目录
一、任务要求
1.1目的
1.2内容
1.3组员任务分配
二、实现步骤
2.1 Hadoop集群搭建和服务器配置
2.1.1搭建虚拟机
2.1.2配置主节点
2.1.3克隆虚拟机
2.1.4配置SSH免密登陆
2.1.5 hadoop环境变量及文件配置
2.1.6 启动所有进程
2.1.7 搭建失败修复方法
2.1.8 验证搭建成功
2.2数据上传步骤和操作命令
2.3系统环境部署
MongoDB安装
zookeeper安装
Kafka安装
Flume安装
Redis安装
2.4 系统实现
各模块以及算法实现
统计推荐模块
系统离线推荐模块
实时推荐模块
2.5 系统部署启动
5.3.1 MongoDB服务启动
5.3.2 zookeeper服务启动
5.3.3 Kafka服务启动
5.3.4 Flume服务监控
5.3.5 Redis服务启动
5.3.6 后端推荐系统启动
5.3.7 业务系统启动
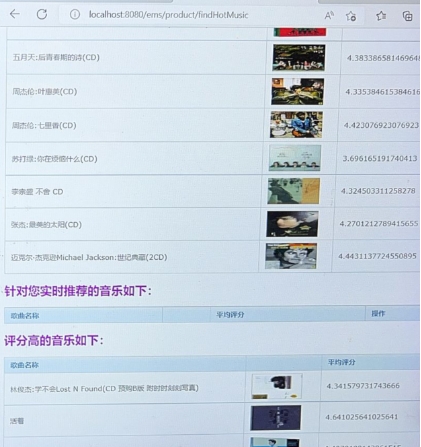
三、结果展示
一、任务要求
1.1目的
实现音乐实时推荐系统
1.2内容
hadoop搭建文档和服务器配置
数据上传步骤和操作命令
数据清洗过滤转换
阿里云数据操作分析的sql文档
数据可视化连接
二、实现步骤
2.1 Hadoop平台搭建(单机模式)和服务器配置
2.1.1搭建虚拟机
安装VMware ,务必以管理员的身份操作(CentOS6.5)的配置。在虚拟机上安装linux虚拟机
2.1.2配置主节点
设置IP,安装JDK配置环境变量,虚拟机IP和主机VMware Network Adapter VMnet1网络地址在同一网段内。
修改hosts和主机名,并关闭防火墙。
关闭防火墙,使用命令service iptables stop
关闭防火墙的自动启动,使用命令chkconfig iptables off
2.1.5 hadoop环境变量及文件配置
安装hadoop2.x并进行环境变量配置。修改hadoop-env.sh,core-site.xml,hdfs-site.xml,yrn-site.xml,mapred-site.xml(需要拷贝一份并重命名)文件配置。
修改配置文件
首先,需要进入到/usr/local/soft/hadoop-2.6.0/etc/hadoop 目录下,命令cd /usr/local/soft/hadoop-2.6.0/etc/Hadoop.
1.修改hadoop-env.sh文件,在文件中加入一句export JAVA_HOME=/usr/local/soft/jdk1.8.0_171

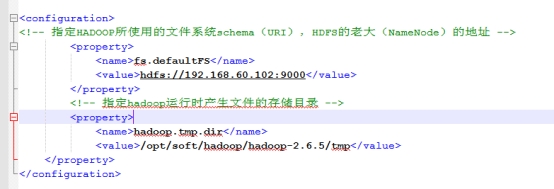
3.修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://shixun01:8020</value>
</property>
<!--指定临时文件存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop/hadoop-2.6.5/tmp</value>
</property>
</configuration>
4.修改 hdfs-site.xml 将dfs.replication设置为1

5.修改文件yarn-site.xml
<configuration>
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>shixun01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

