目录
1 引文
2 相关工作
3 逻辑回归算法实现
3.1文本处理
3.1.1分词
3.1.2去停用词
3.2特征提取
3.3 LR模型
3.3.1模型简介
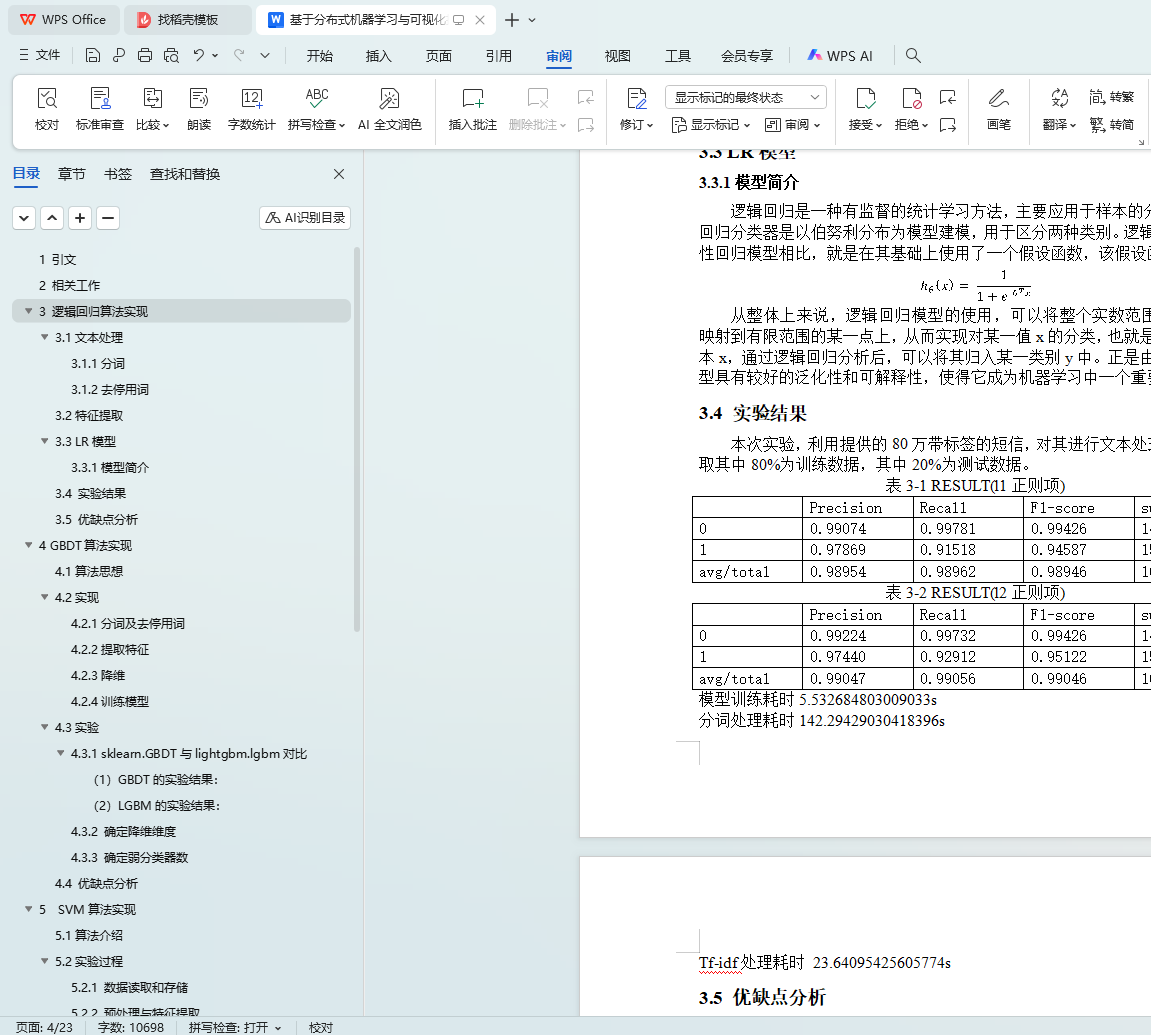
3.4 实验结果
3.5 优缺点分析
4 GBDT算法实现
4.1算法思想
4.2实现
4.2.1分词及去停用词
4.2.2提取特征
4.2.3降维
