大语言模型的论文综述
2023.7.2
一 GPT-2模型提出的论文:

在这篇文章中,OPENAI的团队提出了新型的语言模型
1 摘要部分

在摘要中可以体现几点:
1 gpt2本质上是一个十五亿参数的Transformer
2 gpt2采用的是无监督训练方式,而同时期的其他模型普遍采用有监督训练方式
3 gpt2的测试结果很好,在同期的几个基准测试中获得极高的分数。
2训练方法
模型的原理为语言建模
语言建模的本质是使用示例(x1; x2; :::; xn)的无监督分布估计,这里的每一个示例指的是文本数据集中的一条数据,每一个xn由一组由可变长度符号序列(s1; s2; :::; sn)组成。
模型的目标是学习如何预测给定前面的符号序列,下一个符号的概率分布为:

由于语言具有自然的顺序排列,因此通常将符号的联合概率分解为条件概率的乘积
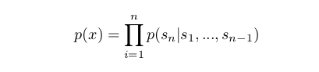

这一段表明,所有的输入和输出都可以表示为符号序列。例如,阅读理解训练示例可以写成(回答问题、文档、问题、答案)的序列。

这里的例子说明,无监督训练方式比有监督的训练方式更有优势,可以规避某些问题(Sutskever, I., Jozefowicz, R., Gregor, K., Rezende, D., Lillicrap,T., and Vinyals, O. Towards principled unsupervised learning.arXiv preprint arXiv:1511.06440, 2015.)。

在训练集方面,之前的工作大多是采用单一的训练集,而Gpt2的训练集名为WebText,他们使整个训练集多样化且尽可能的大。这样做可以使模型更好地适应各种任务,并且具有更广泛的适用性。整个数据集的大小达到了40GB。
3训练结果
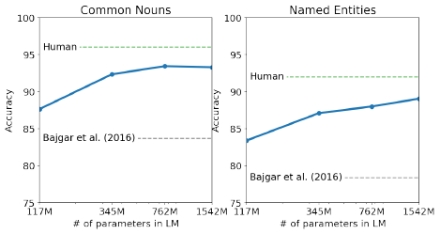
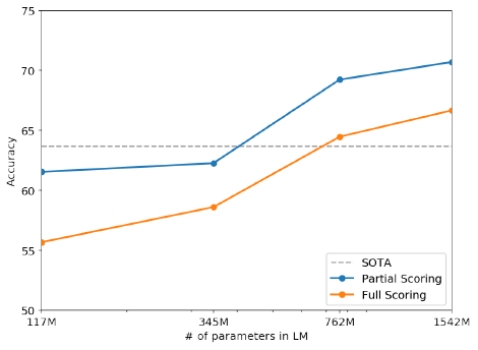
上图表示,模型在Children’s Book Test、LAMBADA、Winograd Schema Challenge三个基准测试系统中表现良好
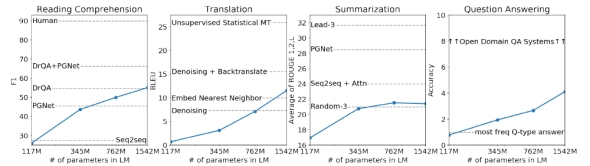
随后测试了在阅读理解、文章总结、翻译和问答四个维度的能力,可以看出,随着模型参数的扩大,魔性的能力有很大提升,不过这时候的GPT2还有很大提升空间
4总结
GPT2提出了一种在当时很新颖的无监督+数量多且多样化的训练样本的训练方式,主要通过提升参数的方式来提升模型的能力,这可以在GPT的发展历史中看到。
二 提出GPT1的论文