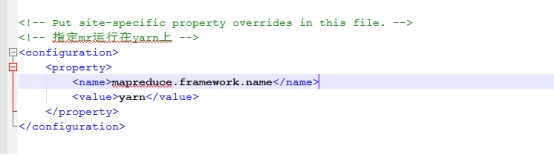
6.修改 mapred-site.xml(将mapred-site.xml.template 复制一份为 mapred-site.xml)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.1.6 启动所有进程
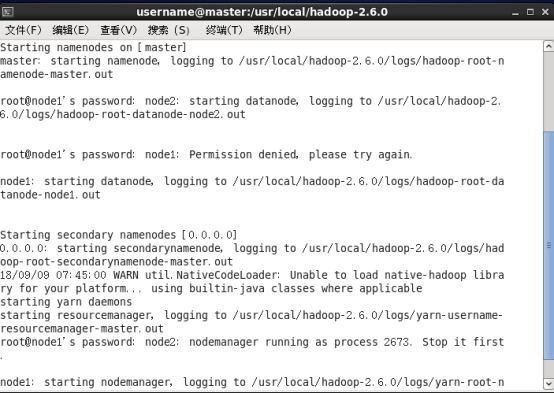
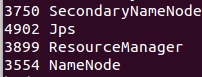
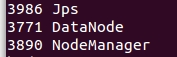
在主节点执行start-all.sh命令,利用jps查看结果,正确结果如下:
2.1.7 搭建失败修复方法
如果启动失败,stop-all.sh命令关闭所有进程,删除hadoop目录下tmp文件并执行命令hdfs namenode -format,重新启动。
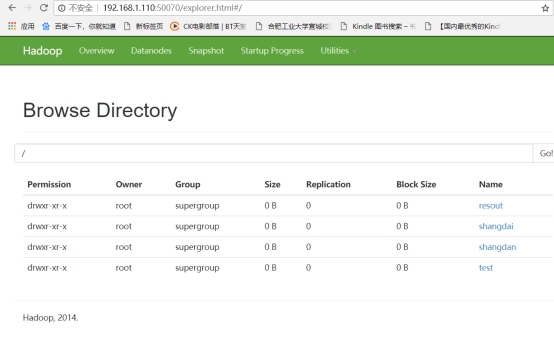
2.1.8 验证搭建成功
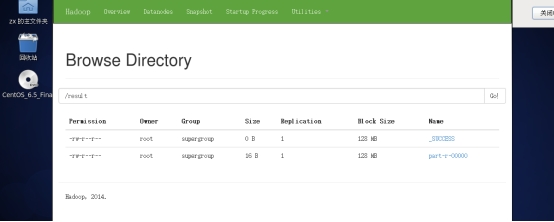
2.2数据上传步骤和操作命令
2.2.1利用xshell软件上传数据到/root目录下。
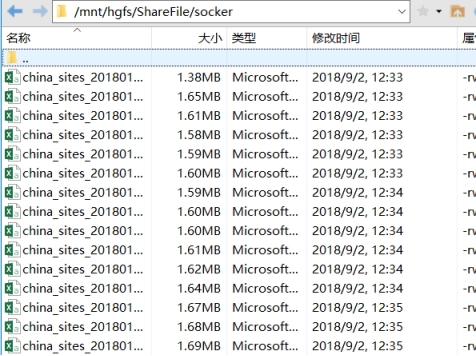
2.2.2在命令行中用 ./bin/hadoop fs -mkdir -p /test/input 命令在hdfs的test目录下,新建input目录,以便信息的上传。

2.2.3在命令行中用hadoop fs -put /test/input 命令把数据上传到hdfs上并重命名为input。

2.3系统环境部署
2.3.1MongoDB安装
#在线下载linux版本的mongodb [root@master packages]# wget https://fastdl.mongodb.org/linux/mongodb-linuxx86_64-rhel62-4.0.9.tgz
完成MongoDB的安装后,启动MongoDB服务器:
#启动MongoDB服务器 [root@master mongodb]# bin/mongod -config /usr/local/soft/mongodb/data/mongodb.conf
2.3.2Redis安装
#在线下载linux版本的redis [root@master packages]# wget http://download.redis.io/releases/redis4.0.2.tar.gz

2.3.3Zookeeper安装
#上传压缩包并解压到指定目录 [root@master packages]# tar -zxvf zookeeper-3.4.6.tar.gz -C /usr/local/soft/

2.3.4Kafka安装
#上传压缩包并解压指定目录 [root@master packages]# tar -zxvf kafka_2.11-1.0.0.tgz -C /usr/local/soft/

