机器人自动走迷宫-基础搜索与强化学习
1.1 实验背景
在本实验中,要求分别使用基础搜索算法和 Deep QLearning 算法,完成机器人自动走迷宫。 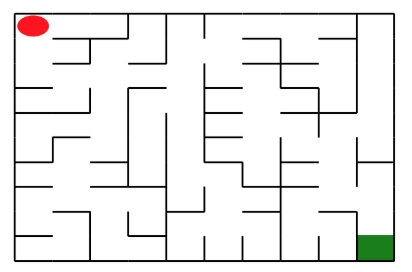
如上图所示,左上角的红色椭圆既是起点也是机器人的初始位置,右下角的绿色方块是出口。
游戏规则为:从起点开始,通过错综复杂的迷宫,到达目标点(出口)。
在任一位置可执行动作包括:向上走 'u'、向右走 'r'、向下走 'd'、向左走 'l'。
・ 执行不同的动作后,根据不同的情况会获得不同的奖励,具体而言,有以下几种情况。
o 撞墙
o 走到出口
o 其余情况
・ 你需要实现基于基础搜索算法和 Deep QLearning 算法的机器人,使机器人自动走到迷宫的出口。
1.2 实验要求
・ 使用 Python 语言。
・ 使用基础搜索算法完成机器人走迷宫。
・ 使用 Deep QLearning 算法完成机器人走迷宫。
・ 算法部分需要自己实现,不能使用现成的包、工具或者接口。
1.3 实验环境
可以使用 Python 实现基础算法的实现, 使用 Keras、PyTorch等框架实现 Deep QLearning 算法。
1.4 参考资料
・ 强化学习入门MDP:https://zhuanlan.zhihu.com/p/25498081
・ QLearning 简单例子(英文):http://mnemstudio.org/path-finding-q-learning-tutorial.htm
・ QLearning 简单解释(知乎):https://www.zhihu.com/question/26408259
・ DeepQLearning 论文:https://files.momodel.cn/Playing%20Atari%20with%20Deep%20Reinforcement%20Learning.pdf
1、 实验核心代码,并附上关键注释
2、 实验结果图
3、 如果使用了大模型,请在此处贴上和大模型的问答记录
a) 使用哪些大模型:
b) 问的问题,按顺序写出:
c) 一共问了几个问题:
d) 和大模型的问答记录:
