1 引言
在当今数字化的世界中,信息是至关重要的资源。互联网作为信息的主要来源,每天生产着巨大的数据量,包括文本、图像、音频和视频等多种形式的信息。为了有效地获取、分析和利用这一海量数据,自动化工具如网络爬虫显得尤为关键。网络爬虫是一种自动化程序,设计用于在互联网上抓取和手机信息,类似于搜索引擎使用的机制。本实验旨在深入研究网络爬虫的设计与实现,以及探索如何利用他们来获取有价值的数据。
1.1 目的
本实验的主要目标是深入了解网络爬虫的内部工作原理,并展示如何设计和实现一个网络爬虫,以达到特定的目标。我们将探讨网络爬虫的工作流程、数据抓取和存储、以及数据处理等关键方面。通过实际操作,我们将学习如何构建一个可用的网络爬虫系统,为进一步的数据分析和应用提供基础。
1.2 背景
网络爬虫在现代信息时代扮演着不可或缺的角色。它们被广泛应用于多个领域,包括数据挖掘、信息检索、竞争情报、新闻采集和市场调研。通过网络爬虫,我们可以自动抓取和分析网页上的内容,从中提取有用的信息,以支持各种应用,从搜索引擎提供有关网页的数据,到企业利用网络爬虫来监测市场竞争对手的动态。
即将毕业的我们同时也面对着就业的压力,我们可以利用爬虫技术,从招聘网站上自动抓取招聘信息,包括职位描述、公司信息、薪资等。这将帮助即将毕业的大学生们更轻松地浏览和筛选招聘信息。
2 需求分析
2.1 序言
网络爬虫的需求分析旨在确定项目的目标、范围和期望结果。本部分将详细介绍爬取招聘信息的网络爬虫项目的需求和特点。
2.2 项目简介
本项目的主要目标是创建一个网络爬虫,能够从招聘网站上自动抓取招聘信息,包括职位描述、公司信息、薪资等。这将帮助求职者更轻松地浏览和筛选招聘信息。
2.2.1 系统标识
Python为主要编程语言,支持Windows操作系统
2.2.2 系统功能
简易Web浏览器的主要功能:1、设计文本框,用于输入网址;2、设计浏览按钮,用于显示该网址的网页;3、设计前进与后退按钮,用于翻页;4、界面设计美观、功能布局合理。
(1)搜索功能
可以根据需要输入对应URL 或关键词进行搜索。若判断出是URL则进行URL网址解析,若识别出是关键词则进行百度关键词搜索。考虑到人性化,显示相对应网址的image图片进行显示。以及设置刷新以及跳转按钮,方便各种情况下的返回。
(2)设置功能
退后和前进按钮控制翻页,存储多级历史进行跳转,并设置百度搜索主页,方便国内搜索使用,设置功能内含待开发的辅助性功能。
2.3 模块划分
项目可以分为以下关键模块:
(1)数据抓取模块:用于从目标招聘网站上获取数据。这包括发送HTTP请求、解析HTML内容以提取信息。
(2)数据存储模块:负责将抓取到的数据保存到数据库或文件中,以备后续分析和展示。
(3)用户界面模块(可选):用于与用户交互,允许用户指定搜索条件和查看结果。
2.3.1 搜索模块
用户根据自己需求进行URL解析或者关键词百度搜索。
2.3.2 设置模块
用户根据自己需求进行网页的前进和后退翻页,一键返回百度主页功能和设置浏览器辅助性功能。
2.3.3 辅助模块
搜索栏左边image图片显示URL解析图片,方便用户知道所处页面;搜索栏右边image按钮图片显示跳转和刷新功能,在特定条件下互相转换,方便用户进行搜索内容。
2.3.4 页面模块
用于展示一个web页面,位于应用中间位置,它使用的内核是webkit引擎,4.4版本之后,直接使用Chrome作为内置网页浏览器。
2.4 模块图
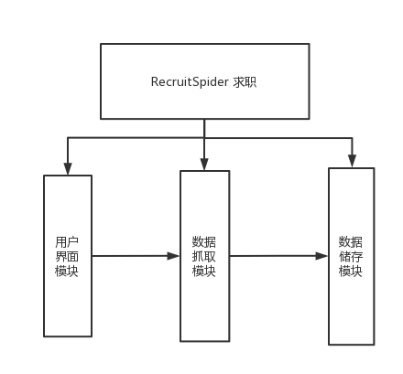
图1 RecruitSpider 求职 模块图
2.5流程图
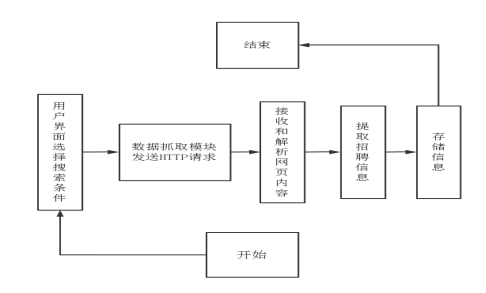
图2 RecruitSpider 求职 流程图
2.6性能要求
数据抓取模块的性能需求:这个模块主要影响爬虫的抓取速度和覆盖范围。你需要考虑你想要抓取的招聘网站的数量、类型、规模、更新频率等因素,以及你想要抓取的信息的种类、数量、质量等因素。你还需要考虑爬虫的友好性,即遵守robots协议,控制访问频率,避免给目标网站造成过大的负载和干扰。一般来说,数据抓取模块的性能需求可以用每秒能够下载的网页数量或者每天能够下载的网页总量来衡量。
数据存储模块的性能需求:这个模块主要影响爬虫的存储空间和数据管理能力。你需要考虑你抓取到的数据的大小、格式、结构等因素,以及你想要对数据进行什么样的处理、分析、展示等操作。你还需要考虑数据存储模块的可靠性,即保证数据不丢失、不损坏、不重复等。一般来说,数据存储模块的性能需求可以用所需的存储空间大小或者所能支持的数据处理操作数量来衡量。
