一种判断古代文本年代的机器学习模型
摘 要 本文使用长短期记忆神经网络作为主体构建模型来分析古代文本序列,解决古代书代文本断代的问题。在本文提出的模型当中,一段文本中的每一个字被转换成一串高维向量,然后将所有向量送入模型分析它们之间的非线性关系,模型最终会输出一个该段文本的大致年代。实验结果表明利用LSTM神经网络构造的模型能够很好的完成断代任务,断代的正确率能到到90%以上。因此,本文提出的模型提供了一种高效且准确的古文断代方法,将其应用到古汉语研究领域可以一定程度上的节省古文研究工作者在文本分析过程中的时间消耗。
关键词 古代文本;断代;机器学习;长短期记忆神经网络
A Machine Learning Model for the Dating of
Ancient Chinese Texts
ABSTRACT This paper, with the intent of solving the issues on the dating of ancient Chinese texts, takes advantage of the LongShort Term Memory Network (LSTM) to analyze and process the character sequence in ancient Chinese. In this model, each character is transformed into a high-dimensional vector, and then vectors and the non-linear relationships among them are read and analyzed by LSTM, which finally achieve the dating tags. Experimental results show that the LSTM has a strong ability to date the ancient texts, and the precision reaches about 95% in our experiments. Thus, the proposed model offers an effective method on how to date the ancient Chinese texts. It also inspires us to actively improve the time-consuming analysis tasks in the Chinese NLP field.
KEY WORDS Ancient Chinese texts; Dating; Machine learning; LSTM
1 前言
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。这一领域的研究将涉及自然语言,即人类使用的语言,所以它与语言学的研究有着密切的联系,是将语言、文字进行信息化的基础。中文自然语言处理是自然语言处理的一个重要部分,中文相比于英文有词边界较难鉴定、句法更灵活等特殊性,近年来,国内针对中文的自然语言处理的相关研究也逐渐受到重视。伴随着深度学习热潮兴起,中文分词、词性标注、命名实体识别和句子结构化表示等中文自然语言处理的研究也在深度学习技术的推动下获得了长足的发展。随着中文信息化的程度越来越深,我们越来越发现蕴含着中华民族千百年智慧的古汉语书籍更加需要我们利用现代化的技术进行妥善的保存、处理。对于实体古籍来说我们需要将其数字化、信息化,分门别类存档入库,这有利于我们传承传统文化和保护先人的思想精华。对于已经入库的电子书来说,我们需要利用现代中文自然语言处理技术对其进行更深层次的结构化处理和数据挖掘。