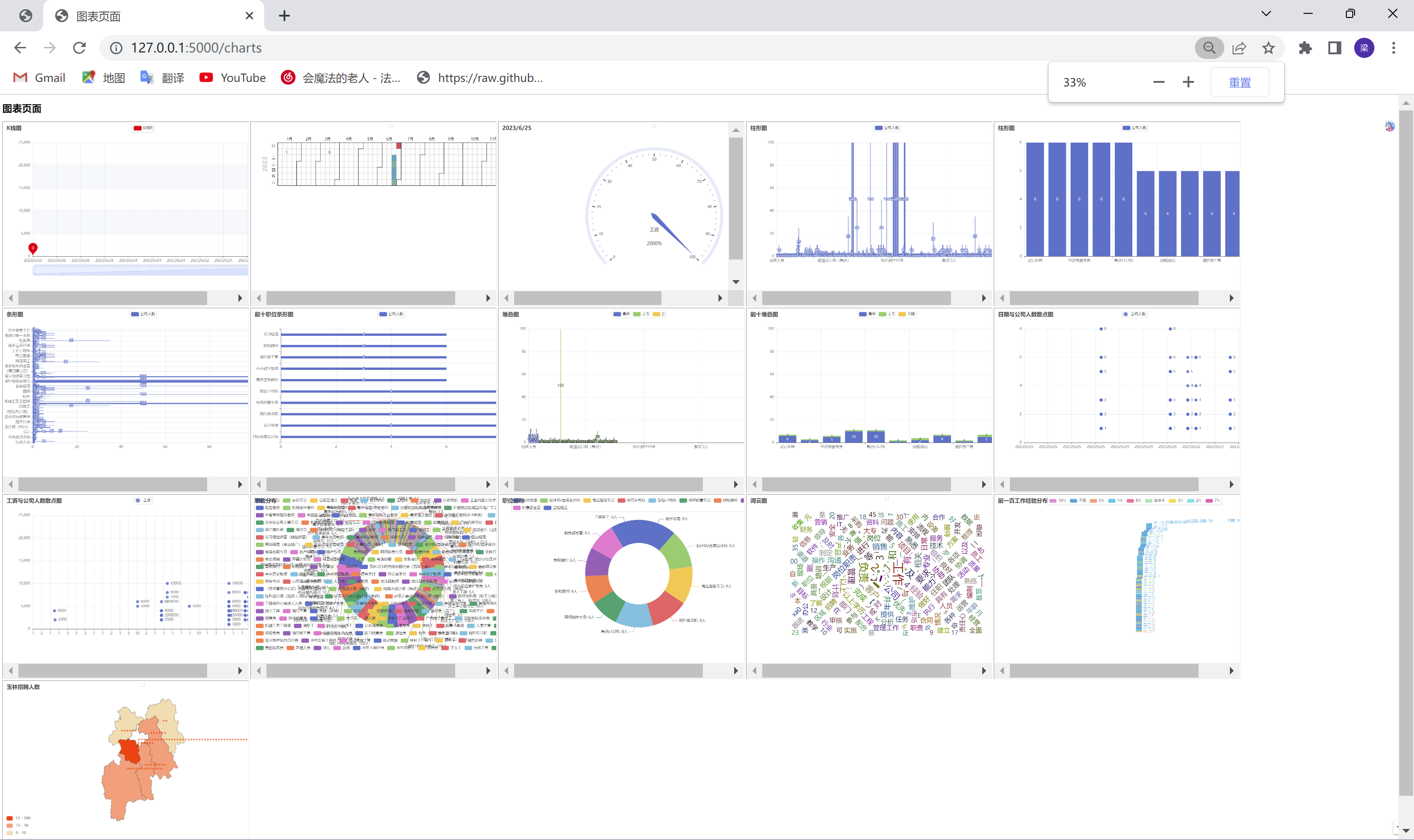
数据分析及可视化:
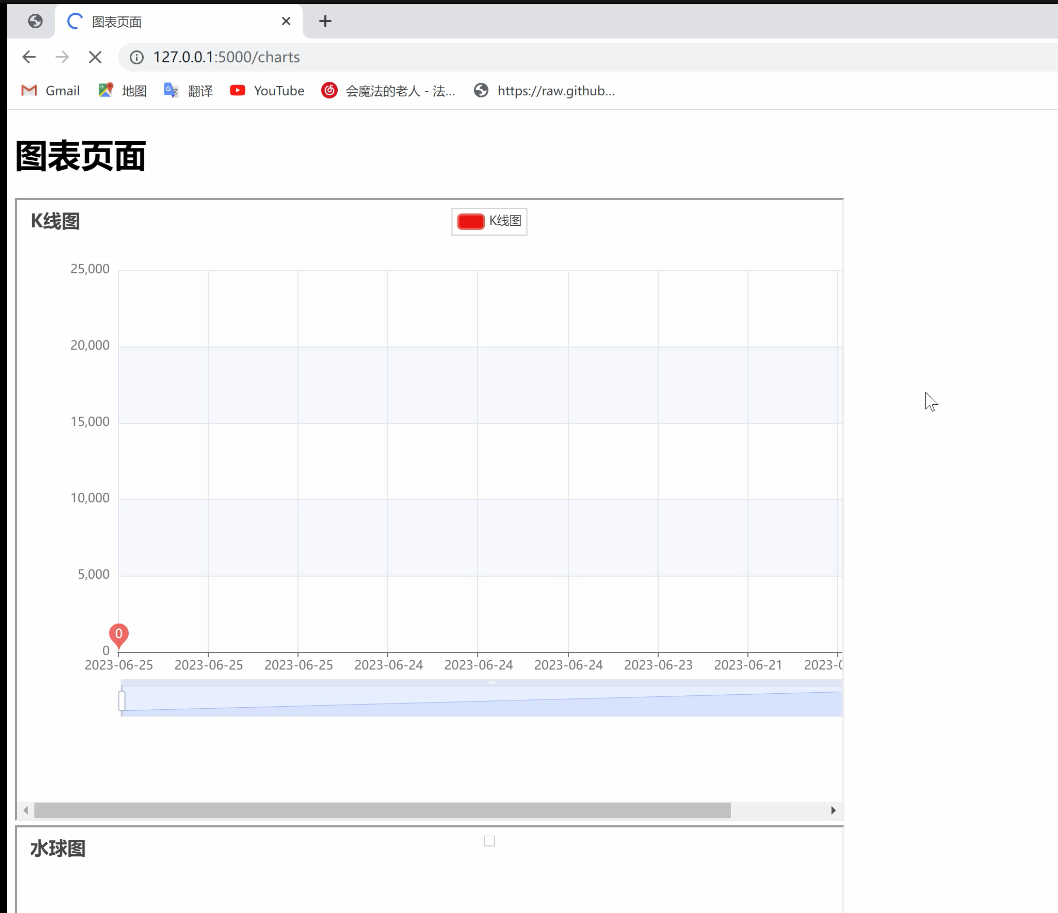
1. `kline_chart()`: 绘制K线图,展示日期与薪资之间的关系。
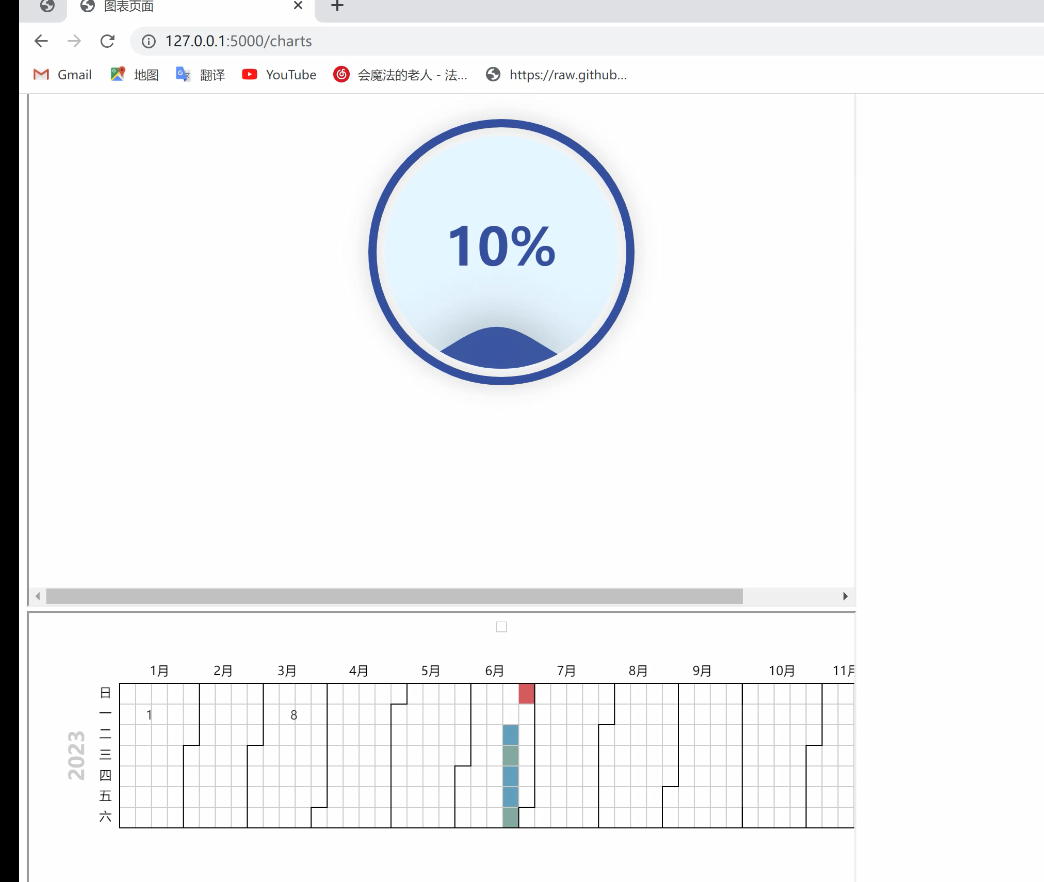
2. `liquid_chart()`: 绘制水球图,展示人数占比或比例的可视化效果。
3. `calendar_chart()`: 绘制日历图,展示日期和人数之间的关系。
4. `sunburst_chart()`: 绘制旭日图,展示数据的层级结构和组成关系。
5. `timeline_chart()`: 绘制时间线轮播图,展示不同时间点的数据变化。
6. `line_chart()`: 绘制折线图,展示日期与公司人数之间的趋势。
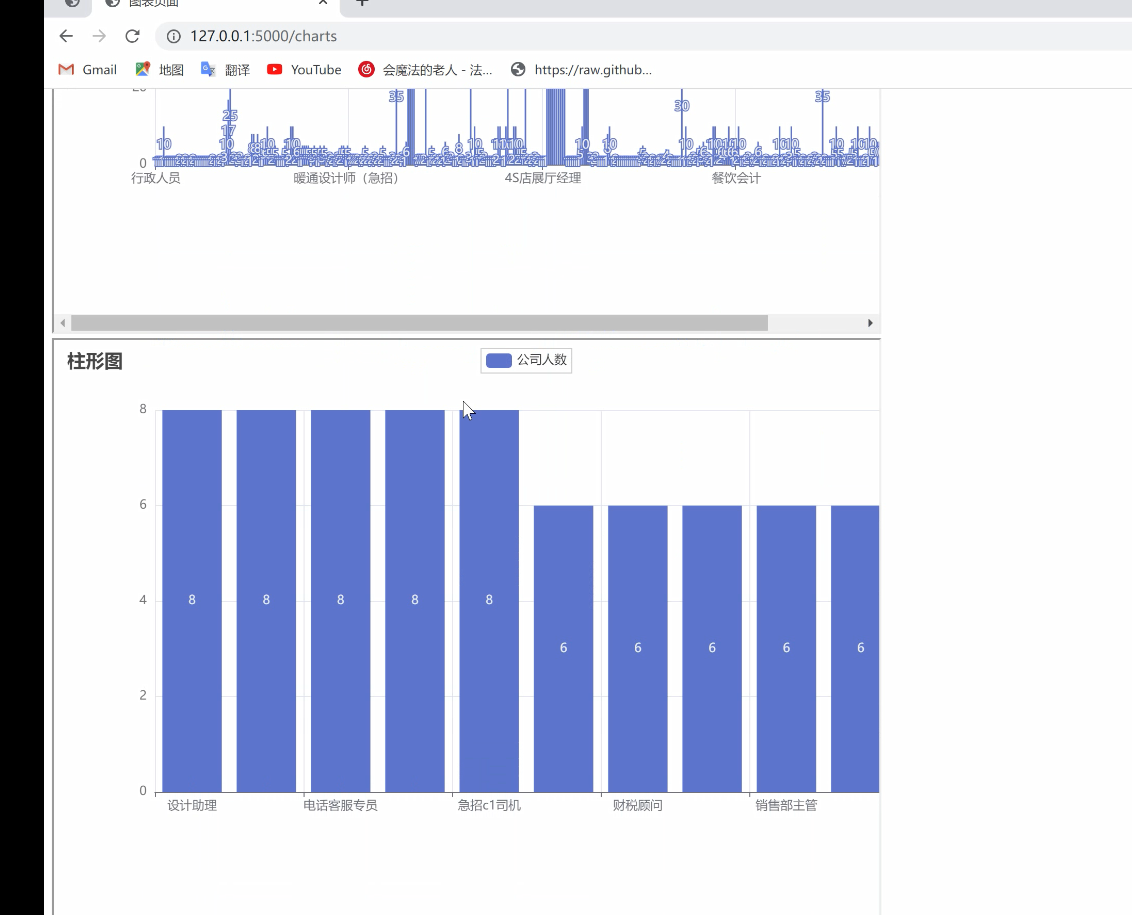