看这个文章主要是为了补充一下基础知识,实际上这个成果已经过时,没有什么参考价值。
此时的GPT的参数量为1亿,大小约4G。

1摘要部分
摘要部分提出了生成式语言模型预训练方法(Generative Pre-Training),基于大量的各种未标记文本,进行无监督、生成式预训练,并在每一个具体任务上进行区分性地有监督、判别式微调,可以使得在这些任务上取得很大的改进。
2训练方法
首先,获得无监督的词元U=(u1,u2,...,ui)。设置好文本窗口k(每次可以读几个单词)。设置好神经网络建模的参数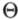 ,这个建模采用随机梯度下降方式。
,这个建模采用随机梯度下降方式。
然后得到目标函数,这里使用最大化似然函数的方法,
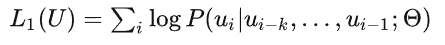
每一层的运算过程:
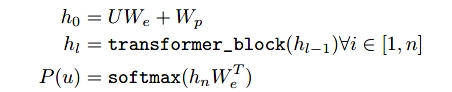
首先,将词元向量U词元嵌入矩阵We和位置编码矩阵相加,得到最初的输入。
然后,对于之后的每一层,将前一层的上述运算结果输入transformer_block中,得到这一层的运算结果。这里的transformer_block是transformer的一种变种。
最后,softmax()函数得到最后结果。
实际上,可以看出,每一个预测出的单词都是由前边的单词计算得出的。
3文本输入时的处理
因为作者想要做出的是能解决所有语言类问题的模型,所有不能在像传统nlp任务一样,限定某一种特定的输入文本和问题,而本文采用的是如下的解决方案。
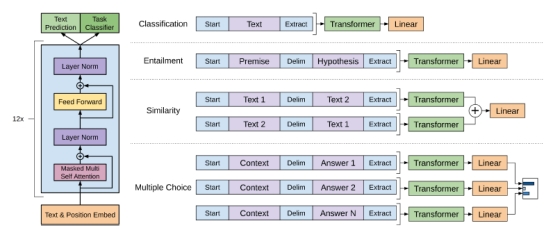
将所有问题分为四种,然后对于每一种问题,使用delim分割符号将输入文本进行分段,最后输入transformer中。
三 提出BERT模型的论文

BERT是谷歌团队开发出的语言模型,它在GPT1之后提出,并且在GPT模型的单向运算基础上提出了双向运算的方法。加强了模型的上下文理解能力。

1 摘要部分
摘要部分主要强调了BERT用于训练非监督下的预训练深度文本信息。在训练的每一层中,都同时计算上文和下文。fine-tuning的方法在这种情况下非常具有局限性,所以BERT通过添加一个额外的输出层进行微调,增强了模型的上下文理解能力。
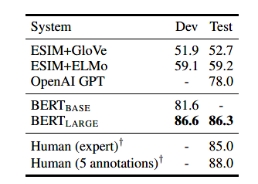
BERT在数个基准测试中,都取得了较好的成绩。
2 训练方法
BERT的训练采用了一种叫做MLM随机屏蔽的方法。在训练过程中输入中的一些token,其目标是仅基于上下文预测屏蔽词的原始词汇表id。与从左到右语言模型预训练不同,MLM能够考虑到融合左右上下文,这使得我们能够预训练深度双向的Transformer。
在pre-training阶段,模型在不同的训练前任务上对未标记的数据进行训练。在fine-tuning阶段,BERT模型首先使用预训练参数进行初始化,然后所有的这些参数使用下游任务中标注好的数据进行微调。每个下游任务都有单独的微调模型,即使它们是用相同的预训练参数初始化的。下图是一个问答示例。
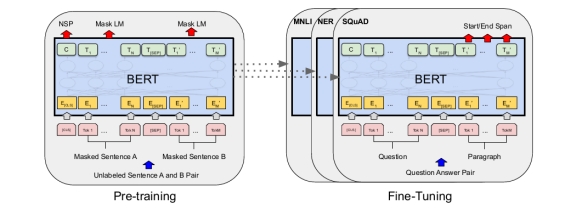
MLM随机屏蔽
这个过程称为“masked LM” (MLM),通过这种方式允许我们获得一个双向的预训练模型,而缺点是在训练前和微调之间产生了不匹配,因为mask token在fine-tuning期间不会出现,为了缓和这一点,作者并不总是用一个实际存在的词来替换被mask的词。训练数据生成器随机选择token position中的15%来进行预测。
3 模型效果
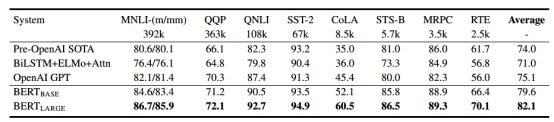
GLUE的测试:
SQuAD1.1 和 SQuAD2.0
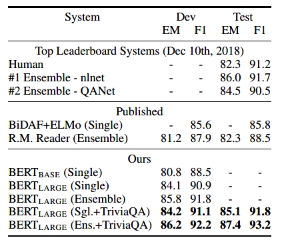
SWAG: