NO. 4, APRIL 2002, pp. 256-268
[5] A. Jain, B. Yu, ��Automatic Text Location in Images and Video Frames��, Pattern Recognition 31(12): 2055-2076 (1998)
[6] H-K Kim, "Efficient automatic text location method and content-based indexing and structuring of video database". J Vis Commun Image Represent 7(4):336�C344 (1996)
[7] K. Subramanian, P. Natarajan, M. Decerbo, D. Castañ��n, "Character-Stroke Detection for Text-Localization and Extraction", International Conference on Document Analysis and
Recognition (ICDAR), 2005
[8] ��ICDAR 2003 robust reading competitions��, Proceedings of Seventh International Conference on Document Analysis and Recognition, 2003, pp. 682-68
[9] ��ICDAR 2005 text locating competition results��, Eighth International Conference on Document Analysis and Recognition, 2005. Proceedings. pp 80-84(1)
[10] L.i J. Quackenbush, "A Review of Techniques for Extracting Linear Features from Imagery", Photogrammetric Engineering & Remote Sensing, Vol. 70, No. 12, December
2004, pp. 1383�C1392
[11] P. Doucette, P. Agouris,, A. Stefanidis, "Automated Road Extraction from High Resolution Multispectral Imagery", Photogrammetric Engineering & Remote Sensing, Vol. 70, No. 12, December 2004, pp. 1405�C1416
[12] A. Baumgartner, C. Steger, H. Mayer, W. Eckstein, H. Ebner, "Automatic road extraction based on multi-scale, grouping, and context", Photogrammetric Engineering & Remote Sensing, 65(7): 777�C785 (1999)
[13] C. Kirbas, F. Quek, "A review of vessel extraction techniques and algorithms", ACM Computing Surveys (CSUR), Vol. 36(2), pp. 81-121 (2004)
[14] S. Park, J. Lee, J. Koo, O. Kwon, S. Hong, S, "Adaptive tracking algorithm based on direction field using ML estimation in angiogram", In IEEE Conference on Speech and Image Technologies for Computing and Telecommunications. Vol. 2. 671-675 (1999).
[15] Y. Sun, "Automated identification of vessel contours in coronary arteriogramsby an adaptive tracking algorithm", IEEE Trans. on Med. Img. 8, 78-88 (1989).
[16] J. Canny, ��A Computational Approach To Edge Detection��, IEEE Trans. Pattern Analysis and Machine Intelligence, 8:679714, 1986.
[17] B. K. P. Horn, ��Robot Vision��, McGraw-Hill Book Company, New York, 1986.
[18] J. Gllavata, R. Ewerth, B. Freisleben, ��Text Detection in Images Based on Unsupervised Classification of High-Frequency Wavelet Coefficients��, 17th International Conference on Pattern Recognition (ICPR'04) - Volume 1, pp. 425-428
[19] H. Li, D. Doermann, O. Kia, "Automatic Text Detection and Tracking in Digital Video", IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 9, NO. 1, JANUARY 2000
[20] N. Otsu, "A threshold selection method from gray-level histograms". IEEE Trans. Sys., Man., Cyber. 9: 62�C66 (1979)
[21] V. Dinh, S. Chun, S. Cha, H. Ryu, S. Sull "An Efficient Method for Text Detection in Video Based on Stroke Width Similarity", ACCV 2007
[22] Q. Ye, Q. Huang, W. Gao, D. Zhao, "Fast and robust text detection in images and video frames", Image and Vision Computing 23 (2005) 565�C576
[23] Y. Liu, S. Goto, T. Ikenaga, "A Contour-Based Robust Algorithm for Text Detection in Color Images", IEICE TRANS. INF. & SYST., VOL.E89�CD, NO.3 MARCH 2006
[24] http://algoval.essex.ac.uk/icdar/Datasets.html.
[25] C. Jung, Q. Liu, J. Kim, "A stroke filter and its application for text localization", PRL vol 30(2), 2009
[26] http://research.microsoft.com/enus/um/people/eyalofek/text_detection_database.zip