用户界面模块的性能需求:这个模块主要影响用户使用爬虫系统的体验和效果。你需要考虑你想要提供给用户什么样的功能、界面、交互等因素,以及用户对系统的响应速度、准确度、易用性等方面有什么样的期望和要求。你还需要考虑用户界面模块的兼容性,即适应不同的操作系统、浏览器、设备等环境。一般来说,用户界面模块的性能需求可以用所能支持的用户数量或者用户满意度来衡量
页面模块需要能够展示一个web页面,并使用webkit引擎或Chrome作为内置网页浏览器。可能需要使用一些web开发的技术,如QWebEngineView、QWebEnginePage等,来加载和渲染网页。
3 系统设计
3.1总体设计
(暂空)
3.2功能设计
(暂空)
4 系统开发
(暂空)
4.1源程序清单
功能底部栏模块是用于显示一些常用的浏览器功能,如前进、后退、刷新、主页等。可以使用Python的PyQt5库来设计和开发这个模块,具体步骤如下:
・ 首先,需要创建一个QHBoxLayout对象,用于水平布局你的底部栏控件。
・ 然后,需要创建四个QPushButton对象,分别用于实现前进、后退、刷新、主页的功能。可以使用setIcon方法来设置按钮的图标,使用setToolTip方法来设置按钮的提示信息。
・ 接着,需要将这四个按钮添加到水平布局中,使用addWidget方法,并设置合适的间距和对齐方式。
・ 最后,需要将水平布局添加到你的主窗口中,使用setLayout方法,并设置底部栏的位置和大小。
WebChorm网页模块
WebChorm网页模块是用于展示一个web页面,并使用webkit引擎或Chrome作为内置网页浏览器的模块。可以使用Python的PyQt5库来设计和开发这个模块,具体步骤如下:
首先,需要创建一个QWebEngineView对象,用于显示网页内容。可以使用setUrl方法来设置要加载的网页地址,使用load方法来加载网页,使用setHtml方法来显示HTML代码。
然后,需要创建一个QWebEnginePage对象,用于控制网页的行为和交互。可以使用setUrl方法来设置要加载的网页地址,使用load方法来加载网页,使用setHtml方法来显示HTML代码。
接着,需要将QWebEnginePage对象设置为QWebEngineView对象的页面,使用setPage方法。
最后,需要将QWebEngineView对象添加到主窗口中,使用addWidget方法,并设置网页模块的位置和大小。
4.2功能实现
(暂空)
4.2.1 URL链接识别
・ 首先,需要定义一个合适的正则表达式,用于匹配URL的格式。一个常用的正则表达式是r'[a-zA-Z]+://[^\s]*[.com|.cn|.org|.net|.edu]',它可以匹配以http、https、ftp等协议开头,以.com、.cn、.org、.net、.edu等结尾的URL。当然,你也可以根据你的需求修改或扩展这个正则表达式,以适应不同的URL类型。
・ 然后,需要使用re模块的findall函数,将正则表达式作为参数传入,对网页内容进行搜索,返回一个包含所有匹配结果的列表。例如,如果想要从某个网页中提取所有的URL,需用以下代码:
import reimport urllib.request
url = '[1](https://www.runoob.com/python3/python-urllib.html)'
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
pattern = r'[a-zA-Z]+://[^\s]*[.com|.cn|.org|.net|.edu]'
urls = re.findall(pattern, html)print(urls)
・ 最后,需要使用urllib.parse模块的urlparse函数,对每个匹配到的URL进行解析,返回一个包含URL各个部分的namedtuple对象。这些部分包括scheme(协议)、netloc(网络位置)、path(路径)、params(参数)、query(查询)和fragment(片段)。我们可以根据你的需求对这些部分进行进一步的处理或分析。例如,如果想要获取每个URL的主机名和端口号,需用以下代码:
import urllib.parse
for url in urls:
result = urllib.parse.urlparse(url)
hostname = result.hostname
port = result.port
print(hostname, port)
4.2.2Web浏览器基础设计
・ 设计文本框,用于输入网址或关键词
・ 设计浏览按钮,用于显示该网址的网页
・ 设计前进与后退按钮,用于翻页
・ 界面设计美观、功能布局合理
・ 搜索功能,可以根据需要输入对应URL或关键词进行搜索,若判断出是URL则进行URL网址解析,若识别出是关键词则进行百度关键词搜索