这对于现有古汉语书籍的保存、知识提取和历史研究将重要意义,将促进我国的数字人文建设。然而现实是当前古汉语数字化进展大多停留在入库阶段,其后期的分词、词性标注、命名实体识别、文本结构化处理、文本分类等研究较少,目前所实现的一些方法其精度也不是很高。限制目前各类方法精确度的一部分原因是,中文有据可查的文字源自公元前14世纪的殷商后期,这时形成了初步的甲骨文,距今已延续了三千多年,而这三千多年的演变过程中,中文的字义、词义和句法等也在不断的动态变化中。以古文翻译来说,“汤”,原指一切热水,现在仅指食物煮后所得的汁水或烹调后汁特别多的副食,又如“治”的本义是平治水患,所以字从“水”旁,后来扩大为泛指一切治理。由此可见不同时代的中文,会有不同时代的特色,并不是一成不变的。面对我们中文历史源远流长的情况,试图构造出一种普适于各种时代的模型是很难实现的。判定了古籍所在的大致时间,才可以更加有针对性的对古籍进行后续研究,将提高研究的精度和效率。因此,本文试图从古籍时间判定的角度在中国古文自然语言处理领域进行一定的探索,本文的研究成果将对古文分词、词性标注、命名实体识别、文本结构化处理、文本分类等其他方面的研究有所帮助。
2. 相关工作
从技术角度来说,古文的时间判定就是指模型接收一段文本,模型自动计算并输出一个年代标签。因此,从输入输出的关系来看,古文时间判定任务即为一个文本分类任务。目前的文本分类模型,大致可分为两类,一类是基于规则或基于概率统计的传统机器学习方法,另一类是基于CNN、RNN、self-Attention的深度学习方法。其中,基于规则或概率的方法相对简单,易于实现,在特定领域能取得较好的效果。其优点是时间复杂度低、运算速度快。但是需要考虑很多规则或特定条件来表述类别,因此需要通过领域专家定义和人工提取特征。
结合深度学习方法来解决特定领域问题是近年来的一个趋势,***和***分别将cnn和RNN应用到文本分类中,18年提出基于self-attention机制的bert模型,在不同的NLP任务中均有很好的表现。但是bert模型主要面向现代语言,其成功主要依赖于当下互联网时代的海量信息化的文本,例如wiki百科、各类新闻媒体以及网络评论留言等,通过数以T计的训练集才得以训练出bert模型中200M的模型参数,然而这一切在语料资源相对缺乏的古汉语领域并不适用。因此,本文使用LSTM深度学习网络模型解决自动化古籍时间断定即古汉语文本分类任务,该模型主要有两个优点,一是不借助人工提取规则特征,二所需数据量比基于self-attention机制的模型相对较少。
3 古代文本断代模型
本文要解决古代书籍时间判定的问题,首先是获取待判定的一部书籍或者书籍中的一段文本,其字符序列表示为
S = {x1,x2,x3,…,xn} (1)
将此文本送入模型M,模型进行计算并输出一个年代标签T。
T = M(g({x1,x2,x3,…,xn})) (2)
这个过程中有以下几点关键技术需要注意,文本序列的向量化表示、模型总体结构和以及长短期记忆神经网络记忆单元结构。
古代文本断代模型的结构框图如下图所示:
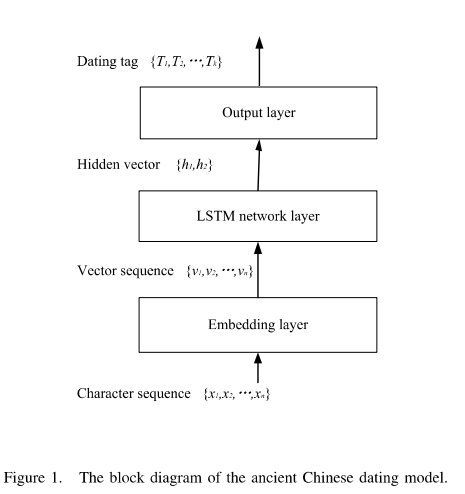
3.1模型结构
古模型接受一段古代文本作为输入送入模型,文本首先被送入嵌入层使模型获得该段文本的向量化表示。然后字符的嵌入向量逐字送入两层反向的LSTM神经网络层中分别计算正向和反向的隐藏向量。最终将两个隐藏向量串联送入输出层输出最终的预测结果。模型的细节如图二所示:
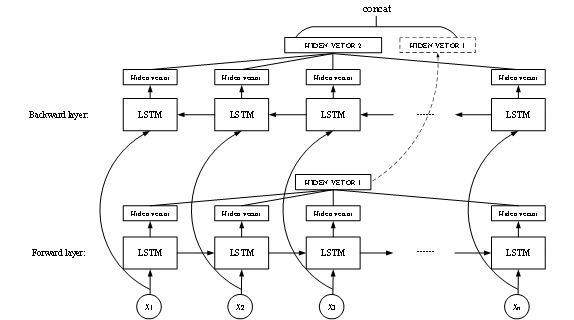
图9 X射线衍射图