7. `bar_chart()`: 绘制柱形图,展示职位与公司人数之间的关系。
8. `bar_ten_chart()`: 绘制筛选出人数前十大的柱形图。
9. `barh_chart()`: 绘制条形图,展示职位与公司人数之间的关系。
10. `stacked_bar_chart()`: 绘制堆叠图,展示不同学历人数的分布情况。
11. `scatter_chart_people()`: 绘制散点图,展示日期与公司人数之间的关系。
12. `scatter_chart_salaries()`: 绘制散点图,展示工资与公司人数之间的关系。
13. `pie_chart()`: 绘制饼状图,展示职位分布情况。
14. `pie_chart_ten()`: 绘制筛选出人数前十大的饼状图。
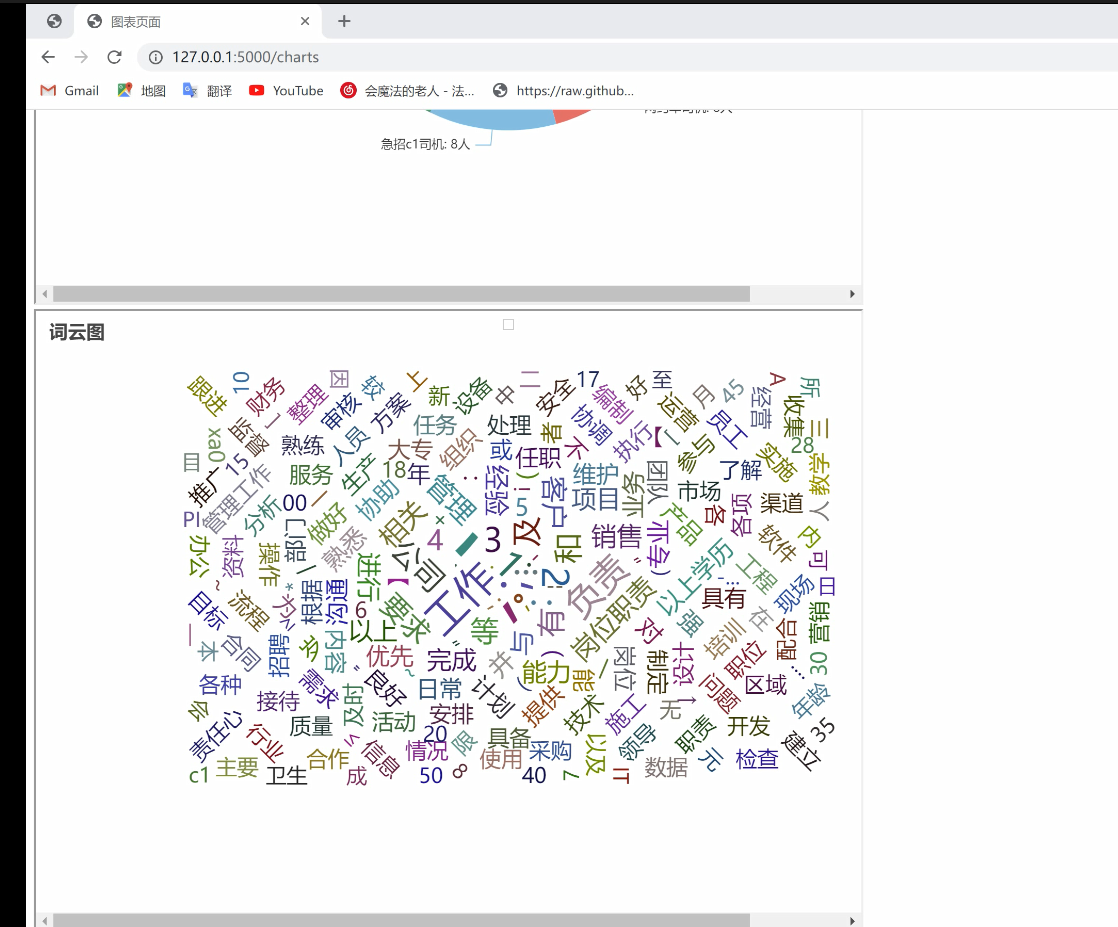
15. `wordcloud()`: 读取文本文件并生成词云图,展示文本中词语的频率分布情况。
数据的清理:
