摘要:
人们在日常生活中也需要阅读各式各样的电子文档,有时候他们希望不用通读文本就能获得自己想要的信息。而近年来,自然语言处理(NLP)作为人工智能的一个重要领域得到了飞速发展,因此,本文通过比较不同的方法,构建基于自然语言处理技术的智能阅读模型,以解决此类问题。
整个解题过程分为以下几个步骤:
第一步对智能阅读模型中的阅读材料以及问答训练集进行数据预处理,对训练集中数据的特征有一个清晰的了解,并对训练集进行去噪处理,除去空回答、重复回答等无效回答,防止干扰训练。
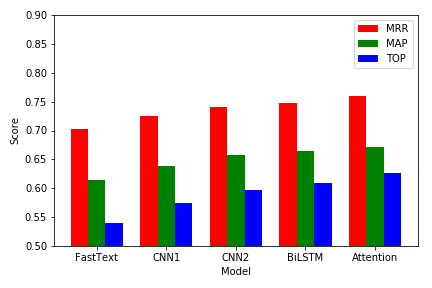
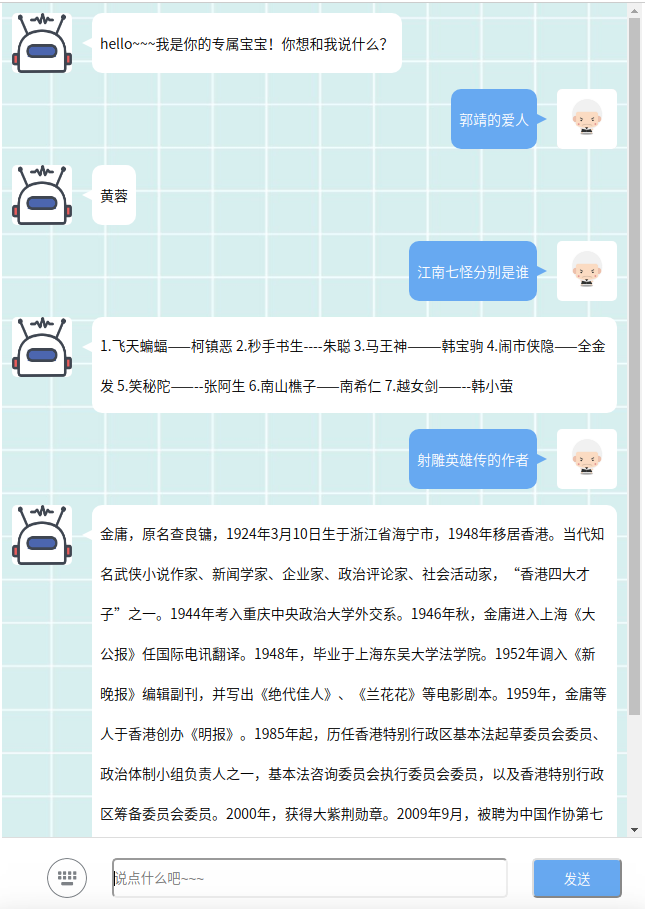
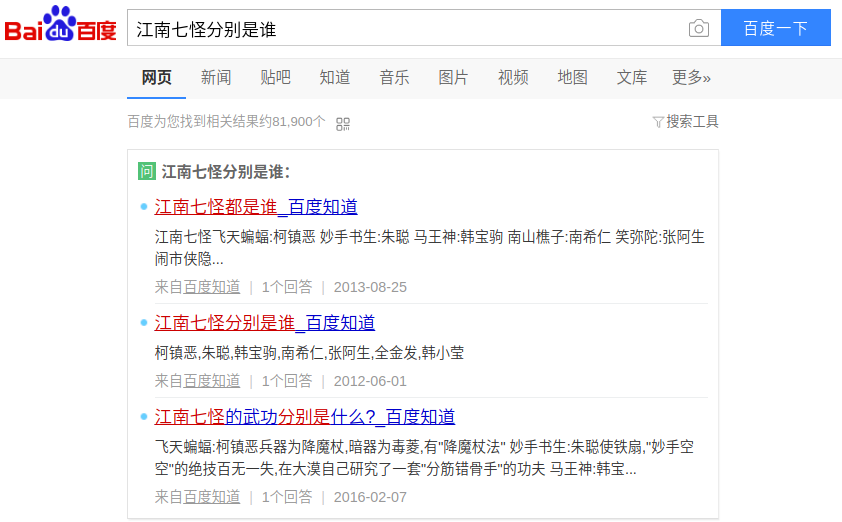
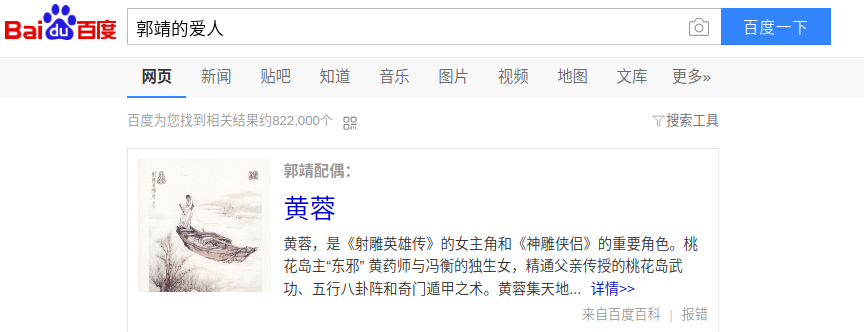
第二步选取经典文本“射雕英雄传”进行实验,通过使用词频-逆文件频率(TF-IDF)模型以及基于奇异值矩阵分解(SVD)的潜在语义索引模型(LSI)进行关键词匹配,得出较佳答案。
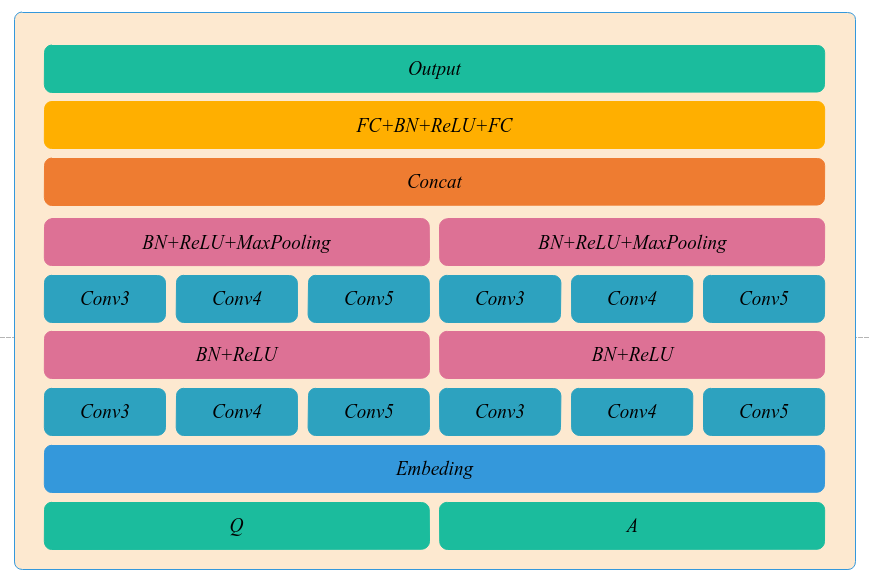