4.2.4训练模型
4.3实验
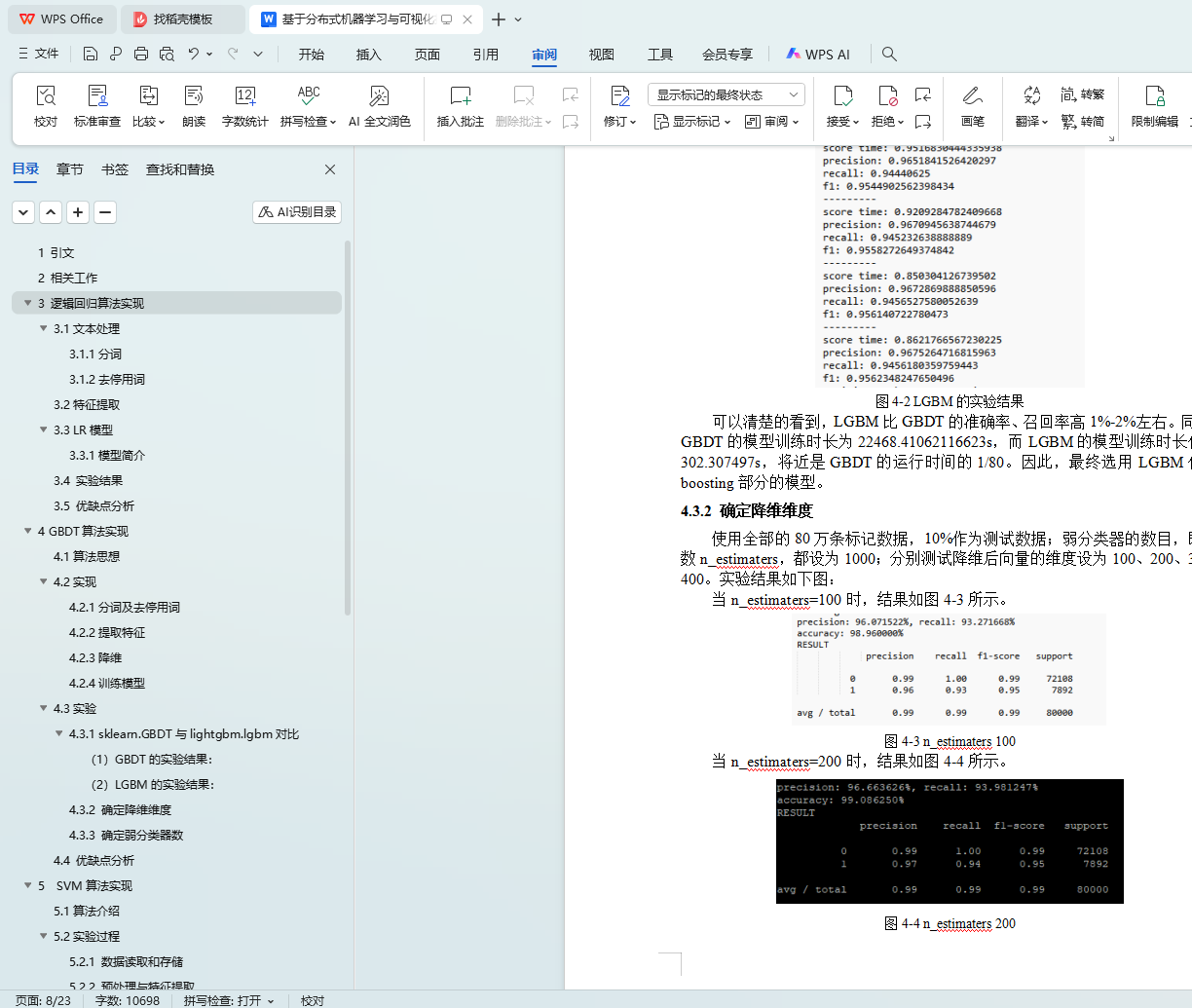
4.3.1 sklearn.GBDT与lightgbm.lgbm对比
4.3.2 确定降维维度
4.3.3 确定弱分类器数
4.4 优缺点分析
5 SVM算法实现
5.1算法介绍
5.2实验过程
5.2.1 数据读取和存储
5.2.2 预处理与特征提取
5.2.3 降维