模型分为三层,嵌入层、LSTM神经网络层和输出层。嵌入层是word2vec中的CBOW模型,及通过文本上下文预测中间字的方式实现中间字的向量表示。然后是神经网络层,该层使用两层反向的LSTM作为主体,第一层接受一层接受文本的正向输入,输出一个隐藏层向量,另一层接受文本的逆向输入,输出一个隐藏层向量,然后将两个向量串联,由于LSTM具有记忆上文信息的能力,因此两个隐藏向量即可表示所有上下文信息。
3.2嵌入层
在式1中,文本字符序列S={x1,x2,x3,…,xn}仍是人类所能阅读的文字形式,式2中g映射的作用是将人类所能理解的文字序列形式的S转化成计算机所能理解的向量化表示V:
{v1,v2,v3,…,vn}= g({x1,x2,x3,…,xn})
这个将文字映射为向量化表示的过程又叫做字嵌入。
目前字嵌入方式有两种,一种是对所有字符进行one-hot编码,但one-hot编码有编码过长,不同字之间向量相互垂直,没有语义联系,不能表示位置信息等缺点,因此我们不使用one-hot编码;另一种是低维实数向量表示(Dristributed representation),它的思路是通过训练,将每个词都映射到一个较短的词向量上来,可以解决One-hot 编码过长的问题。Google在***提出的word2vec模型是一种利用神经网络进行字嵌入训练的一个语言模型。他假设字向量是服从分布式假设的,如果两个词的上下文时相似的,那么他们语义也是相似的。word2vec模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量,如图所示。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量(word embedding),这个矩阵也叫做查询表(look-up table)。
Word2vec模型是非监督的,资料获取不需要很大的成本,我们可以通过word2vec模型在大量的未标注的语料上学习,就可以学习到比较好的向量表示,可以学习到词语之间的一些关系。比如男性和女性的关系距离,时态的关系,学到这种关系之后我们就可以把它作为特征用于后续的任务,从而提高模型的泛化能力。
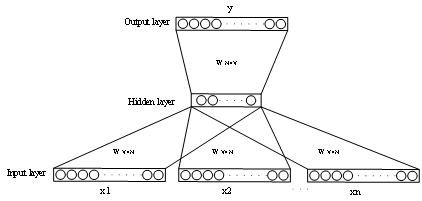
图4 X射线衍射图
同文字的向量化道理相同,时间标签同样需要考虑人类标签和机器理解的问题,本文使用的时间标签为年代标签,如汉代、唐代中期,首先将此各种时间标签Tm∈TM按时间顺序排序{T0,T1,T2,…,Tm},由于年代数相对较少,因此可以将朝代标签进一步表示为one-hot编码,方便模型通过Softmax评估出某一朝代。
3.3长短期记忆神经网络层
LSTM神经网络通过输入门、输出门和遗忘门这些门结构来控制长期记忆的以往与保存,LSTM记忆单元在时间维度上展开的结构图如图所示。其中各种门结构的公式如下:
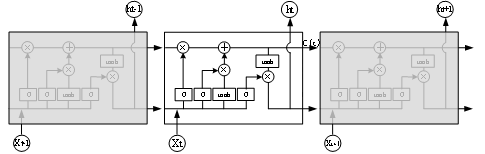
图7 X射线衍射图
Lstm中门结构公式为
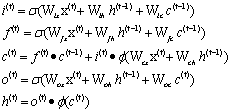
公式中,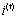 为输入门,
为输入门,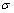 是sigmoid函数,其值域为[0,1],起到将向量中的每个元素限制在0到1之间。因此,门函数和一个信息向量的哈达玛乘积就可以表示保存或者遗忘某些信息。
是sigmoid函数,其值域为[0,1],起到将向量中的每个元素限制在0到1之间。因此,门函数和一个信息向量的哈达玛乘积就可以表示保存或者遗忘某些信息。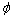 是tanh函数,用来将向量的每个元素映射到[-1,1]之间,