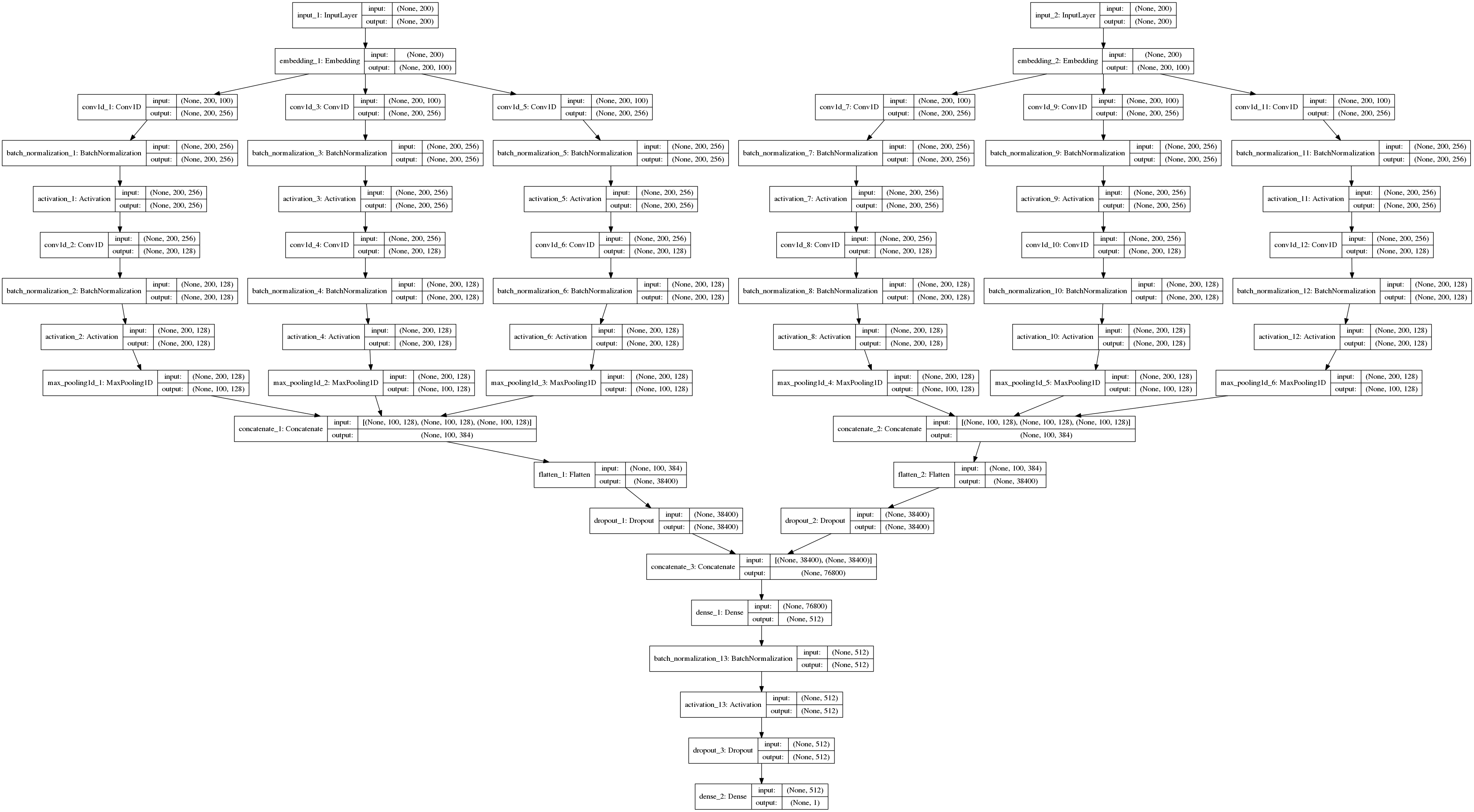
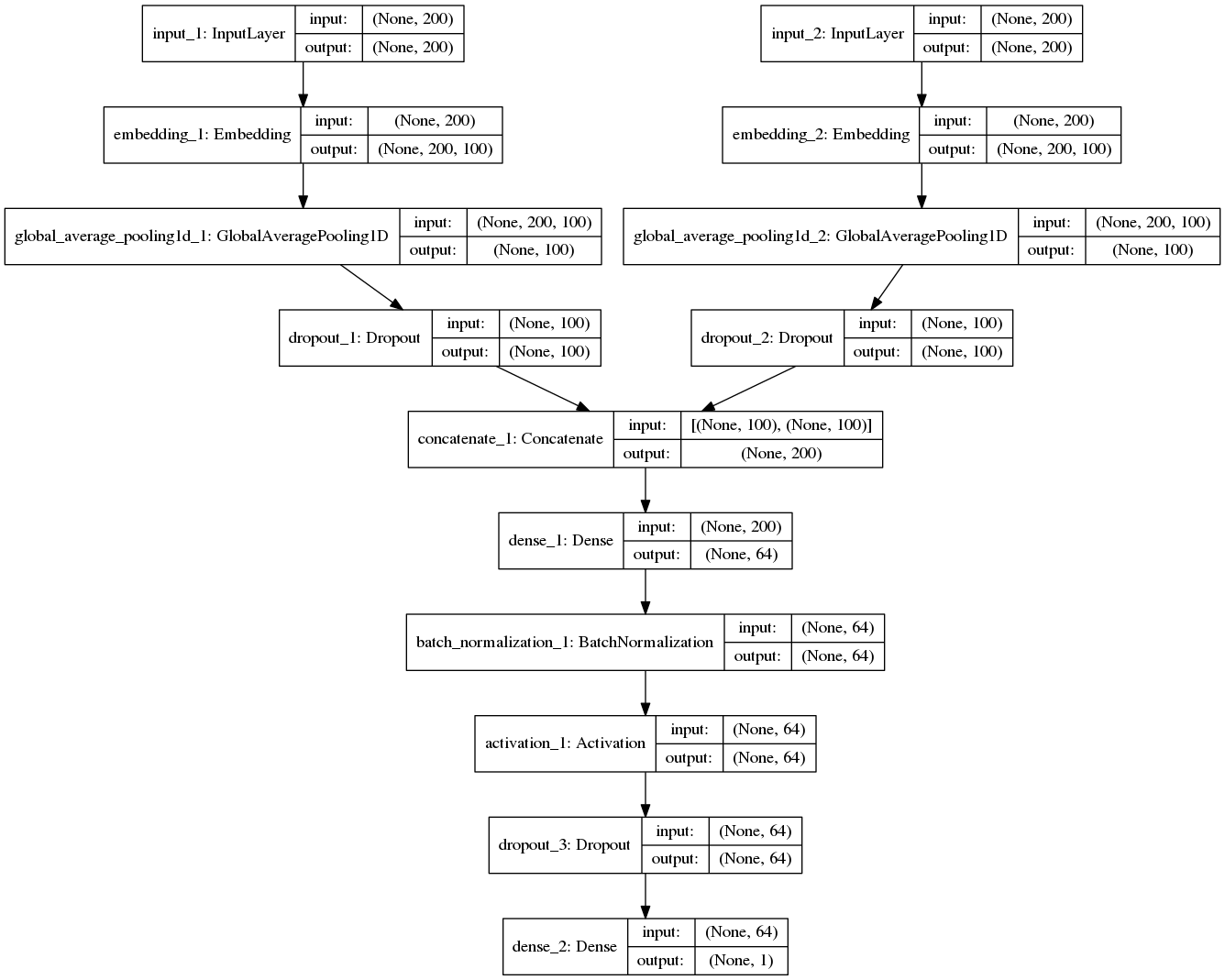
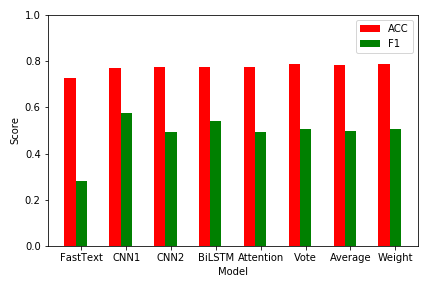
第三步根据经典的文本分类卷积神经网络模型,我们设计了一个更深更复杂的卷积神经网络模型。通过词嵌入后,分别对问题和关键词匹配结果中的回答进行两次卷积核大小为3、4、5的卷积操作,经过最大池化层后,将池化的向量连接起来。并通过使用 ReLU 激活函数,防止反向传播过程中的梯度问题(梯度消失和梯度爆炸)以及使用 Batch Normalization 批规范化,加速收敛,最终选取置信度前15的答案作为候选答案。随后计算得到准确率为77.0492%, F1-score为0.5767,以此来评价模型的优劣,并设计测试用例查看模型运行结果。
实验最后分析并评估了该智能阅读系统的泛化能力,并简要介绍了未来的计划:通过改进损失函数,构建基于web开放域的问答系统以及研究基于众包的智能阅读数据服务来完善该智能阅读模型。
关键词: TF-IDF,LSI,智能阅读模型,卷积神经网络,自然语言处理
An Intelligent Reading Model Based on Latent Semantic Index and Convolutional Neural Network
Abstract:
People need to read a variety of electronic documents in their daily lives. But sometimes they want to obtain the information they want without reading through the text. In recent years, natural language processing (NLP) has been rapidly developed as an important area of artificial intelligence. Therefore, this article compares different methods to construct an intelligent reading model based on natural language processing technology to solve such problems.