2.3.5 Flume安装
#上传压缩包并解压指定目录 [root@master packages]# tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /usr/local/soft/
2.4系统实现
2.4.1各模块以及算法实现
打开IDEA,创建一个maven项目,命名为MusicRecommendSystem。为了方便后期的联调,我们会把业务系统的代码也添加进来,所以我们可以以MusicRecommendSystem作为父项目,并在其下建一个名为recommender的子项目,然后再在下面搭建多个子项目用于提供不同的推荐服务。2.4.2统计推荐模块
在recommender下新建子项目StatisticsRecommender,pom.xml文件中只需引入spark、scala 和mongodb的相关依赖:
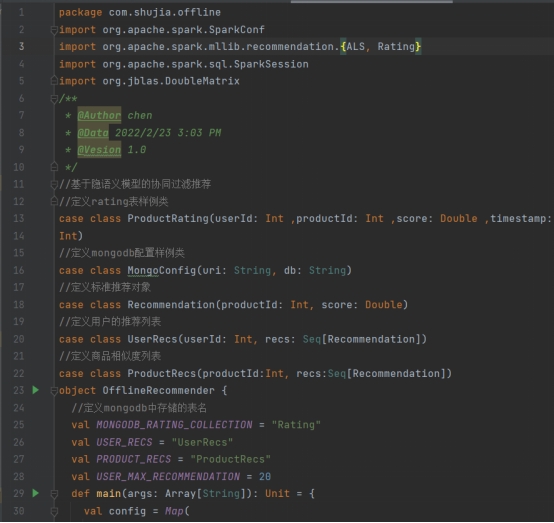
2.4.3离线统计模块
在resources文件夹下引入log4j.properties,然后在src/main/scala下新建scala 单例对象 com.shujia.statistics.StatisticsRecommender。 同样,我们应该先建好样例类,在main()方法中定义配置、创建SparkSession并加载数据,最后关闭 spark。代码如下:
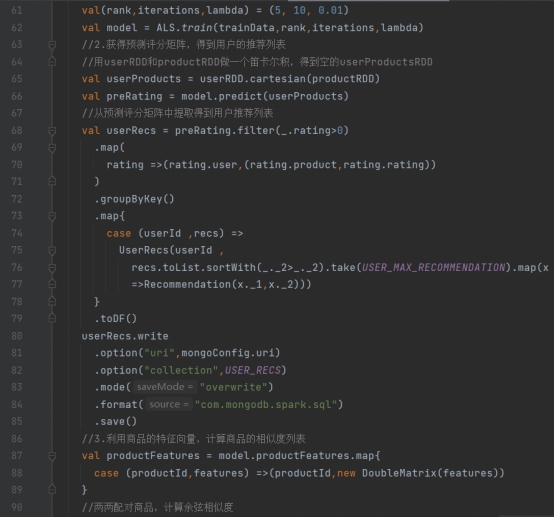
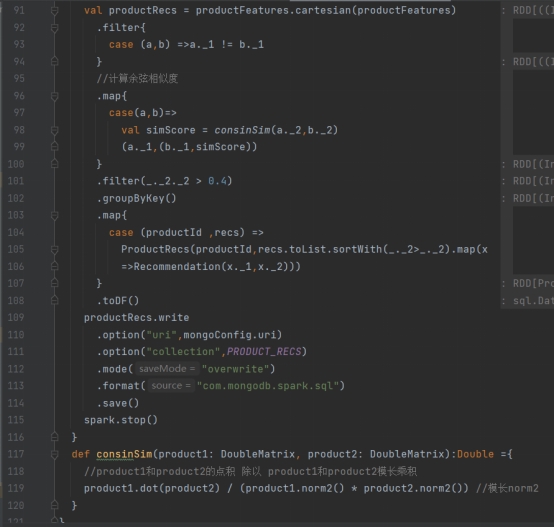
2.4.4实时推荐模块
实时计算与离线计算应用于推荐系统上最大的不同在于实时计算推荐结果应该反映最近一段时间用 户近期的偏好,而离线计算推荐结果则是根据用户从第一次评分起的所有评分记录来计算用户总体的偏 好。
用户对物品的偏好随着时间的推移总是会改变的。比如一个用户u 在某时刻对商品p 给予了极高的评分,那么在近期一段时候,u 极有可能很喜欢与商品p 类似的其他商品;而如果用户u 在某时刻对商品q 给予了极低的评分,那么在近期一段时候,u 极有可能不喜欢与商品q 类似的其他商品。所以对于实时推荐,当用户对一个商品进行了评价后,用户会希望推荐结果基于最近这几次评分进行一定的更 新,使得推荐结果匹配用户近期的偏好,满足用户近期的口味。
如果实时推荐继续采用离线推荐中的ALS 算法,由于算法运行时间巨大,不具有实时得到新的推荐结果的能力;并且由于算法本身的使用的是评分表,用户本次评分后只更新了总评分表中的一项,使得 算法运行后的推荐结果与用户本次评分之前的推荐结果基本没有多少差别,从而给用户一种推荐结果一 直没变化的感觉,很影响用户体验。
另外,在实时推荐中由于时间性能上要满足实时或者准实时的要求,所以算法的计算量不能太大, 避免复杂、过多的计算造成用户体验的下降。鉴于此,推荐精度往往不会很高。实时推荐系统更关心推 荐结果的动态变化能力,只要更新推荐结果的理由合理即可,至于推荐的精度要求则可以适当放宽。
 、
、 、
、
2.5系统部署启动
2.5.1MongoDB服务启动
#启动MongoDB服务器 [root@master mongodb]# bin/mongod -config /usr/local/soft/mongodb/data/mongodb.conf

2.5.2 Zookeeper服务启动
#启动zookeeper [root@master zookeeper-3.4.6]# bin/zkServer.sh start
#查看zookeeper的状态 [root@master zookeeper-3.4.6]# bin/zkServer.sh status

2.5.3 Kafka服务启动
启动kafka服务 启动之前需要启动Zookeeper服务 [root@master kafka_2.11-1.0.0]# bin/kafka-server-start.sh -daemon ./config/server.properties

2.5.4 Flume服务启动
等待项目部署时启动
2..5.5 Redis服务启动
#启动redis服务 [root@master bin]# ./redis-server redis.conf
#连接Redis服务器 [root@master bin]# redis-cli
#停止redis服务 [root@master bin]# redis-cli shutdown
2.5.6后端推荐系统启动
启动实时系统的基本组件 启动实时推荐系统OnlineRecommender以及mongodb、redis
2.5.6业务系统启动
三、结果展示