是tanh函数,用来将向量的每个元素映射到[-1,1]之间,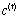 是长期信息,
是长期信息,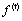 是遗忘门,二者相乘可以用来控制长期信息中的某些信息是否继续保存到下一时刻,结合当前时刻的输入可以得到新的
是遗忘门,二者相乘可以用来控制长期信息中的某些信息是否继续保存到下一时刻,结合当前时刻的输入可以得到新的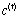 ,此外还有
,此外还有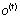 输出门,用来控制输出信息,从而影响到当前时刻的输出
输出门,用来控制输出信息,从而影响到当前时刻的输出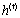 以及下一时刻的输入。正是这些门结构使得LSTM可以保留前文信息,从而能做出更好预测。
以及下一时刻的输入。正是这些门结构使得LSTM可以保留前文信息,从而能做出更好预测。
3.4输出层
输出层是一个全连接网络,他接受一个上层传入的1×2n维度的向量,其中n为LSTM神经网络输出的隐藏层向量维度。输出层包括一个2n×k维度的W权重矩阵以及一个1×k维度的偏置矩阵,其中k为所有分类的类别数,输出层的输出为y=Wx+b,是一个1×k维的向量,最后通过softmax函数对其进行输出归一化,归一化后的某一维度的数值即可视作该维度所表示年代的预测概率。softmax公式如下所示。
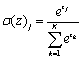
4 实验
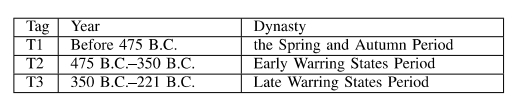
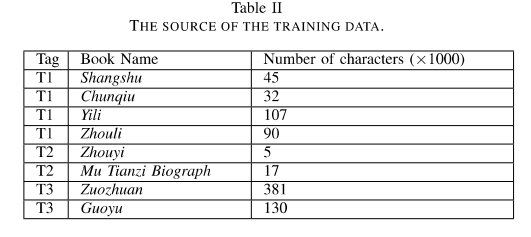
实验所用的数据集为从网络的开放数据库下载的春秋战国时期的古籍。根据古籍所处具体时期的不同,将其分为了春秋、战国早期及战国后期三个时间段,如下表所示,下文我们使用T1、T2以及T3表示这三个时期。
在上述的每个时期中,我们选择部分古籍作为训练集,各个时期书籍如下表所示,总计80万字。
模型有两个评估指标:一个是单句分类正确率Ps;另一个是书籍分类正确率Pb:
Ps=N时间判定正确的句子条数/总句子条数
Pb=时间判定正确的书籍数/总书籍数
一本书籍时间判定的决策取决于书籍内部所有句子决策的投票结果,统计所有句子判定结果后,最多的时间分类即判定为该书的时间段。在实现方面,模型通过Python的TensorFlow-GPU框架实现,所用的硬件配置为8G-cpu 1080Ti显卡。
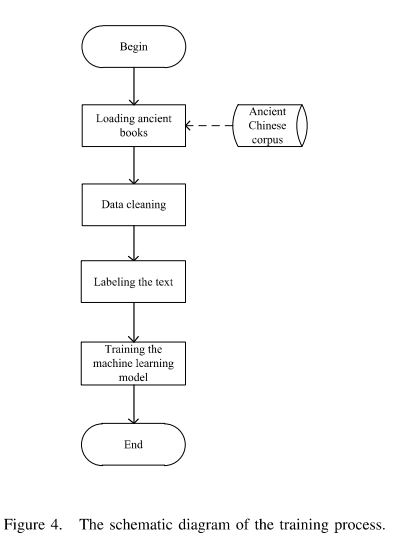
训练流程图如下图所示:
4.1参数选择
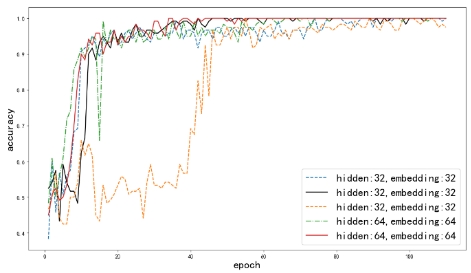
我们进行了一些实验来比较不同超参数情况下模型的训练过程。我们使用不同维度的隐藏层(Hidden Layer Dimension, HLD)和单词嵌入向量(Embedding Layer Dimension, ELD)。下图为训练过程的分类精度曲线。可见,当HLD为64,ELD为64时,收敛速度最快。在其他参数下虽然收敛速度较慢但也能达到较高的精度。同时,我们也比较了不同参数时模型在测试集上的表现,实验结果如表III所示。表中可见,虽然HLD为64,ELD为64的参数在训练集中表现较好,但是在测试集中其表现不佳,而HLD为32,ELD为32时在训练集和测试集中均表现优秀,因此,我们后面的实验将使用HDL为32和ELD为32的参数进行。