1. 打开CSV文件并创建一个CSV reader对象。使用`with open('data.csv', 'r', encoding='utf-8') as csvfile`语句打开CSV文件,并通过`csv.reader(csvfile)`创建一个CSV reader对象,用于逐行读取CSV文件中的数据。
2. 跳过第一行包含列标题的行。使用`next(reader)`语句跳过CSV文件中的第一行,即包含列标题的行。
3. 遍历CSV文件的每一行,并将数据添加到列表中。通过`for row in reader`语句,对CSV文件中的每一行进行遍历,并使用`data.append(row)`将每一行的数据添加到名为`data`的列表中。
4. 对工资字段进行清理和转换。在`for salary in salaries1`的循环中,对工资字段进行逐个处理。首先,使用正则表达式提取工资字段中的有效数字部分,即工资值。通过`match = re.search(r'(\d+(?:\.\d+)?)', salary)`使用正则表达式模式匹配工资字段中的数字部分。如果找到匹配项,则提取工资值,并将其转换为浮点数类型。然后,根据工资字段中的后缀('K'代表千,'M'代表百万),调整工资值的大小。最后,将处理后的工资值添加到名为`salaries`的列表中。
该代码中的数据清理步骤通过对工资字段的处理来实现。它使用正则表达式提取有效数字部分,并根据后缀进行工资值的调整和转换,最终得到一个经过清理和转换的工资数据列表。
数据爬取
这段代码的实现过程如下:
1. 首先,通过发送 HTTP GET 请求获取网页的内容,使用的是 `requests.get(url,headers={'User-Agent': UserAgent(family='chrome').random()})`。其中,`url` 是要访问的网页的链接,`headers` 参数用于设置请求头,这里使用了随机的 User-Agent。
2. 将获取到的网页内容转换为可解析的 HTML 对象,使用的是 `etree.HTML(resp)`,其中 `resp` 是请求返回的内容。
3. 使用循环遍历的方式,从 HTML 对象中提取出需要的数据。循环从 1 到 20,即提取前 20 个数据。
4. 通过 XPath 表达式提取职位名称,工资,地区,日期,公司,人数,学历,工作经验和公司性质等信息,使用的是 `html.xpath()` 方法。XPath 表达式指定了数据所在的位置。
5. 将提取到的数据进行字符串处理,去除多余的字符,如 `'['` 和 `']'`。
6. 将处理后的数据存储到相应的变量中,如 `job_name`、`wage`、`address` 等。
7. 这段代码的最后一行将一个变量 `cond` 存储为字符串,去除多余的字符。
requests 库发送 HTTP 请求获取网页内容,使用了 lxml 库解析 HTML,然后通过 XPath 表达式提取所需数据,并对提取的数据进行字符串处理,最终将数据存储到相应的变量中。