The entire problem-solving process is divided into the following steps:
The first step is to preprocess the reading materials and the question and answer training set in the intelligent reading model, to have a clear understanding of the characteristics of the training centralized data. Then we denoise the training set by eliminating null answers, repeated answers and other invalid answers to prevent interference with training.
In the second step, the classical text “Legends of the Condor Heroes” was chosen to conduct experiments. The key words were matched by using the word frequency-inverse document frequency(TF-IDF) model and the latent semantic index(LSI) model based on singular value matrix decomposition to obtain a better answer.
The third step is to design a deeper and more complex convolutional neural network model based on the classic text classification convolutional neural network model. After word embedding, the convolution operation with the size of 3, 4, and 5 is performed twice for the answers in the problem and keyword matching results. After the largest pooled layer, the pooled vectors are connected. And by using the ReLU activation function to prevent gradient problems (gradient disappearance and gradient explosion) in the back propagation process and batch normalization using Batch Normalization, accelerating convergence, the final confidence level 15 answers were selected as candidate answers. Afterwards, the accuracy rate is 77.0492% and F1-score is 0.5767. Thus the merits and demerits of the model are evaluated, and then the test cases are designed to see the results of the model.
Finally, the experiment analyzes and evaluates the generalization ability of the intelligent reading system, and introduces our future work: to improve the intelligent reading model by improving the loss function, constructing a question-answering system based on the open domain of the web, and researching intelligent reading data services based on crowdsourcing.
Keywords: TF-IDF, LSI, intelligent reading model, natural language process, convolutional neural network
目录
一、 引言
二、 模型框架
三、 方案介绍
3.1 数据分析与预处理
3.1.1 数据分析
3.1.2 数据预处理
3.2 关键词匹配
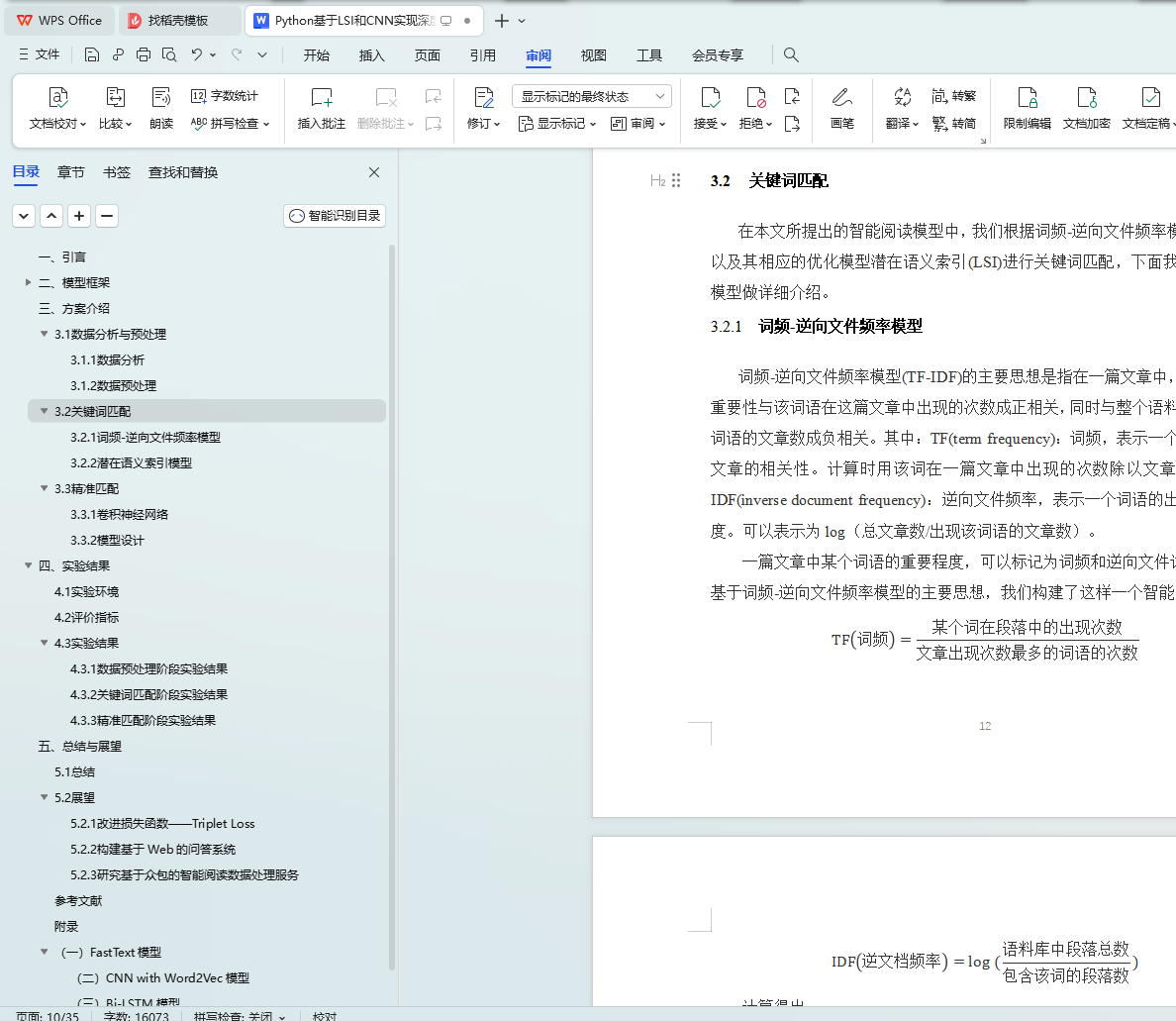
3.2.1 词频-逆向文件频率模型