图**
4.2 实验
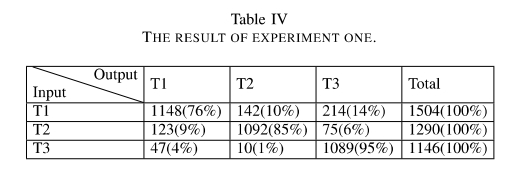
在第一个实验中,各个时期的所有书中都选出部分章节作为训练集,保留每本书的一部分章节不参与训练作为最后的测试集。最后我们将测试集中的文本送入模型,来预测他们的年代。下表为实验结果。表中的每一行表示输入为某时代的古籍文本时,模型的预测为不同时代的结果的条数。实验表明,在训练集与测试集出自于同一本书时,判断一个句子为正确句型的概率很大。这说明了某一时代内同一本书中的句法语法结构基本一致,模型学习了部分章节的结构信息后,可以较好的适用于同本书的其他章节中。
我们也做了另外一个实验,在该实验中我们在每个时期中挑选其中几本书作为测试集不参与训练,用该时期剩下的书籍文本训练模型,去观察模型对训练集之外的书籍的断代效果。我们将一本书分成多个句子,模型预测书籍的所有句子占比最多的时代判断为该书的时代。
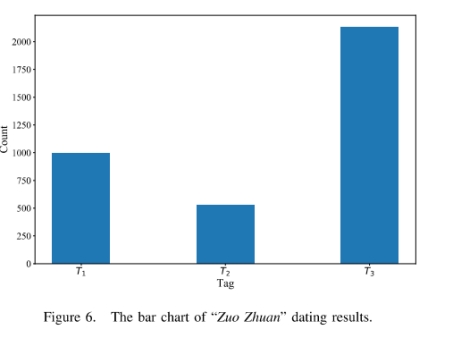
我们以《左传》为例进行了实验。在训练集没有输入《左传》任何文本的情况下,我们输入《左传》文本,让模型预测其年代。模型对《左传》的预测结果如下。在所有《左传》的句子中,模型将其中994句预测为春秋之前,将529句预测为春秋前期,2132句预测为春秋末期。从整体上看,《左传》是春秋末期的书籍。这与中国古代社会目前的共识是一致的,也印证了我们模式的正确性。该实验证明某一时期内的书籍之间句法语法上有潜在的联系,也有一定的统一性,因此模型可通过学习同一时期内一定量的书籍来判断其他书籍的信息。
实验结果表明,如果选取古籍的部分文本作为训练集,其余文本作为测试集,该模型的实验正确率可以达到90%。但是,若测试集的文本所属的书籍未参与模型的训练,古籍句子的正确率会降低,但综合某本古籍的所有句子来看,仍然可以通过投票原则正确判断古籍的年代。以上两个实验可以看出,同一部古籍的词汇和语法规则相对统一,同一历史时期不同古籍之间的词汇语法规则也有一定的联系性。
4 结论
本文使用了Bi-LSTM网络模型实现了古籍断代的任务。LSTM有考虑上下文的能力,本文证明了LSTM在文献量较少的古汉语领域也能训练出正确率不错的模型。本文的实验展示了不同情况下模型的断代正确率可以达到95%,因此,本文提出了一个针对古籍断代的有效模型,同时我们在模型训练复杂度上也在做更深入的探索。
我们清楚的知道,我们的模型仍有很多缺点和不足,本文提出的模型只是将NLP技术应用到古汉语的一小步探索,在古老且高深的古汉语领域中,仍有很多未解决的问题和更复杂的任务等着我们去探索和发现。我们后续会继续探索更加针对古汉语语言特点的特殊网络模型。
参 考 文 献
期刊:[序号]作者.题名.刊名,年,卷(期):起始页码
[1] Du Z J, Yang K Z, Gu Y Y, et al. Hydrothermal preparation and microstructure analysis of silver tin oxide contact materials. J Univ Sci Technol Beijing, 2007, 29(10): 1023
(杜作娟, 杨开足, 古映莹, 等. 银氧化锡触点材料的水热制备及组织分析. 北京科技大学学报, 2007, 29(10): 1023)
[2] Araki H, Saji S, Okabe T, et al. Solidation of mechanically alloyed Al-10.7%Ti powder at low temperature and high pressure of 2 GPa. Mater Trans JIM, 1995, 36 (3): 465