・ 设置功能,退后和前进按钮控制翻页,存储多级历史进行跳转,并设置百度搜索主页,方便国内搜索使用
・ 为了实现Web浏览器基础设计这一功能,需要使用Python的GUI库之一,例如Tkinter、PyQt5、wxPython等。这些库都提供了创建和管理窗口、按钮、文本框、菜单等组件的方法,以及绑定和处理用户输入和事件的机制。
・ 下面是一些关键步骤
・ 导入PyQt5模块,并创建一个主窗口对象,例如app = QApplication(sys.argv), window = QMainWindow()
・ 在主窗口上添加一个文本框对象,用于输入网址或关键词,例如entry = QLineEdit(window)
・ 在主窗口上添加一个按钮对象,用于触发浏览功能,例如button = QPushButton('浏览', window)
・ 在主窗口上添加一个网页视图对象,用于显示网页内容,例如webview = QWebEngineView(window)
・ 定义一个函数,用于处理按钮点击事件,例如def browse():
・ 在该函数中,获取文本框中的内容,并判断是URL还是关键词,例如text = entry.text()
・ 如果是URL,则使用webview对象加载该网址,例如webview.load(QUrl(text))
・ 如果是关键词,则使用webview对象加载百度搜索结果页面,例如webview.load(QUrl('https://www.baidu.com/s?wd=' + text))
・ 将按钮对象与该函数绑定起来,使得点击按钮时执行该函数,例如button.clicked.connect(browse)
・ 调整各个组件的位置和大小,并显示主窗口,例如entry.setGeometry(10, 10, 780, 30), button.setGeometry(800, 10, 80, 30), webview.setGeometry(10, 50, 870, 540), window.resize(900, 600), window.show(), app.exec_()
4.2.3 UI控件点击事情
导入Tkinter模块,并创建一个主窗口对象,例如root = Tk()
在主窗口上添加一个文本框对象,用于输入网址或关键词,例如entry = Entry(root)
在主窗口上添加一个按钮对象,用于触发浏览功能,例如button = Button(root, text='浏览')
定义一个函数,用于处理按钮点击事件,例如def browse():
在该函数中,获取文本框中的内容,并判断是URL还是关键词,例如text = entry.get()
如果是URL,则使用webbrowser模块打开该网址,例如webbrowser.open(text)
如果是关键词,则使用webbrowser模块打开百度搜索结果页面,例如 webbrowser.open('https://www.baidu.com/s?wd=' + text)
将按钮对象与该函数绑定起来,使得点击按钮时执行该函数,例如button['command'] = browse
调整各个组件的位置和大小,并显示主窗口,例如entry.pack(), button.pack(), root.mainloop()
5 系统测试
5.1测试方法
黑盒测试、单元测试、自动化测试等。
学号姓名:本次关于简易Web浏览器的设计,出于对Android平台的好奇,就选择从零基础学习Android平台着手研发,从每个论坛,每集视频,再到几本参考工具书的学习,从一个简单的平台搭建,一个手机模拟器的运行,各样式文件的编辑,一个小小的图片文字转变,再到安卓优秀库和UI框架的涉略。仿佛站在巨人的肩膀上去看那一片风景,虽然说安卓热已经过去了几年,但在学习过程中学习到的能力、思想、Material Design设计思维,大到说一些类似于开源的精神,体验人机交互的魅力,真实得影响到我。安卓的活动、监听、布局、生成等等操作,让我体验到了软件体生命的强大力量。可惜,时间能力有限,很多编程风格还没有完全安卓化,有些比较实用的功能,例如浏览器功能设计,都还没添加。如今,我把代码开源到了自己的Github平台,后续希望有进一步的更新发展,成就感满满。
本次关于简易Web浏览器的设计,使我收货颇多,我本就对Python和爬虫技术感兴趣,这次的作业刚好使我有机会深入学习Python,还能和同学交流心得体会,我们几乎从零开始慢慢学习,分工合作,在我们遇到难以解决的困难时我们也会在网上查找相关资料,视频以及一些文章,这使我体验到了团队合作的乐趣,通过不断地学习我也了解到了编程的魅力.希望将来能学习到更多知识。