5.2.4 SVM分类
5.2.5 交叉验证
5.3优缺点分析
6 决策树算法实现
6.1算法思想
6.2算法实现
6.2.1导入短信数据并分词
6.2.2分割训练集和测试集并提取文本特征
6.2.3建立决策树分类器并进行训练
6.3实验结果
6.4优缺点分析及可能改进的方案
7 分布式机器学习算法实现
7.1环境准备
7.2 Hadoop环境搭建
7.3 Spark环境搭建
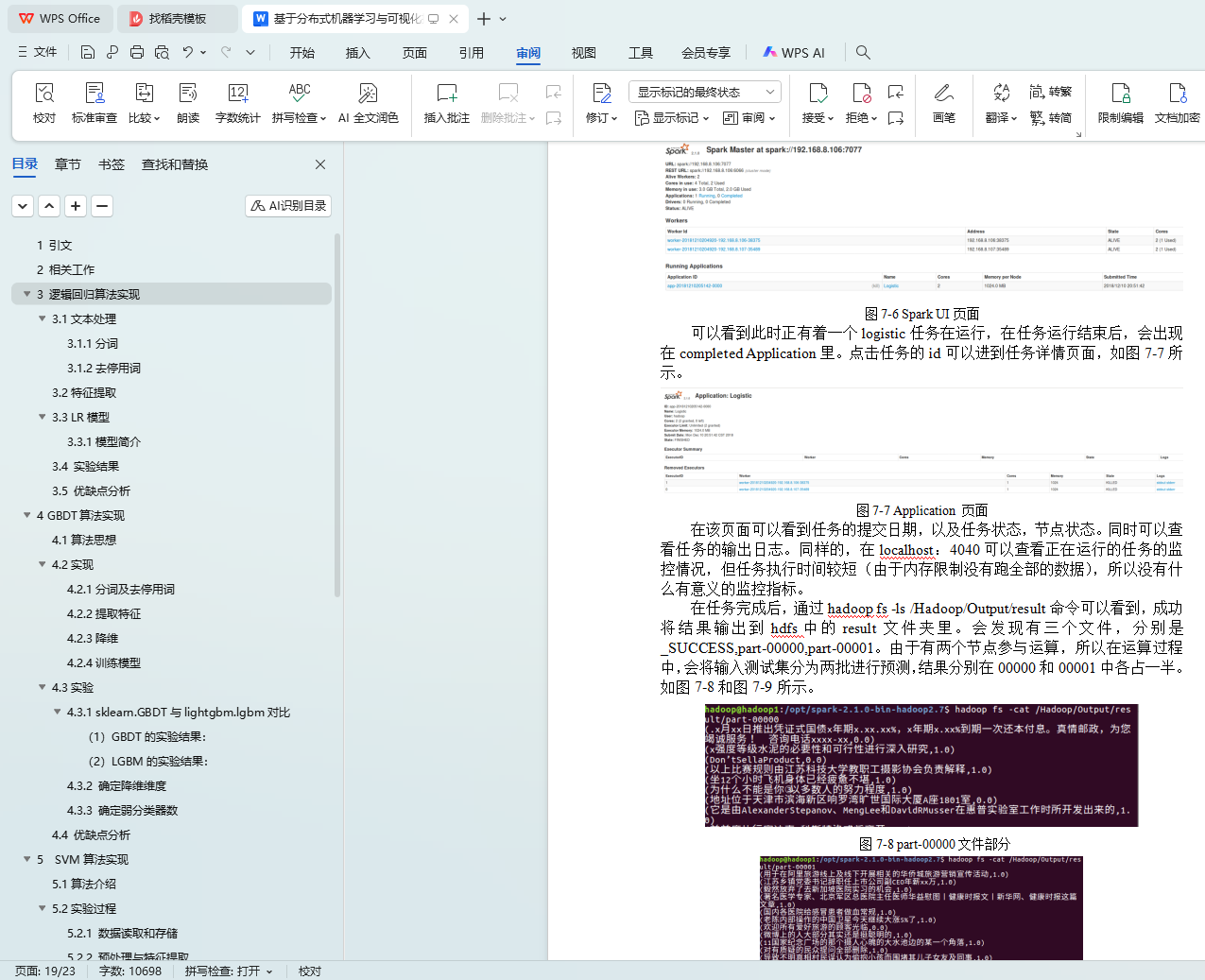
7.4 Spark MLlib逻辑回归实现
7.5 Spark MLlib实验结果
7.5 结论分析
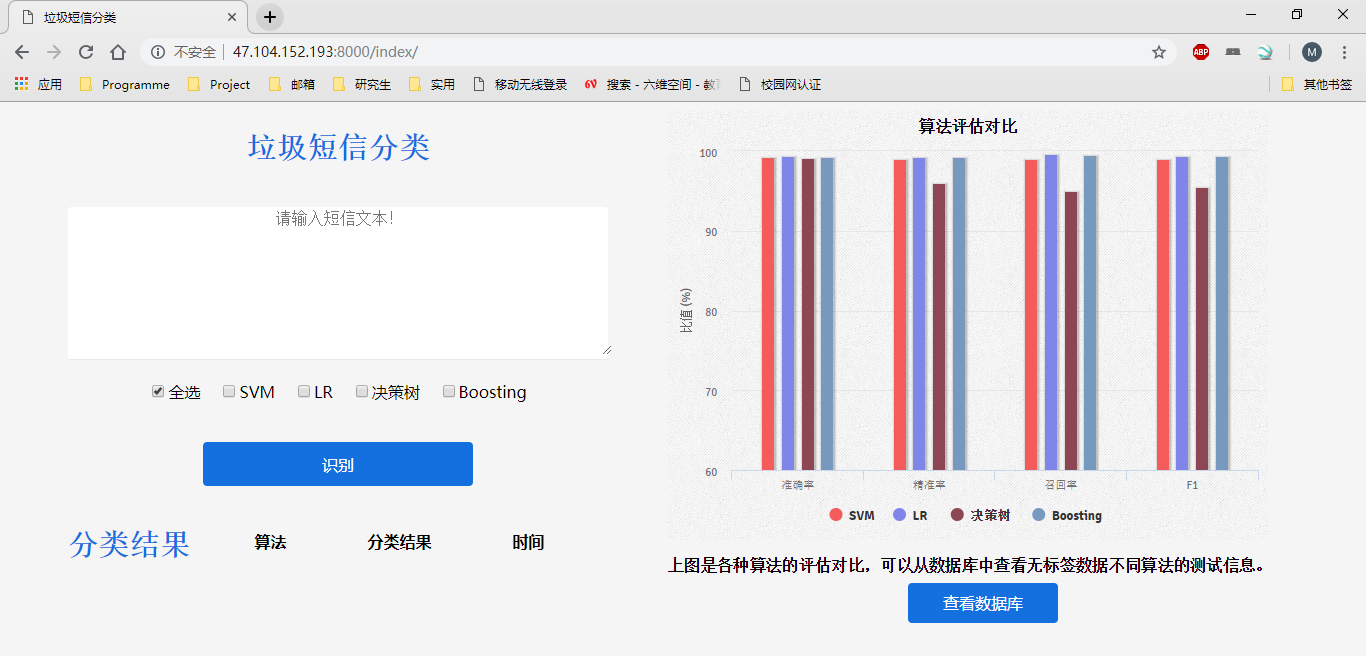
8 可视化系统设计与实现
8.1开发环境
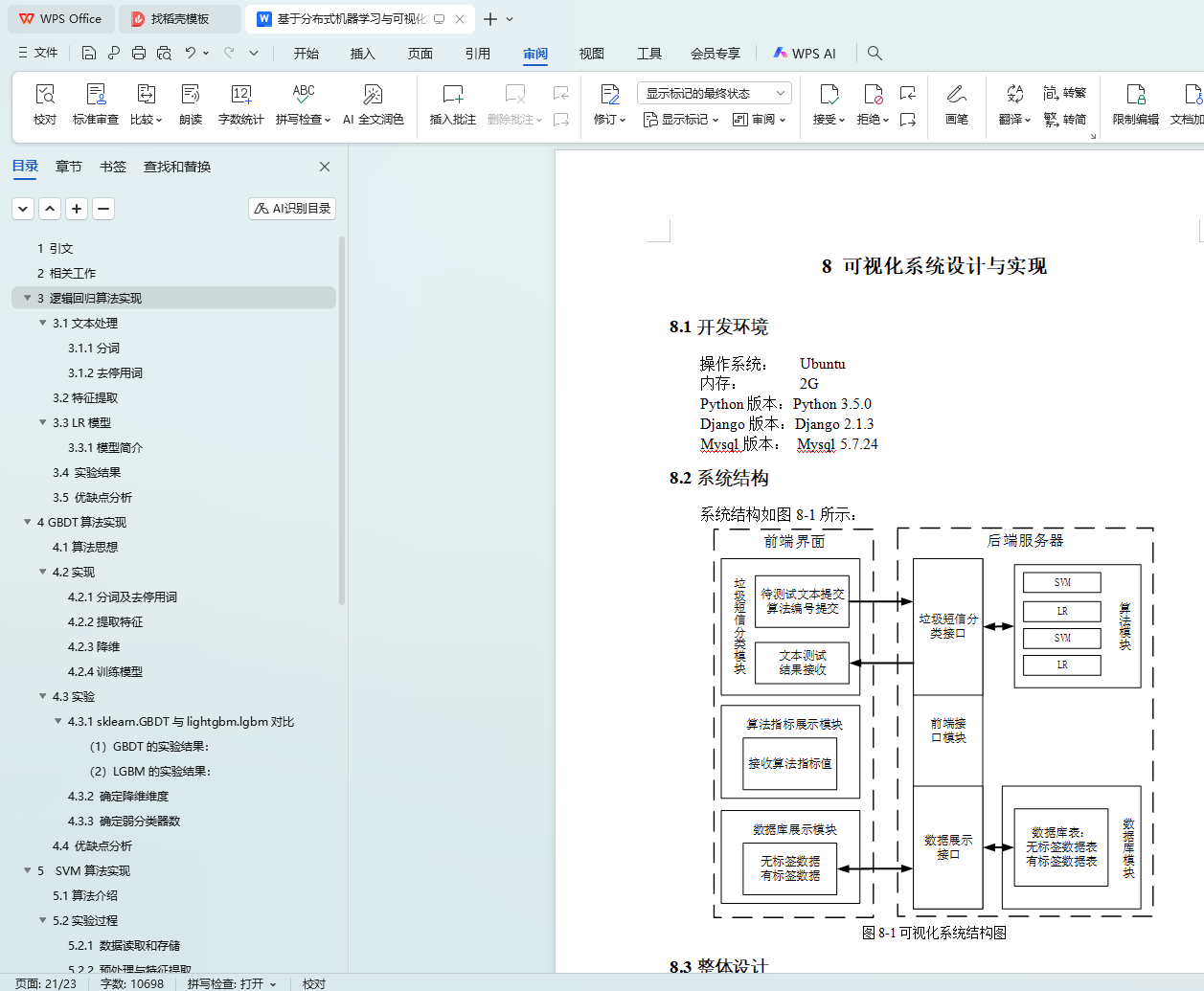