专著:[序号]著者.题名.出版地:出版者,出版年
[3] Huang P Y. Theory of Power Metallurgy. 2nd Ed. Beijing: Metallurgical Industry Press, 2004
(黄培云.粉末冶金原理.2版.北京: 冶金工业出版社, 2004)
会议论文:[序号]作者.题名//会议文集名称.会议地点,年代:起始页码
[4] Shen C, Shi X L, Tang S G, et al. The application of dynamic control steelmaking with gas analysis in Masteel // Proceedings of China Iron & Steel Annual Meeting. Beijing, 2005: 165
(沈昶,施雄梁,汤曙光,等. 烟气分析动态控制炼钢在马钢的应用//中国钢铁年会论文集. 北京,2005:165)
学位论文:[序号]作者.题名.城市:大学,年
[5] Zheng Y C. Study on High-Strength Structural Material with Iron Tailings of Miyun [Dissertation]. Beijing: University of Science and Technology Beijing, 2010
(郑永超.密云铁矿尾矿制备高强结构材料研究[学位论文]. 北京:北京科技大学,2010)
专利:[序号]专利所有者.专利题名:专利国别,专利号.公开日期
[6] Li M W, Bian X X, Chen G, et al. Strip Flatness Measurement Device of Looper Type: China Patent, 201034548. 2008-3-12
(李谋渭,边新孝,陈工,等.活套辊式平坦度检测装置:中国专利, 201034548. 2008-3-12)
标准:[序号]责任者.标准代号 标准名称.出版地:出版者,出版年
[7] Ministry of Housing and Urban-Rural Development, People’s Republic of China. GB50011―2010 Code for Seismic Design of Building. Beijing: China Architecture & Building Press, 2010
(中华人民共和国住房和城乡建设部. GB50011―2010建筑抗震设计规范.北京:中国建筑工业出版社,2010)
电子文献:[序号]责任者.题名[J/OL].出版者 (更新或修改日期)[引用日期].获取和访问路径
[8] Fan D P. Hargrove grindability index of the coal blended [J/OL]. Sciencepaper Online (2007-12-27) [2010-09-10]. http://www.paper.edu.cn/index.php/default/releasepaper/content/200712-756
(范杜平. 混煤哈氏可磨性指数[J/OL]. 中国科技论文在线 (2007-12-27) [2010-09-10]. http://www.paper.edu.cn/index.php/default/releasepaper/content/200712-756)
注: (1) 所有非英文文献均须同时列出相应的英文.
(2) 各参考文献均需列出3位作者之后,再加“,等”, 页号只要起始页.
(3) 会议论文集必须标明会议地点,专著必须标明出版地点和出版社.