3.2.2 潜在语义索引模型
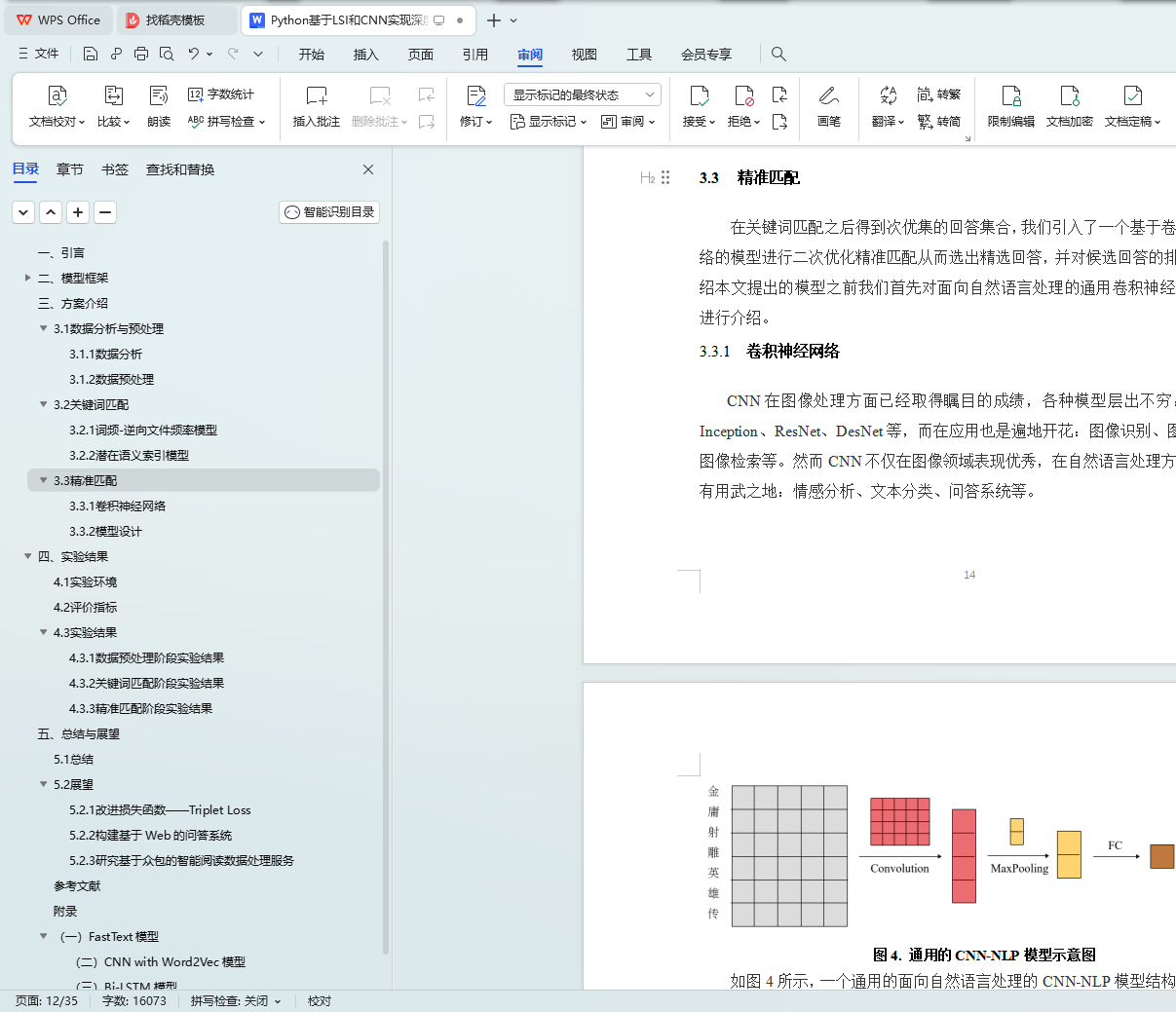
3.3 精准匹配
3.3.1 卷积神经网络
3.3.2 模型设计
四、 实验结果
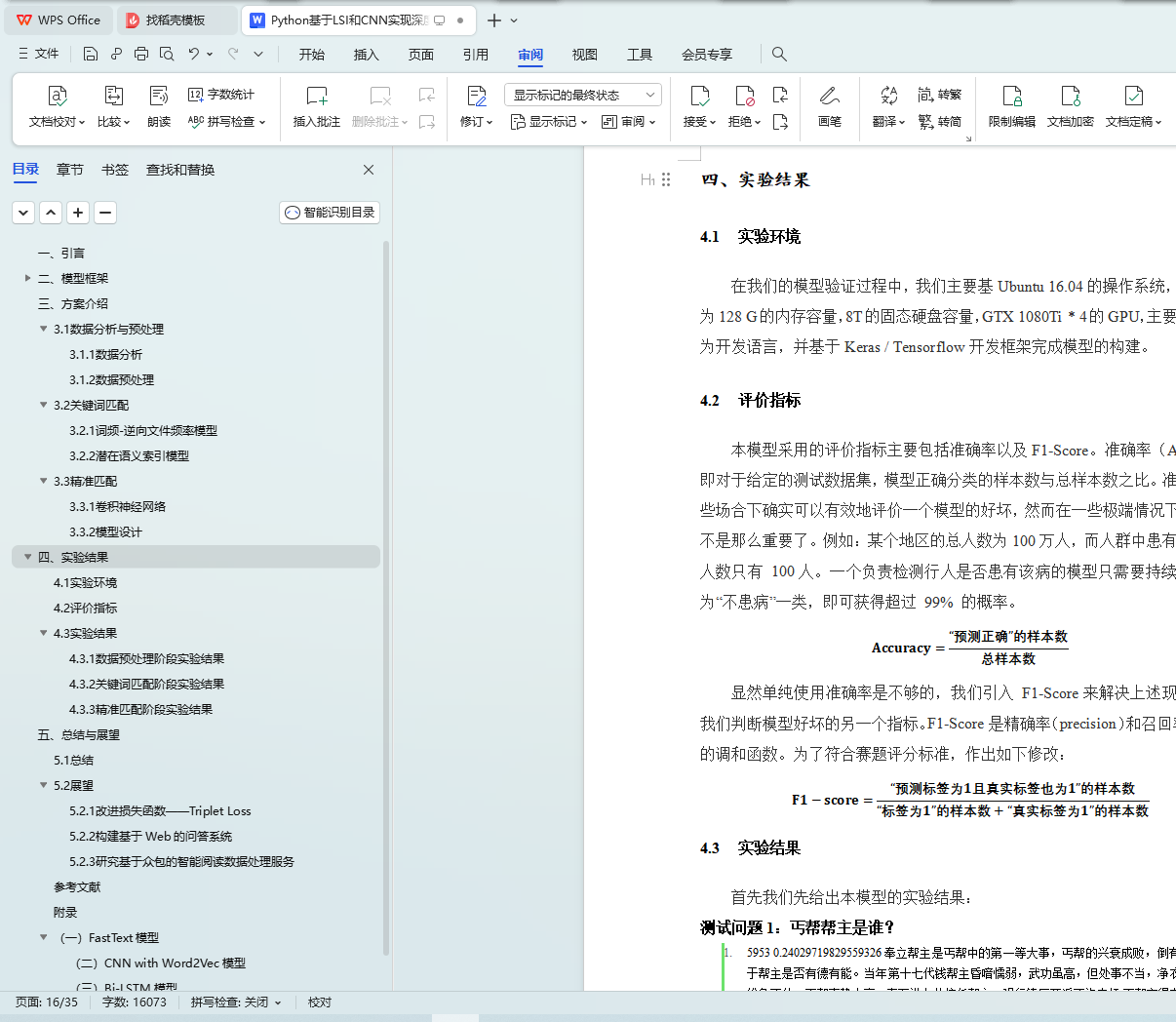
4.1 实验环境
4.2 评价指标
4.3 实验结果
4.3.1 数据预处理阶段实验结果
4.3.2 关键词匹配阶段实验结果
4.3.3 精准匹配阶段实验结果
五、 总结与展望
5.1 总结
5.2 展望
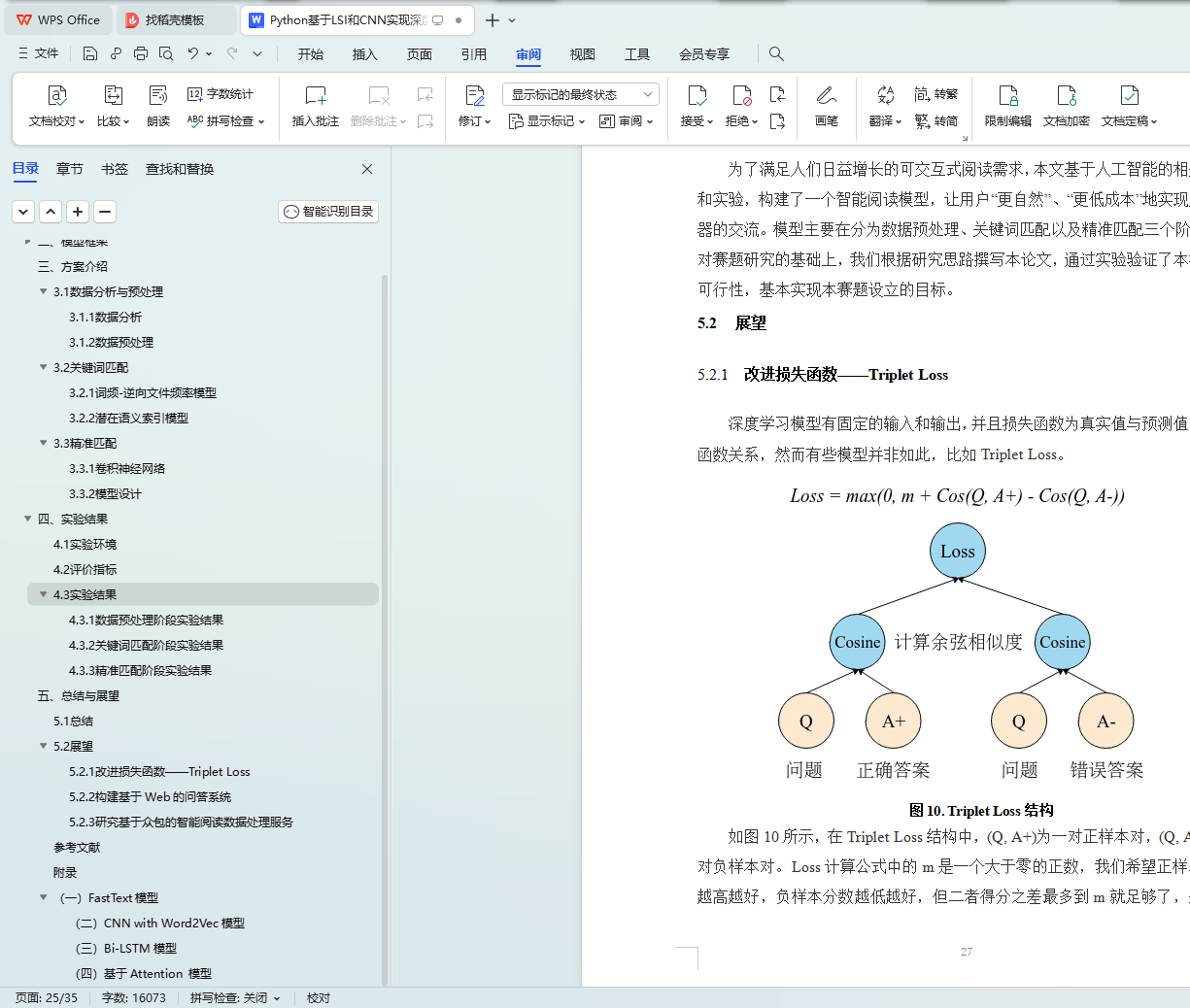
5.2.1 改进损失函数――Triplet Loss
5.2.2 构建基于Web的问答系统
5.2.3 研究基于众包的智能阅读数据处理服务
参考文献
附录
(一)FastText模型
(二)CNN with Word2Vec模型
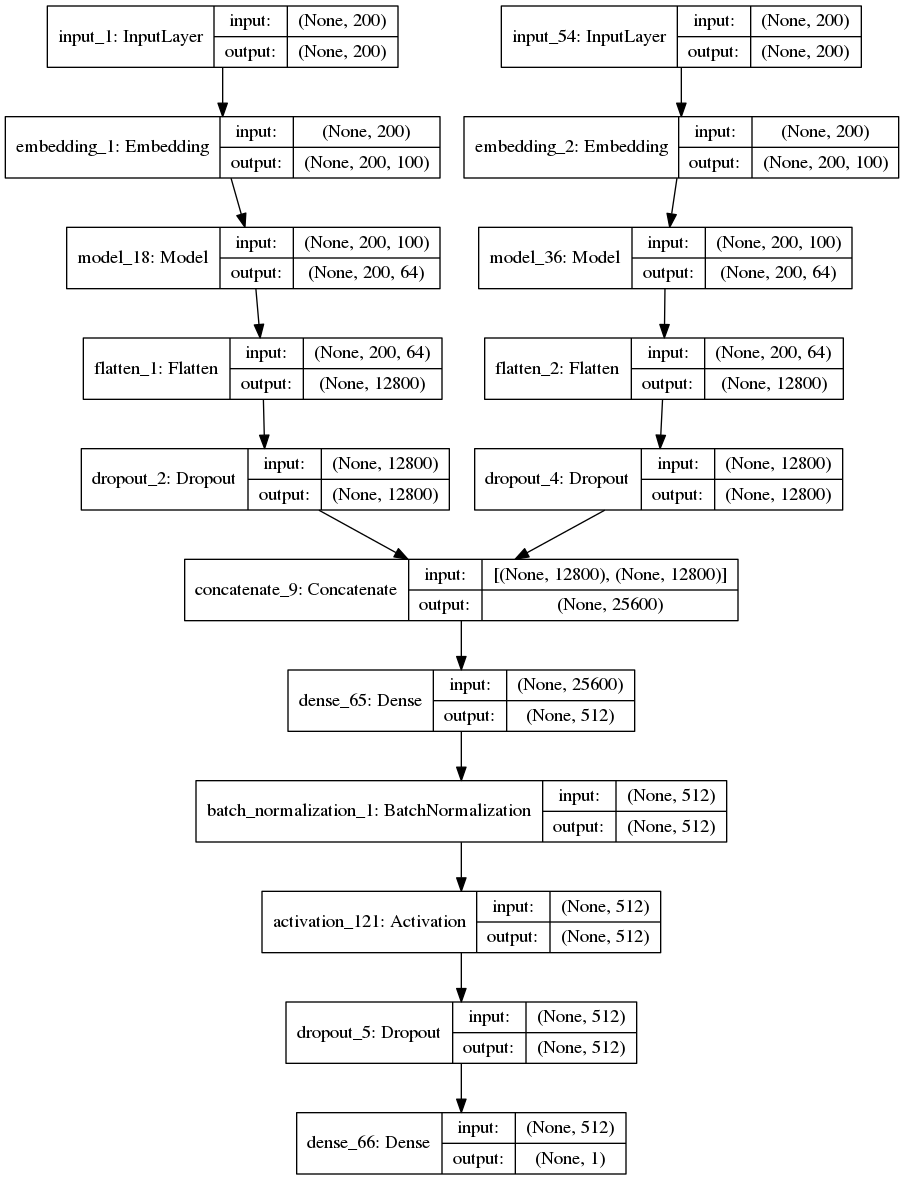
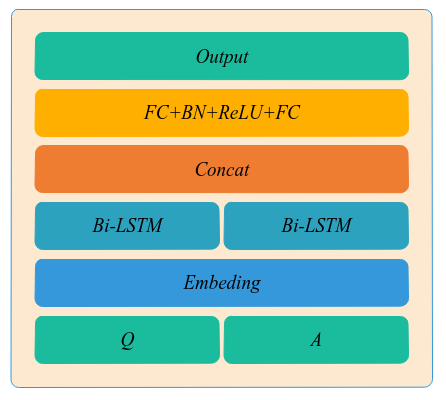
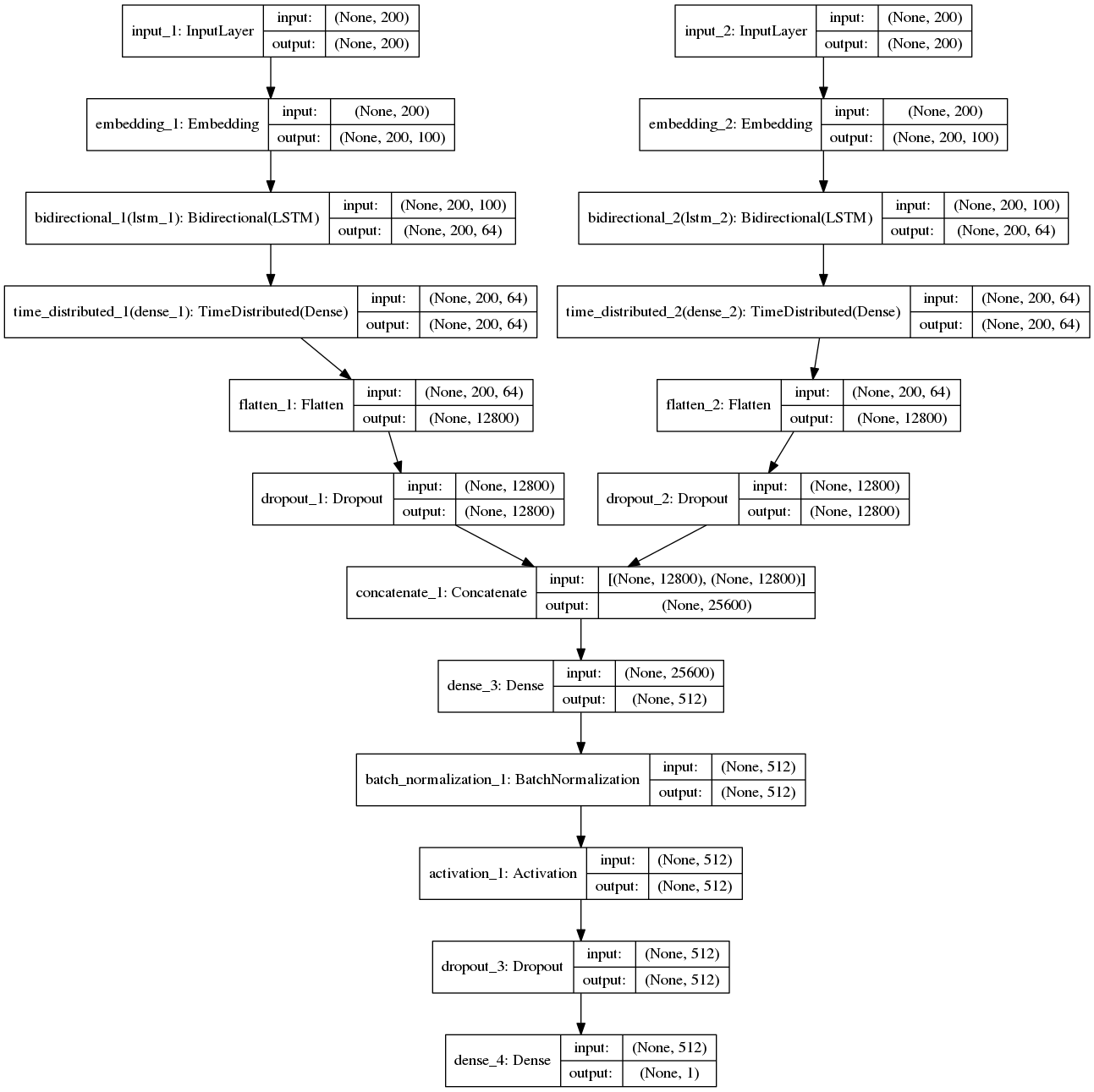
(三)Bi-LSTM模型
(四)基于Attention 模型