8.2系统结构
8.3整体设计
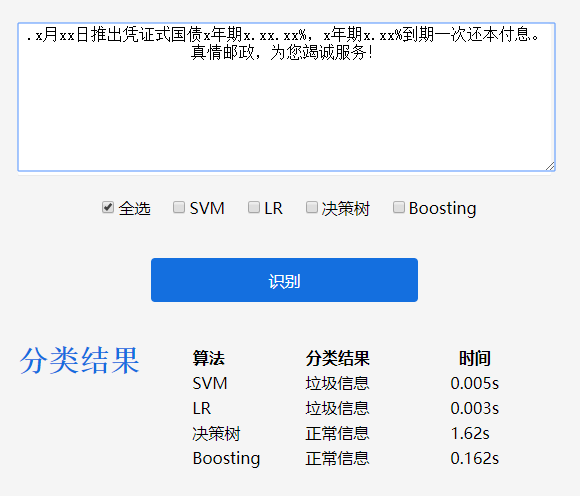
8.3.1 垃圾短信分类模块
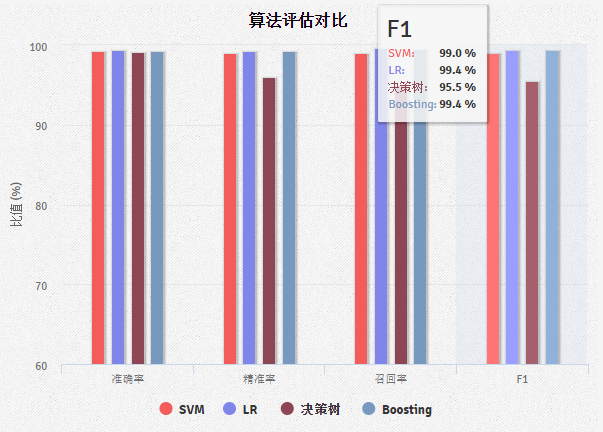
8.3.2 算法指标展示模块
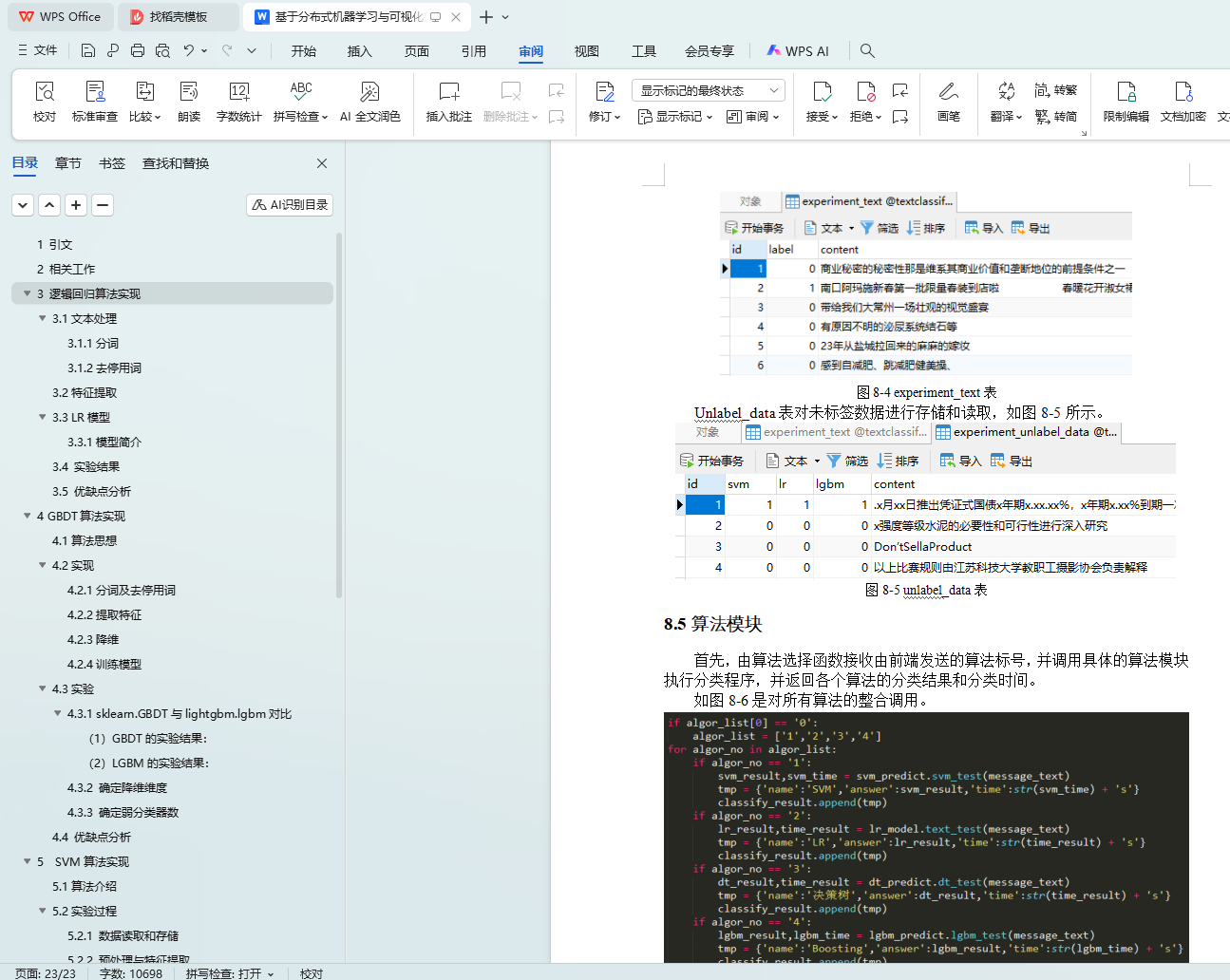
8.4数据库模块
8.4.1 前端展示
8.4.2 后端存储
