论文阅读报告,2023.8.11,郝润泽
近期阅读Attention Is All You Need,此文章提出了Transformer模型
在阅读Attention Is All You Need的同时复习了数个深度学习基本概念,如线性分类器、全连接神经网络,卷积神经网络CNN,循环神经网络RNN,softmax函数sigmoid函数等。


在摘要中总结了Transformer基于注意力机制,摒弃了复杂的循环神经网络和卷积神经网络。该模型在两个机器翻译任务上进行了实验,结果表明它在质量上表现出色,同时更易于并行化,并且训练时间显著缩短。
在WMT 2014年的英德翻译任务中,该模型达到了28.4 BLEU的得分,相较于已有的最佳结果(包括合成模型),提升了超过2 BLEU。
在WMT 2014年的英法翻译任务中,该模型在训练了3.5天的时间、使用八个GPU后,取得了新的单模型最优BLEU得分41.8。
上文提到的注意力机制解释如下:
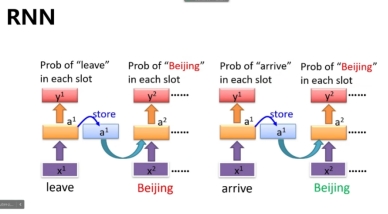
首先,对于普通的RNN,经常存在信息传递长度不够的问题,例如一段话被分词和向量化后,如果第一个词的信息对于第二个词有影响,一般会将第一个词的信息叠加在后面几个词的向量上面。但是RNN存在遗忘机制,在处理一段话中间的某个对后面影响不大的词时,为了避免让这个单词的信息影响后面,可能会将这个词的数据遗忘,但是同时叠加在这个单词上面的以前的单词的信息也一起被遗忘了。
为了解决上述问题,研究人员提出了:LSTM结构,在这个结构中,前面的信息有机会一直传递下去。
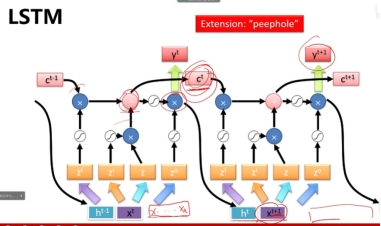
在LSTM结构中,分析一个单词的时候会使用三个门控神经网络决定是否保留此单词的信息以及是否让前面的信息影响这个单词的输出向量。
而为了提供更好地上下文性能,研究人员引入了注意力机制并提出了Transformer结构
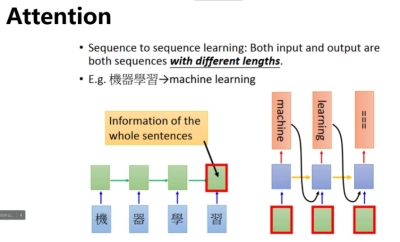
注意力机制使得神经网络在分析每个单词的时候,可以更精准的识别到上下文与这一单词有关的其他单词。
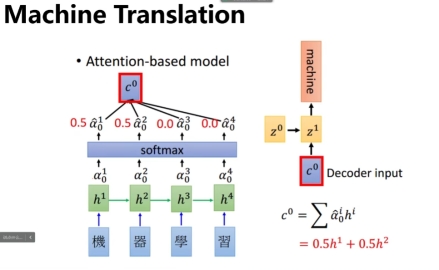
具体的,引入一个经过学习得到的矩阵c0
如上图所示,a向量为每个字的词元向量,在分析“机器学习”这个词的“机”时,使每个a向量与c0相乘,并经过softmax函数处理,得到“机”“器”的相关度为0.5,而“学”“习”的相关度为0,这可以使神经网络更精准的识别到上下文与这一单词有关的其他单词。
下面介绍Transformer模型
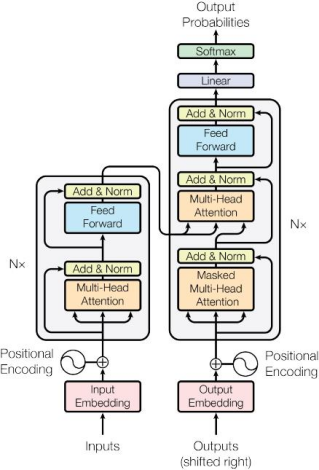
上图为Transformer模型的总体结构,左侧灰色方框为encoder编码器,右侧灰色方框为decoder解码器。这两个部分为Transformer模型的核心。

Encoder的作用是读取输入的向量,并经过计算将数据送入解码器。
上述的输入的向量是由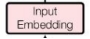 提供的,Input Embedding可以将所有单词的词向量处理成一个512维的向量,这有利于后续的处理和计算。
提供的,Input Embedding可以将所有单词的词向量处理成一个512维的向量,这有利于后续的处理和计算。
处理好的512维的向量会送入位置编码器处理, ,此处主要是将每个单词在语段中的位置进行标记。
,此处主要是将每个单词在语段中的位置进行标记。
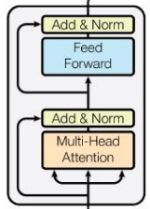
解码器结构
然后向量送入编码器进行处理,首先送入一个Multi-Head Attention(多头注意力)。
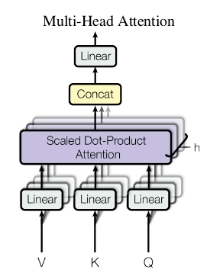
这里多头注意力机制的多头指的是堆叠N个点积注意力机制处理器,文章中采用N=6。
首先每一个单词被线性变换为三个向量,分别是Q向量(query,查询向量),K(key向量),V(value向量)。然后送入点积注意力机制处理器。
每一个点积注意力机制处理器的结构如下:
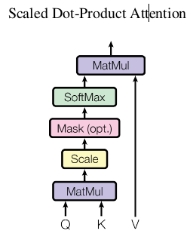
处理过程可以用如下公式表达:
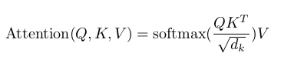
MatMul表示首先将QK相乘,即使用当前单词的Q查询向量去查询每一个其他单词的KEY向量,如果这两个单词的相关性较大,则乘积结果较大,如果这两个单词不相干,则结果也很小。

Scale表示上面的相乘结果除以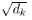 ,这是为了防止数据规模过大。
,这是为了防止数据规模过大。

Mask没有体现在公式里,具体作用为再次筛选不相关的单词,并将不相关的单词赋值一个几乎是负无穷的值。

将上面的结果经过Softmax函数处理,得到每一个单词与当前单词相关性的数据,然后将每个概率乘以每个单词自己的Value向量,得到的结果就是输出。
点积注意力机制处理器到这里介绍完毕。
上述点积注意力机制处理器是多个并行的,文章中使用6个,所以得到6组数据
将6个点积注意力机制处理器得到的数据送入一个Concat函数中,随后再进行一次线性变换就得到最终结果。
上述过程表现为如下公式:


随后将多头注意力机制的结果送入一个Add&Norm层,指将最一开始的词向量与多头注意力机制的结果进行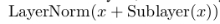 的处理,可以得到每个词的更好地表示。
的处理,可以得到每个词的更好地表示。
Feed Forward层是一个两层的全连接神经网络层中间有一层RELU激活函数。
这里的Feed Forward层有什么作用我并没有从文章中看出来。
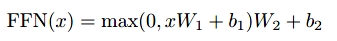
解码器的结构与上述编码器类似,唯一不同就是中间添加一层多头注意力层和Add&Norm层,这两层将编码器的数据和解码器的数据进行处理。
处理后的数据再进行一次线性变换和softmax处理后就得到了最终的输出。