8.5算法模块
1 引文
本次毕业设计的选题为垃圾短信分类。在老师所给的垃圾短信数据集上,分别实现了逻辑回归、决策树、SVM、GBDT这个四个分类算法。这四个算法都是老师上课提到的算法,通过动手实验,并进行对比,衡量了算法之间的优劣性,并给出了在不同情况下的选择理由。
搭建了Hadoop和Spark分布式环境,并使用Spark MLlib实现了分布式的逻辑回归算法。通过测试,对比了分布式实现机器学习算法和单机的区别。并分析了如何设计一个高效并节省空间的分布式机器学习算法。
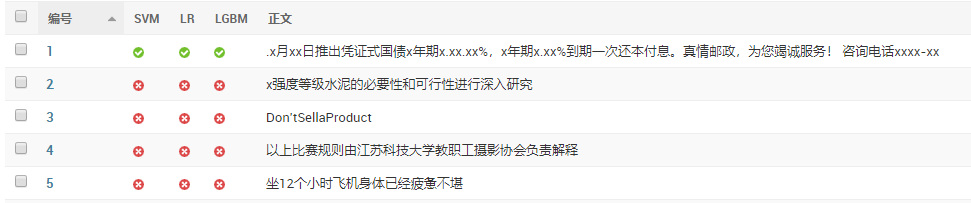
最后设计并实现了一个可视化Web系统,展示了对老师所给垃圾短信数据集的分类结果,以及不同算法的正确率等指标对比。系统在47.104.152.193:8000/index/上部署,并在提交作用中附有使用说明文档。